�ؼ����ҵ���Ļ��URL
�ȴ�,������,����F12
��Ctrl+Rˢ��
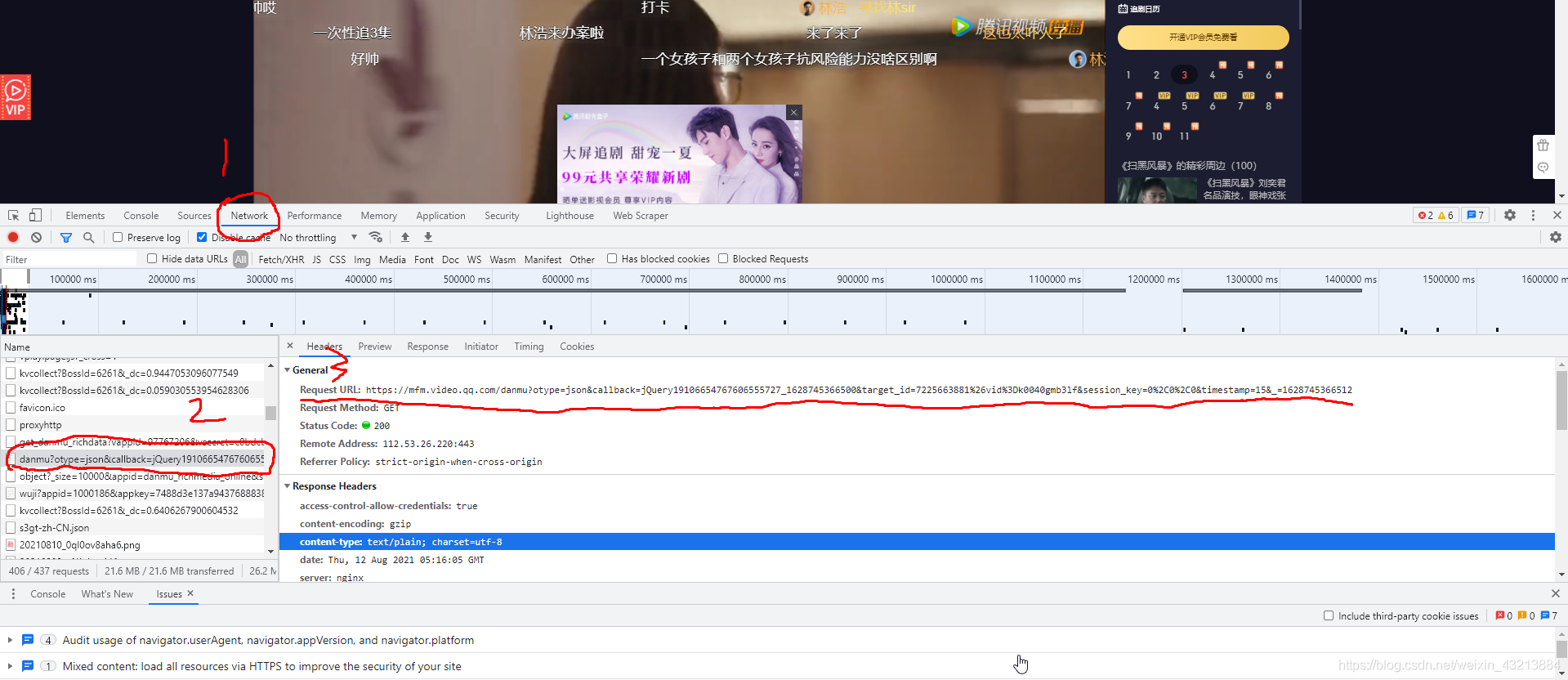
��������
import requests
import json
import time
import pandas as pd
df = pd.DataFrame()
for page in range(15, 45, 30):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = 'https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id=5938032297%26vid%3Dx0034hxucmw&count=80'.format(page)
print("������ȡ��" + str(page) + "ҳ")
html = requests.get(url,headers = headers)
print(html)
bs = json.loads(html.text.encode('utf-8').decode('utf-8'),strict = False)
time.sleep(1)
print(bs)
for i in bs['comments']:
content = i['content']
upcount = i['upcount']
user_degree =i['uservip_degree']
timepoint = i['timepoint']
comment_id = i['commentid']
cache = pd.DataFrame({'��Ļ':[content],'��Ա�ȼ�':[user_degree],
'����ʱ��':[timepoint],'��Ļ����':[upcount],'��Ļid':[comment_id]})
df = pd.concat([df,cache])
df.to_csv('tengxun_danmu.csv',encoding = 'utf-8-sig')
print(df.shape)
cs