TypeScript算法专题 - 基于TypeScript语言的单链表实现
李俊才
CSDN:jcLee95
邮箱:291148484@163.com
专题目录:https://blog.csdn.net/qq_28550263/article/details/115718216
1. 链表的概念
链表是一种物理存储单元上非连续、非顺序的存储结构,它由一系列结点组成,其特点在于结点可以在运行时动态生成。
链表的存储结构特点
链表的每个结点包括两个部分:
- 一个是存储数据元素的数据域;
- 存储下一个结点地址的指针域。
链表可以用任意一组存储单元来存储其中额数据结构,其存储单元可以是不连续的。
单链表
链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起构成单链表。单链表即单向链表,单向指的是其指针域所存储的信息只能为一个方向。具体来说,单链表中的每个存储单元中,除了需要存储每个单元的数据外,还必须附带储存其直接后继存储单元的地址信息。如图所示:

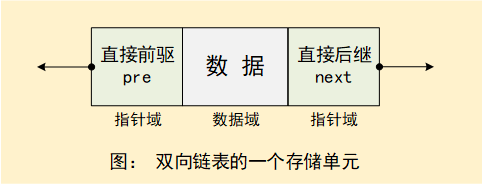
双向链表
它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。
循环链表
循环的最后一个结点指向头结点从而形成一个环。可想而知,从循环链表中的任何一个结点出发都能找到任何其他结点。
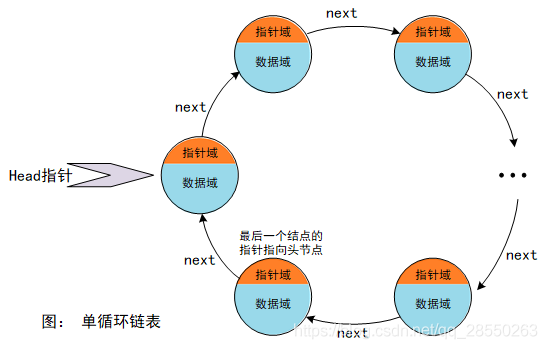
循环单链表
尾元结点的后继指针指向表中的首元结点。其特点为:
- 其每个结点都处于一个循环链中,可以从任何一个位置开始,按照后继方向遍历整个链表。
- 其在合并与分裂时,若非必须从链表头节点开始,可直接在链表指针处进行合并,时间复杂度可达O(1)。
循环双链表
其每个结点包含两个指针指向直接前驱和直接后继,可以在两个方向上遍历某个结点之后以及之前的元素。循环双链表的特点为:
- 每个几点处于2个链中:1为后继方向的循环链链,2为前驱方向的循环链。
- 从某个结点出发进到直接前驱或者直接后继节点,时间复杂度均为O(1)。
- 查找第i个节点、删除第i个节点、在第i个节点处插入,都需要区分时哪一个方向。
- 修改指针要同时考虑在前驱循环链和后继循环链上的修改。
- 某个节点的
直接前驱的直接后继或其直接后继的直接前驱都是该节点本身。
静态链表
用一维数组来进行描述的一种链表,它利益数组下标号来访问下一个节点,因此需要定义一个足够大的节点数组。
概念归纳
| 概念名 | 释义 |
|---|
| 节点 | 是链表中的一个存储单元,其包含一块数据存储区域和一块后继信息存储区域 |
| 链表 | 由n个链表单元(节点)连接在一起的存储结构 |
| 首元节点 | 线性链表中第一个元素结点 |
| 尾元节点 | 线性链表中最后一个元素结点 |
| 头节点 | 若链表存在头节点,头节点即链表的第一个节点 |
| 头指针 | 有头单链表的头节点,其指针永远指向链表中头节点的位置 |
| 单链表 | 节点只包含其后继节点信息的链表 |
| 双向链表 | 节点中都有两个指针,分别指向直接后继和直接前驱 |
| 循环链表 | 最后一个结点指向头结点,形成一个环 |
链
表
{
链
表
带
有
【
头
结
点
】
:
{
表
头
指
针
指
示
头
节
点
头
节
点
链
接
指
针
指
示
首
元
结
点
链
表
没
有
【
头
节
点
】
:
表
头
指
针
指
示
首
元
结
点
链表 \begin{cases} 链表带有【头结点】:\begin{cases}\pmb{表头指针}指示\pmb{头节点}\\\pmb{头节点链接指针}指示\pmb{首元结点}\end{cases}\\ 链表没有【头节点】:\pmb{表头指针}指示\pmb{首元结点} \end{cases}
链表??????链表带有【头结点】:{表头指针表头指针表头指针指示头节点头节点头节点头节点链接指针头节点链接指针头节点链接指针指示首元结点首元结点首元结点?链表没有【头节点】:表头指针表头指针表头指针指示首元结点首元结点首元结点?
