
�ı��ִʡ����Ա�ע������ʵ��ʶ������Ȼ���Դ�����������ܻ���������,���ǵľ��Ⱦ�������������ľ���,�����ڲ����ϵ�ʱ������䷢����һ���ܺ���Ŀ�Դ��Ŀ,�������һ�²�֪�����ǰٶȿ�Դ��һ����Ҫ���ڴ��Ա�ע������ʵ��ʶ�����Ŀ,������������һ�¡�
��������Ŀ���������ð�װ,��ǰ�Ѿ�֧��һ��ʽ��װ��,��������������ʾ:
python?-m?pip?install?LAC
����һ�°�װ��֤,�ɹ���ͼ������ʾ:
�������Ϳ��Խ���ʹ����,�ٷ�GitHub��ַ������https://github.com/baidu/lac���ٷ���������һЩ����������ʾ:
���߽���
LACȫ��Lexical Analysis of Chinese,�ǰٶ���Ȼ���Դ������з���һ�����ϵĴʷ���������,ʵ�����ķִʡ����Ա�ע��ר��ʶ��ȹ��ܡ��ù��߾��������ص�������:
Ч����:ͨ�����ѧϰģ������ѧϰ�ִʡ����Ա�ע��ר��ʶ������,����Ч��F1ֵ����0.91,���Ա�עF1ֵ����0.94,ר��ʶ��F1ֵ����0.85,Ч��ҵ�����ȡ�
Ч�ʸ�:����ģ�Ͳ���,���PaddleԤ���������Ż�,CPU���߳����ܴ�800QPS,Ч��ҵ�����ȡ�
�ɶ���:ʵ�ּɿصĸ�Ԥ����,��ƥ���û��ʵ��ģ�ͽ��и�Ԥ���ʵ�֧�ֳ�Ƭ����ʽ,ʹ�ø�Ԥ��Ϊ����
���ñ��:֧��һ����װ,ͬʱ�ṩ��Python��Java��C++���ýӿ������ʾ��,ʵ�ֿ��ٵ��úͼ��ɡ�
֧���ƶ���: ���Ƴ�������ģ��,�����Ϊ2M,����ǧԪ�ֻ����߳����ܴ�200QPS,���������ƶ���Ӧ�õ�����,ͬ���������Ч��ҵ�����ȡ�
��װ��ʹ��
�ڴ�������Ҫ����Python��װ��ʹ��,��������ʹ��:
C++
JAVA
Android
��װ˵��
�������Python2/3
ȫ�Զ���װ: pip install lac
���Զ�����:������http://pypi.python.org/pypi/lac/,��ѹ������python setup.py install
��װ��ɺ��������������lac��lac --segonly��������,���п�������
���������ʹ�ðٶ�Դ��װ,��װ���ʸ���:pip install lac -i https://mirror.baidu.com/pypi/simple
������ʹ��
�ִ�
����ʾ��:
from?LAC?import?LAC
?
#?װ�طִ�ģ��
lac?=?LAC(mode='seg')
?
#?������������,����ΪUnicode������ַ���
text?=?u"LAC�Ǹ�����ķִʹ���"
seg_result?=?lac.run(text)
?
#?������������,?����Ϊ���������ɵ�list,ƽ�����ʻ����
texts?=?[u"LAC�Ǹ�����ķִʹ���",?u"�ٶ���һ�Ҹ߿Ƽ���˾"]
seg_result?=?lac.run(texts)
���:
����������:seg_result = [LAC, ��, ��, ����, ��, �ִ�, ����]
������������:seg_result = [[LAC, ��, ��, ����, ��, �ִ�, ����], [�ٶ�, ��, һ��, �߿Ƽ�, ��˾]]
���Ա�ע��ʵ��ʶ��
����ʾ��:
from?LAC?import?LAC
?
#?װ��LACģ��
lac?=?LAC(mode='lac')
?
#?������������,����ΪUnicode������ַ���
text?=?u"LAC�Ǹ�����ķִʹ���"
lac_result?=?lac.run(text)
?
