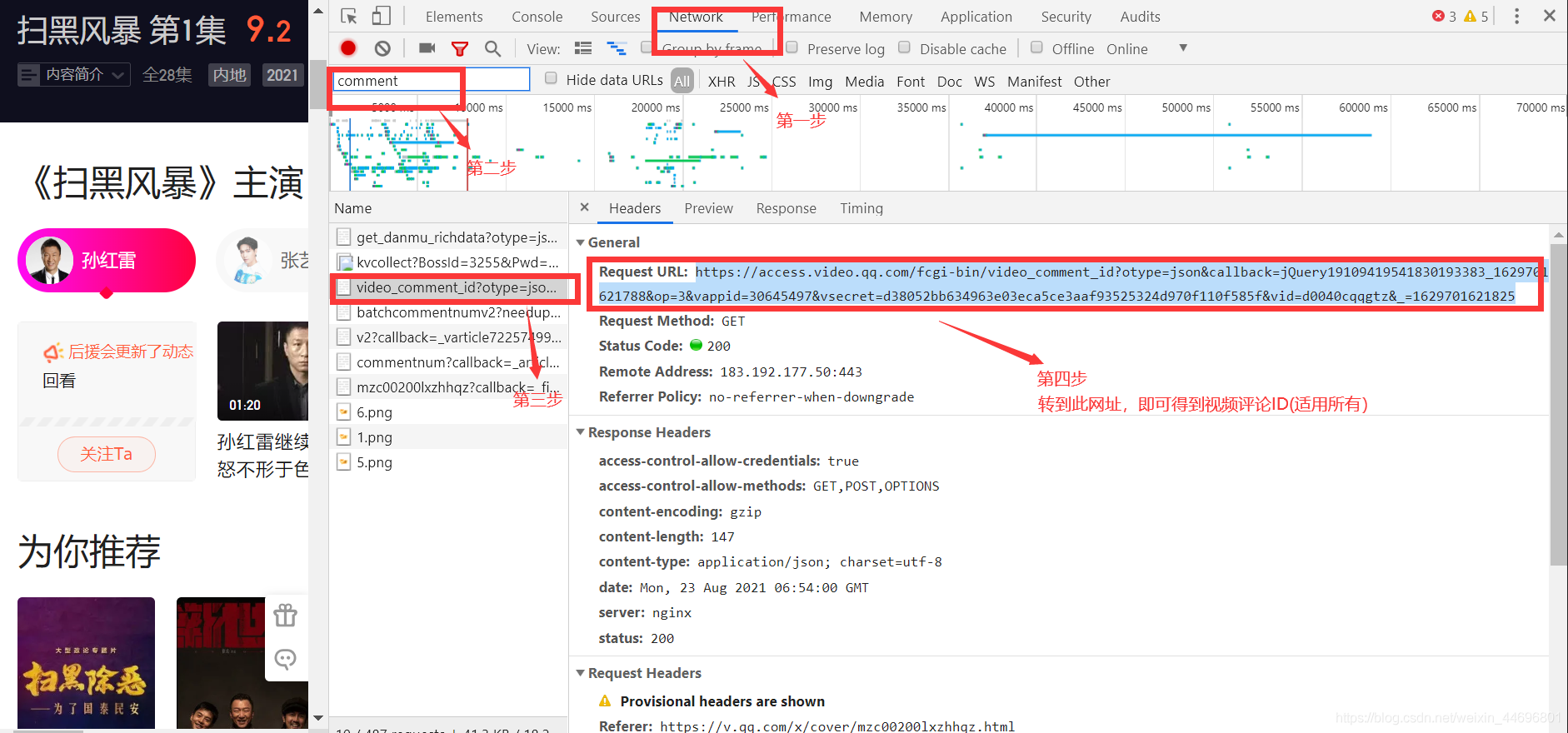
�����Ƕ���Ѷ�Ȳ��硪��ɨ�ڷ籩��һ�����������ݷ���,��ʱ����Сʱ,����ȡ����3W������,������˵�Ƚ���ͨ,ֵ��ע���һ�������۵������ı���������,���ǵ�һ�νӴ���֪ʶ��
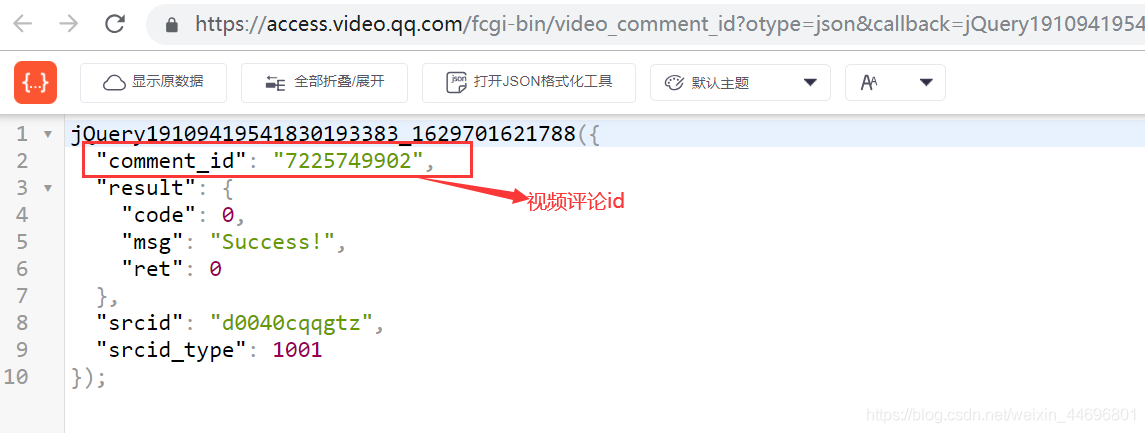
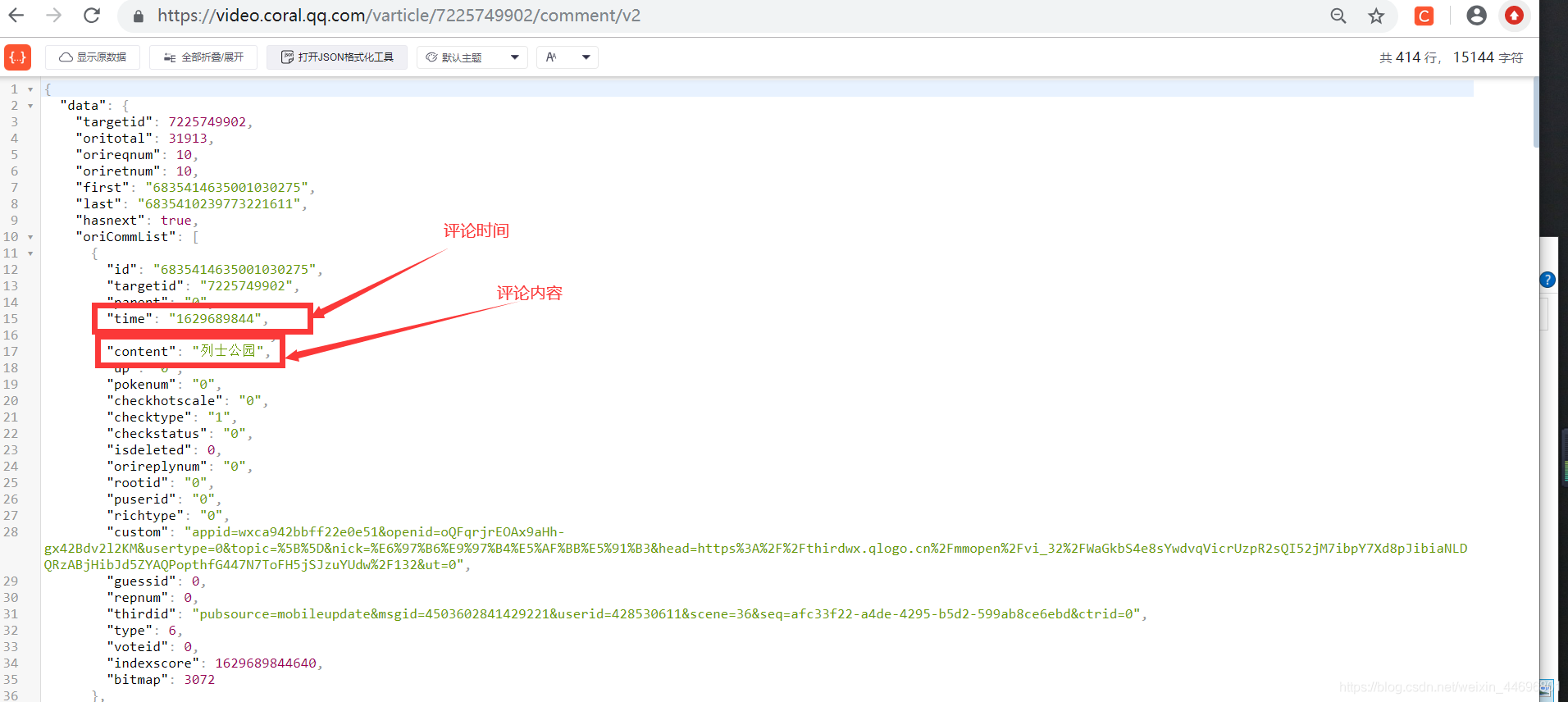
���淽��:������Ѷ�����������Ƿ�װ��json����,����ֻ��Ҫ�ҵ�json�ļ�,����Ҫ�����ݽ�����ȡ���漴�ɡ�
import requests
import re
import random
def get_html(url, params):
uapools = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14'
]
thisua = random.choice(uapools)
headers = {"User-Agent": thisua}
r = requests.get(url, headers=headers, params=params)
r.raise_for_status()
r.encoding = r.apparent_encoding
r.encoding = 'utf-8'
return r.text
def parse_page(infolist, data):
commentpat = '"content":"(.*?)"'