单链表进行插入和删除操作实际上不需要移动数据元素,只需要修改相关指针。
在TypeScript语言中并没有C和C++中那样指针的概念以用过指针的相关操作带出数据,我们只能来模拟这个过程。
与线性表/顺序表相比
由于链表不必须按顺序存储,它在插入的时候可以达到O(1)的复杂度,比线性表和顺序表(时间复杂度O(n))快得多。但是链表查找一个节点或者访问特定编号的节点却需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
2. 单链表的TypeScript语言实现
2.1 单链表的节点
链表是由一个一个节点通过某种关系建立关联构成的一种数据结构,单链表也是如此。单链表中的所有节点只有一个指向各自直接后继节点的指针域以及各自的数据域:
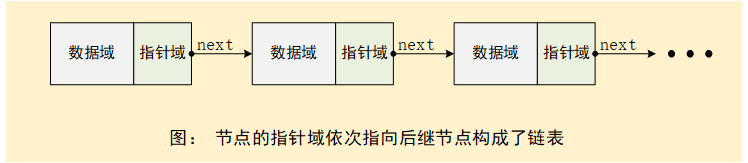
一个最基本的单链表节点看起来是这个样子的:
class Lnode{
next: Lnode | null;
data: any;
constructor(data:any){
this.data = data;
this.next = null;
}
};
2.2 单链表的基本操作:
2.2.1 增
增指的是为该单链表增添节点。增加元素的方法有很多,如:
pop_left:从链表左端(头)开始增加节点;pop:从链表右端(尾)开始增加;insert:从中间的某个(索引号)位置开始增加;p_insert:在指向链表中的某个指针pointer后面的位置插入新节点;
2.2.2 删
删指的是从链表中删除元素。删的方法同样有很多,比如:
del(index):按照节点的索引号删除链表中的单个节点;drop(index):按照索引号删除链表中某个节点及其之后所有节点;drop(a,b):给定两个索引号a和b,删除从[a,b]的一段节点;clear:删除链表中的所有节点使之成为一个空链表。
2.2.3 改
对链表改是指对链表的节点的内容进行更改。比如:
replace:依据节点的索引值将链表中的某一个节点替换成新的节点;reverse:使链表中的所有节点进行反转。
2.2.4 查
查的最终目的是为了获取链表中的节点元素。我们知道,单链表中的一个节点包含一个指向节点后继的指针域以及一个存储节点数据的数据域,也就是查在很多情况下是为了获取数据域中的信息。不过也不全是,不如当我们指向查看以下链表是否有节点,这时只要查某个域指针是否指向了一个节点。将要实现的与此有关的功能包括:
is_empty:查看头链指针是否为空以判断链表是否为空;top:查看链表头节点的数据内容;
2.3 单链表抽象数据结构
以下是接下来我们在本文以及后续的几篇博客中,基于增删改查将要逐个实现的数据结构。
ADT LinkList{
init(id, name) # 初始化(构造)单链表
is_empty() # 判断单链表是否为空
top() # 获取链表的头部节点
clear() # 清空链表
del(index) # 从中间删除索引为`index`的一个节点
drop(index) # 删除索引为`i`节点及其之后的所有节点
drop(index_1,index_2) # 删除从索引为`index_1`(包含)开始到索引为`index_2`(包含)的一段节点
append(node) # 在链表的最右端嵌入一个新的节点node
append_left(node) # 在链表的最左端嵌入新的节点node
insert(index, node) # 在链表的第`index`个节的位置挂载新的节点`node`
p_insert(pointer) # 在指向链表中的某个指针pointer后面的位置插入新节点
pop() # 弹出链表尾部节点
pop_left() # 弹出链表头节点并返回
toArray() # 获取链表节点依次构成的数组,可以方便用于链表的遍历和后续利用数组随机取值
reverse() # 反转链表,直接将原链表反转而不返回值
getReverse() # 反转链表,返回反转后的链表,不改变原链表
}
2.4 使用TypeScript语言实现一个单链表:
本章(博客)实现一个具有判空、查头、增加节点、转为节点数组功能的简单的单链表。在本专题的后续博客中,将会逐步实现上面提到的其它功能。
这部分的ADT如下:
ADT LinkList{
init(id, name) # 初始化(构造)单链表
is_empty