#?������������,?����Ϊ���������ɵ�list,ƽ�����ʸ���
texts?=?[u"LAC�Ǹ�����ķִʹ���",?u"�ٶ���һ�Ҹ߿Ƽ���˾"]
lac_result?=?lac.run(texts)
���:
ÿ�����ӵ�������дʽ��word_list�Լ���ÿ�����ʵı�עtags_list,���ʽΪ(word_list, tags_list)
����������:lac_result =?([�ٶ�, ��, һ��, �߿Ƽ�, ��˾], [ORG, v, m, n, n])
������������:lac_result =?[
????????????????????([�ٶ�,?��,?һ��,?�߿Ƽ�,?��˾],?[ORG,?v,?m,?n,?n]),
????????????????????([LAC,?��,?��,?����,?��,?�ִ�,?����],?[nz,?v,?q,?a,?u,?n,?n])
????????????????]
���Ժ�ר������ǩ�������±�,�������ǽ���õ�4��ר�������Ϊ��д����ʽ:
��ǩ?����?��ǩ?����?��ǩ?����?��ǩ?����
n?��ͨ����?f?��λ����?s?��������?nw?��Ʒ��
nz?����ר��?v?��ͨ����?vd?������?vn?������
a?���ݴ�?ad?���δ�?an?���δ�?d?����
m?������?q?����?r?����?p?���
c?����?u?����?xc?�������?w?������
PER?����?LOC?����?ORG?������?TIME?ʱ��
���ƻ�����
��ģ������Ļ�����,LAC��֧���û����ö��ƻ����зֽ����ר�������������ģ��Ԥ��ƥ�䵽�ʵ���е�itemʱ,���ö��ƻ��Ľ�����ԭ�н����Ϊ��ʵ�ָ��Ӿ�ȷ��ƥ��,����֧�����ɶ��������ɵij�Ƭ����Ϊһ��item��
����ͨ��װ�شʵ��ļ�����ʽʵ�ָù���,�ʵ��ļ�ÿ�б�ʾһ�����ƻ���item,��һ�����ʻ��������ĵ������,ÿ�����ʺ�ʹ��'/'��ʾ��ǩ,���û��'/'��ǩ���ʹ��ģ��Ĭ�ϵı�ǩ��ÿ��item������Խ��,��ԤЧ����Խ����
�ʵ��ļ�ʾ��
�������Ϊʾ��,չ�ָ�����������µĽ������������������ͨ������ôʵ��ģʽ,�����ڴ���
����/SEASON
��/n?��/v
����ķ�
��?��
����ʾ��
from?LAC?import?LAC
lac?=?LAC()
?
#?װ�ظ�Ԥ�ʵ�
lac.load_customization('custom.txt')
?
#?��Ԥ����
custom_result?=?lac.run(u"����Ļ�������ķ��Լ����������")
�����롰����Ļ�������ķ��Լ������������Ϊ��,ԭ��������Ϊ:
����/TIME?��/u?����/v?����/TIME?��/u?��/n?�Լ�/c?����/TIME?��/u?����/n
����ʾ���еĴʵ��ļ���Ľ��Ϊ:
����/SEASON?��/u?��/n?��/v?����ķ�/n?�Լ�/c?����/TIME?��/u?��/n?��/n
����ѵ��
����Ҳ�ṩ������ѵ���Ľӿ�,�û�����ʹ���Լ�������,��������ѵ��,������Ҫ������ת��Ϊģ������ĸ�ʽ,�������������ļ���Ϊ"UTF-8"����:
�ִ�ѵ��
��������
��������Դ�ִ����ݼ���ʽһ��,ʹ�ÿո���Ϊ�����зֱ��,������ʾ:
LAC ��?��?����?��?�ִ�?����?��
�ٶ�?��?һ��?�߿Ƽ�?��˾?��
����?��?����?����?��?��?�Լ�?����?��?����?��
����ʾ��
from?LAC?import?LAC
?
#?ѡ��ʹ�÷ִ�ģ��
lac?=?LAC(mode?=?'seg')
?