lastpat = '"last":"(.*?)"'
commentall = re.compile(commentpat, re.S).findall(data)
next_cid = re.compile(lastpat).findall(data)[0]
infolist.append(commentall)
return next_cid
def print_comment_list(infolist):
j = 0
for page in infolist:
print('��' + str(j + 1) + 'ҳ\n')
commentall = page
for i in range(0, len(commentall)):
print(commentall[i] + '\n')
j += 1
def save_to_txt(infolist, path):
fw = open(path, 'w+', encoding='utf-8')
j = 0
for page in infolist:
commentall = page
for i in range(0, len(commentall)):
fw.write(commentall[i] + '\n')
j += 1
fw.close()
def main():
infolist = []
vid = '7225749902';
cid = "0";
page_num = 3000
url = 'https://video.coral.qq.com/varticle/' + vid + '/comment/v2'
for i in range(page_num):
params = {'orinum': '10', 'cursor': cid}
html = get_html(url, params)
cid = parse_page(infolist, html)
print_comment_list(infolist)
save_to_txt(infolist, 'content.txt')
main()
2.��ȡ����ʱ�����:sp.py
import requests
import re
import random
def get_html(url, params):
uapools = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14'
]
thisua = random.choice(uapools)
headers = {"User-Agent": thisua}
r = requests.get(url, headers=headers, params=params)
r.raise_for_status()
r.encoding = r.apparent_encoding
r.encoding = 'utf-8'
return r.text
def parse_page(infolist, data):
commentpat = '"time":"(.*?)"'
lastpat = '"last":"(.*?)"'
commentall = re.compile(commentpat, re.S).findall(data)
next_cid = re.compile(lastpat).findall(data)[0]
infolist.append(commentall)
return next_cid
def print_comment_list(infolist):
j = 0
for page in infolist:
print('��' + str(j + 1) + 'ҳ\n')
commentall = page
for i in range(0, len(commentall)):
print(commentall[i] + '\n')
j += 1
def save_to_txt(infolist, path):
fw = open(path, 'w+', encoding='utf-8')
j = 0
for page in infolist:
commentall = page
for i in range(0, len(commentall)):
fw.write(commentall[i] + '\n')
j += 1
fw.close()
def main():
infolist = []
vid = '7225749902';
cid = "0";
page_num =3000
url = 'https://video.coral.qq.com/varticle/' + vid + '/comment/v2'
for i in range(page_num):
params = {'orinum': '10', 'cursor': cid}
html = get_html(url, params)
cid = parse_page(infolist, html)
print_comment_list(infolist)
save_to_txt(infolist, 'time.txt')
main()
��.���ݴ�������
1.���۵�ʱ���ת��Ϊ����ʱ�� time.py
import csv
import time
csvFile = open("data.csv",'w',newline='',encoding='utf-8')
writer = csv.writer(csvFile)
csvRow = []
f = open("time.txt",'r',encoding='utf-8')
for line in f:
csvRow = int(line)
timeArray = time.localtime(csvRow)
csvRow = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(csvRow)
csvRow = csvRow.split()
writer.writerow(csvRow)
f.close()
csvFile.close()
2.�������ݶ���csv CD.py
import csv
csvFile = open("content.csv",'w',newline='',encoding='utf-8')
writer = csv.writer(csvFile)
csvRow = []
f = open("content.txt",'r',encoding='utf-8')
for line in f:
csvRow = line.split()
writer.writerow(csvRow)
f.close()
csvFile.close()
3.ͳ��һ�����ʱ����ڵ������� py.py
import csv
from pyecharts import options as opts
from sympy.combinatorics import Subset
from wordcloud import WordCloud
with open('../Spiders/data.csv') as csvfile:
reader = csv.reader(csvfile)
data1 = [str(row[1])[0:2] for row in reader]
print(data1)
print(