#?ѵ���Ͳ������ݼ�,��ʽһ��
train_file?=?"./data/seg_train.tsv"
test_file?=?"./data/seg_test.tsv"
lac.train(model_save_dir='./my_seg_model/',train_data=train_file,?test_data=test_file)
?
#?ʹ���Լ�ѵ���õ�ģ��
my_lac?=?LAC(model_path='my_seg_model')
�ʷ�����ѵ��
��������
�ڷִ����ݵĻ�����,ÿ�������ԡ�/type������ʽ�������Ի�ʵ�����ֵ��ע�����,�ʷ�������ѵ��Ŀǰ��֧�ֱ�ǩ��ϵ������һ�µ����ݡ�����Ҳ�Ὺ��֧���µı�ǩ��ϵ,�����ڴ���
LAC/nz ��/v ��/q ����/a ��/u �ִ�/n ����/n ��/w
�ٶ�/ORG ��/v һ��/m �߿Ƽ�/n ��˾/n ��/w
����/TIME ��/u ����/v ����/TIME ��/u ��/n �Լ�/c ����/TIME ��/u ����/n ��/w
����ʾ��
from?LAC?import?LAC
?
#?ѡ��ʹ��Ĭ�ϵĴʷ�����ģ��
lac?=?LAC()
?
#?ѵ���Ͳ������ݼ�,��ʽһ��
train_file?=?"./data/lac_train.tsv"
test_file?=?"./data/lac_test.tsv"
lac.train(model_save_dir='./my_lac_model/',train_data=train_file,?test_data=test_file)
?
#?ʹ���Լ�ѵ���õ�ģ��
my_lac?=?LAC(model_path='my_lac_model')
������,���ǻ����Լ������ݼ�����дһЩ����˼�Ĺ���,��ʵ��������ʵ��ʶ���ʱ����ͻȻ�뵽,���ģ����Դ����˹��Զ������б�ע�����ݼ�����NERģ�͵�ѵ��,��Ȼ�������Զ����ɵ����ݼ������Dz�ȷ��,������ȷ��,��Ҫ�����ʡ�˹���ע�ijɱ���
�����Ǽ��ر������ݼ�,����ʵ��������ʾ:
def?loadData(data='toutiao_news_dataset.txt'):
????'''
????���ر������ݼ�
????'''
????with?open(data,encoding='utf-8')?as?f:
????????data_list=[one.strip().split('#')?for?one?in?f.readlines()?if?one.strip()]
????print('data_list_length:?',len(data_list))
????for?i?in?range(10):
????????print('index:?'+str(i)+',?content:?'+data_list[i][-1])
????return?data_list
���ݼ���������������ʾ:
����#������������������������������������������
����#������������������������������������������
����#������������������������������������������
����#������������������������������������������
����#������������������������������������������
����#������������������������������������������
���ڹٷ��������,��������ݼ������滻����ʡ�Ժš�
���������������ѡ���ݼ���������ʵ��ʶ��,����ʵ��������ʾ:
def?NERModel(data_list):
????'''
????���Ա�ע������ʵ��ʶ��
????���ʵ��:
?????????????[['����',?'��',?'ֵ��',?'��',?'��',?'��',?'�Ļ�',?'֮',?'��',?'��',?'�����'],?['nz',?'d',?'v',?'r',?'v',?'q',?'n',?'u',?'n',?'u',?'n']]
????'''
????lac?=?LAC(mode='lac')
????texts?=?[one[-1]?for?one?in?data_list]
????lac_result?=?lac.run(texts)
????for?i?in?range(10):
????????print('index:?',str(i),',?lac_result:?',lac_result[i])
????????words,?tags?=?lac_result[i]
????????print(u"?".join(u"%s/%s"?%?(word,?tag)?for?word,?tag?in?zip(words,?tags)))
????????print('====================================================================')
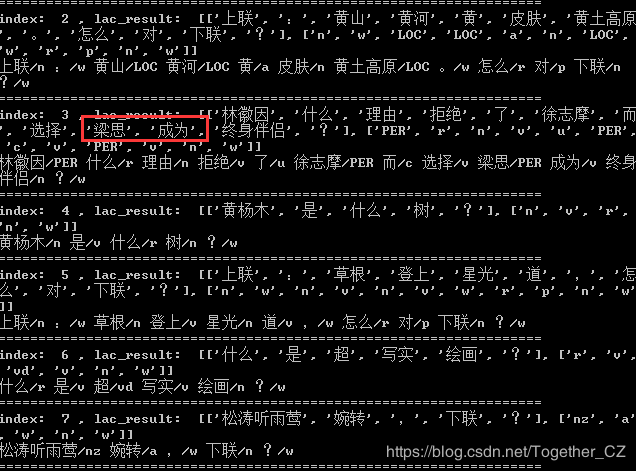
���������ʾ:
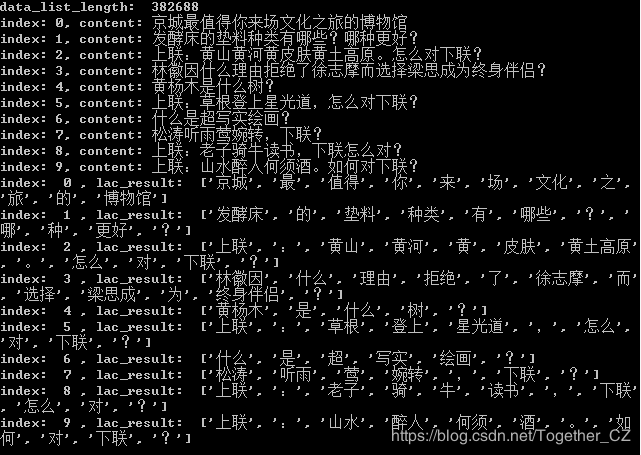
data_list_length:??382688
index:?0,?content:?������ֵ���������Ļ�֮�õIJ����
index: 1, content:?���ʹ��ĵ�����������Щ?���ָ���?
index: 2, content:?����:��ɽ�ƺӻ�Ƥ��������ԭ����ô������?
index: 3, content:?�ֻ���ʲô���ɾܾ�����־Ħ��ѡ����˼��Ϊ��������?
index: 4, content:?����ľ��ʲô��?
index: 5, content:?����:�ݸ������ǹ��,��ô������?
index: 6, content:?ʲô�dz�дʵ�滭?
index: 7, content:?��������ݺ��ת,����?
index: 8, content:?����:������ţ����,������ô��?
index: 9, content:?����:ɽˮ���˺���ơ���ζ�����?
index:??0?,?lac_result:??[['����',?'��',?'ֵ��',?'��',?'��',?'��',?'�Ļ�',?'֮',
?'��',?'��',?'�����'],?['nz',?'d',?'v',?'r',?'v',?'q',?'n',?'u',?'n',?'u',?'n']
]
����/nz?��/d?ֵ��/v?��/r?��/v?��/q?�Ļ�/n?֮/u?��/n?��/u?�����/n
====================================================================
index:??1?,?lac_result:??[['���ʹ�',?'��',?'����',?'����',?'��',?'��Щ',?'?',?'
��',?'��',?'����',?'?'],?['nz',?'u',?'n',?'n',?'v',?'r',?'w',?'r',?'q',?'a',?'w
']]
���ʹ�/nz ��/u ����/n ����/n ��/v ��Щ/r ?/w ��/r ��/q ����/a ?/w
====================================================================
index:??2?,?lac_result:??[['����',?':',?'��ɽ',?'�ƺ�',?'��',?'Ƥ��',?'������ԭ
',?'��',?'��ô',?'��',?'����',?'?'],?['n',?'w',?'LOC',?'LOC',?'a',?'n',?'LOC',
'w',?'r',?'p',?'n',?'w']]
����/n :/w ��ɽ/LOC �ƺ�/LOC ��/a Ƥ��/n ������ԭ/LOC ��/w ��ô/r ��/p ����/n
?/w
====================================================================
index:??3?,?lac_result:??[['�ֻ���',?'ʲô',?'����',?'�ܾ�',?'��',?'��־Ħ',?'��
',?'ѡ��',?'��˼',?'��Ϊ',?'��������',?'?'],?['PER',?'r',?'n',?'v',?'u',?'PER',
?'c',?'v',?'PER',?'v',?'n',?'w']]
�ֻ���/PER?ʲô/r?����/n?�ܾ�/v?��/u?��־Ħ/PER?��/c?ѡ��/v?��˼/PER?��Ϊ/v?����
����/n ?/w
====================================================================
index:??4?,?lac_result:??[['����ľ',?'��',?'ʲô',?'��',?'?'],?['n',?'v',?'r',
'n',?'w']]
����ľ/n ��/v ʲô/r ��/n ?/w
====================================================================
index:??5?,?lac_result:??[['����',?':',?'�ݸ�',?'����',?'�ǹ�',?'��',?',',?'��
ô',?'��',?'����',?'?'],?['n',?'w',?'n',?'v',?'n',?'v',?'w',?'r',?'p',?'n',?'w'
]]
����/n :/w �ݸ�/n ����/v �ǹ�/n ��/v ,/w ��ô/r ��/p ����/n ?/w
====================================================================
index:??6?,?lac_result:??[['ʲô',?'��',?'��',?'дʵ',?'�滭',?'?'],?['r',?'v',
?'vd',?'v',?'n',?'w']]
ʲô/r ��/v ��/vd дʵ/v �滭/n ?/w
====================================================================
index:??7?,?lac_result:??[['��������ݺ',?'��ת',?',',?'����',?'?'],?['nz',?'a'
,?'w',?'n',?'w']]
��������ݺ/nz ��ת/a ,/w ����/n ?/w
====================================================================
index:??8?,?lac_result:??[['����',?':',?'����',?'��',?'ţ',?'����',?',',?'����
',?'��ô',?'��',?'?'],?['n',?'w',?'n',?'v',?'n',?'v',?'w',?'n',?'r',?'p',?'w']]
?
����/n :/w ����/n ��/v ţ/n ����/v ,/w ����/n ��ô/r ��/p ?/w
====================================================================
index:??9?,?lac_result:??[['����',?':',?'ɽˮ����',?'����',?'��',?'��',?'���',
?'��',?'����',?'?'],?['n',?'w',?'n',?'v',?'n',?'w',?'r',?'p',?'n',?'w']]
����/n :/w ɽˮ����/n ����/v ��/n ��/w ���/r ��/p ����/n ?/w
====================================================================
�������Ƿ�����һ�������ԵĴ���:
��˼��,���Ƕ�֪����һ������,���ﱻ��ֿ���,Ҳ����ʶ�������,���ǿ����Զ���ʵ���ֵ���������������,����ʵ��������ʾ:
def?NERModel(data_list):
????'''
????���Ա�ע������ʵ��ʶ��
????���ʵ��:
?????????????[['����',?'��',?'ֵ��',?'��',?'��',?'��',?'�Ļ�',?'֮',?'��',?'��',?'�����'],?['nz',?'d',?'v',?'r',?'v',?'q',?'n',?'u',?'n',?'u',?'n']]
????'''
????lac?=?LAC(mode='lac')
????lac.load_customization('mydict.txt')
????texts?=?[one[-1]?for?one?in?data_list]
????lac_result?=?lac.run(texts)
????for?i?in?range(10):
????????print('index:?',str(i),',?lac_result:?',lac_result[i])
????????words,?tags?=?lac_result[i]
????????print(u"?".join(u"%s/%s"?%?(word,?tag)?for?word,?tag?in?zip(words,?tags)))
????????print('====================================================================')
����mydict.txt����������ʾ:
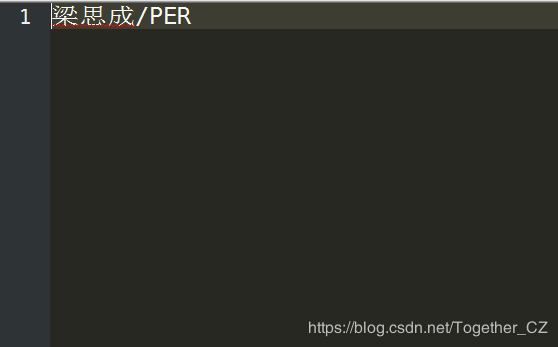
������������������ִ�н��:
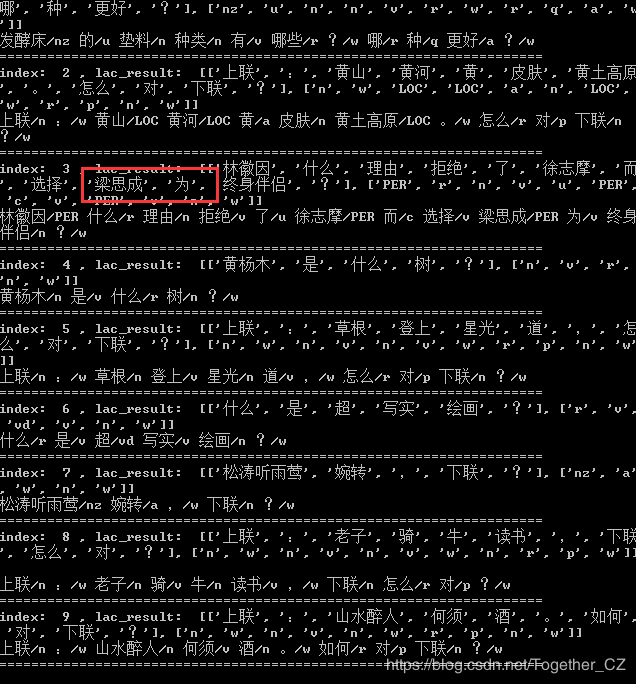
���Կ���:��˼����������Ѿ���ȷʶ������ˡ�
����������ʵ��һ�·ִʹ���,����ʵ��������ʾ:
def?cutModel(data_list):
????'''
????�ִ�
????���ʵ��:
????????????['����',?'��',?'ֵ��',?'��',?'��',?'��',?'�Ļ�',?'֮','��',?'��',?'�����']
????'''
????lac?=?LAC(mode?=?'seg')
????texts?=?[one[-1]?for?one?in?data_list]
????lac_result?=?lac.run(texts)
????for?i?in?range(10):
????????print('index:?',str(i),',?lac_result:?',lac_result[i])
���Խ�����������ʾ:
������˵,��װ���ú�ʹ��ʵ�����ܼ�,�����������ʵ��ʶ�������������Զ����ݼ���
����:��ˮ����,CSDN����ר��,�����о�����:����ѧϰ�����ѧϰ��NLP��CV
Blog:?http://yishuihancheng.blog.csdn.net
�� �� �� ��

Python����������Ϊһ��ȥ���Ļ���ȫ��������,�Գ�Ϊȫ��20��Python���Ŀ����ߵľ�����ΪԸ��,Ŀǰ���Ǹ�������ý���Э��ƽ̨,�밢���Ѷ���ٶȡ���������ѷ����Դ�й���CSDN��ҵ��֪����˾�ͼ������������˹㷺����ϵ,ӵ������ʮ������Һ͵����������Ǽǻ�Ա,��Ա�����Թ��Ų����廪��ѧ��������ѧ�������ʵ��ѧ���й��������С��п�Ժ���н𡢻�Ϊ��BAT���ȸ衢����Ϊ�������������ء����е�λ�����ڻ����Լ�������֪����˾,ȫƽ̨��20���߹�ע��

�Ƽ��Ķ�:
һ�Ķ����߲�������µij�����������
�� Django ����������̫�����ܺ�Լ�� DApp
һ�Ķ��� Python �ֲ�ʽ������� celery
5 ���ӽ�� Python �е���ʽ����
�� Python ����һ�����رҼ۸�Ԥ��Ӧ��

�������Ϊ������Ա? ?ϲ���͵���ڿ���
cs