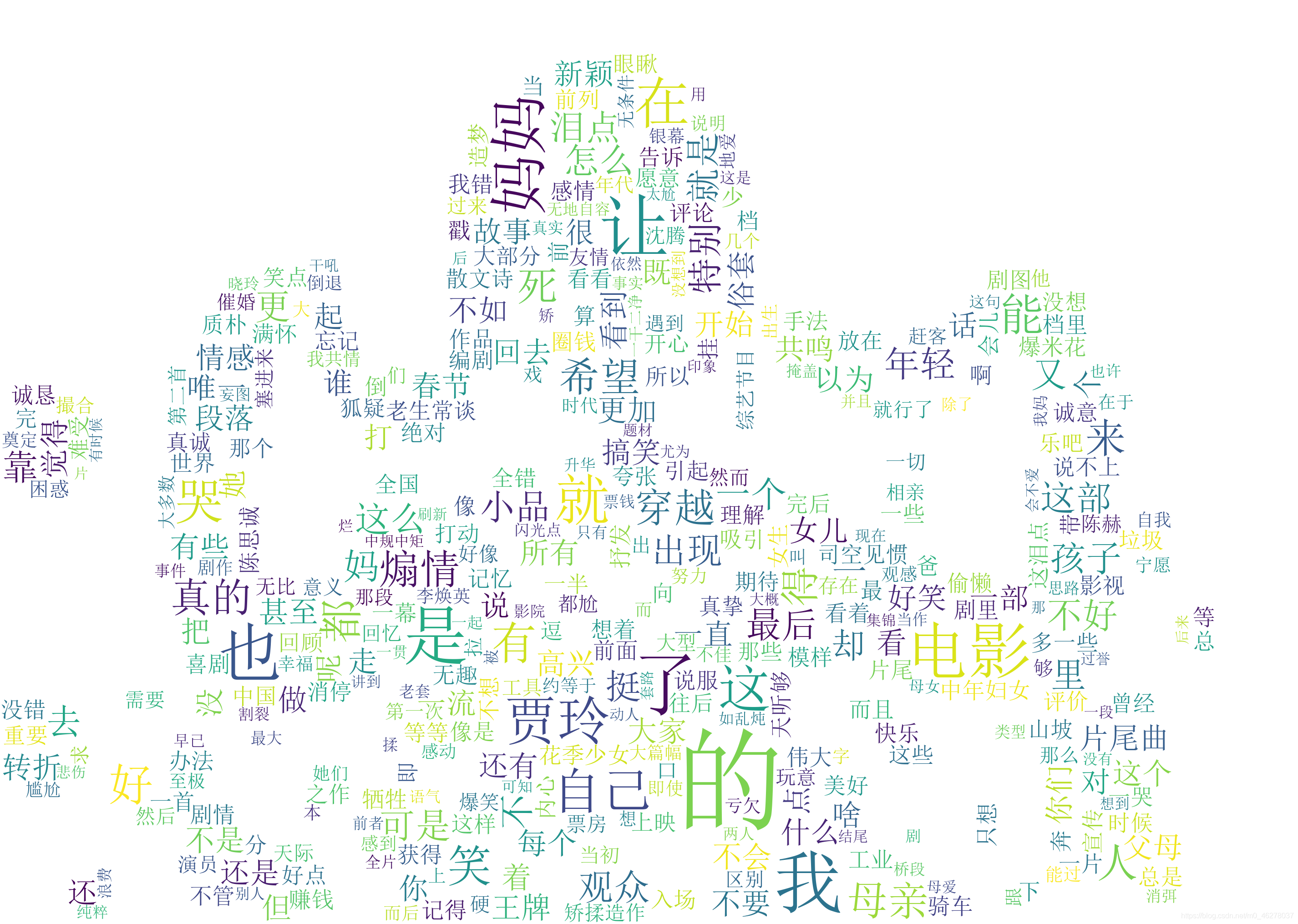import re
from PIL import Image
import requests
import jieba
import matplotlib.pyplot as plt
import numpy as np
from os import path
from wordcloud import WordCloud, STOPWORDS
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0'
}
d = path.dirname(__file__)
def spider_comment(movie_id, page):
"""
爬取评论
:param movie_id: 电影ID
:param page: 爬取前N页
:return: 评论内容
"""
comment_list = []
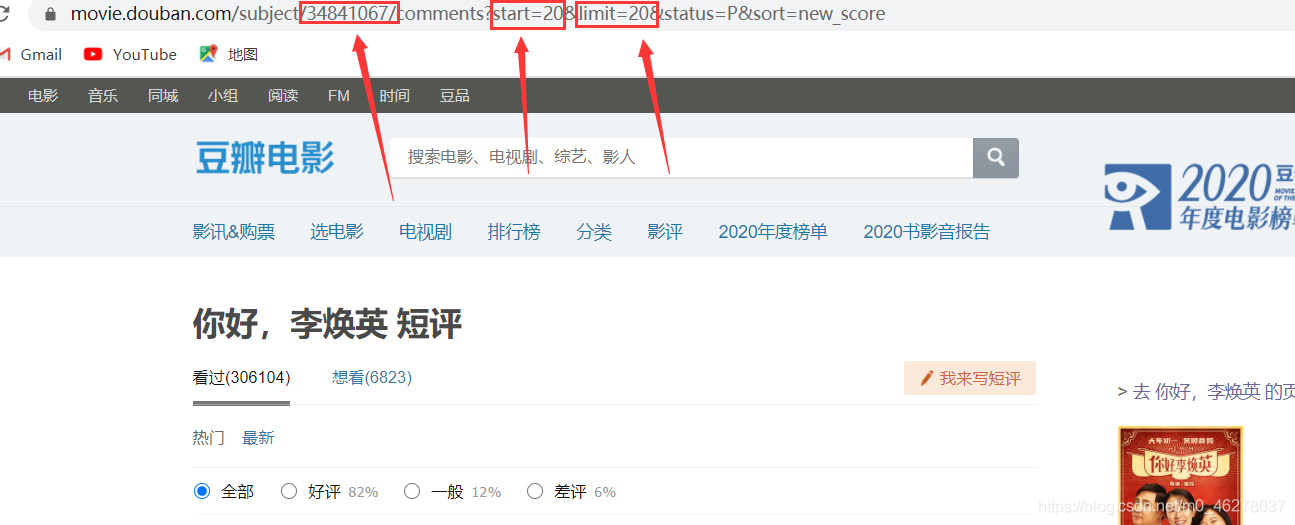
for i in range(page):
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P&percent_type=' \
% (movie_id, (i - 1) * 20)
req = requests.get(url, headers=headers)
req.encoding = 'utf-8'
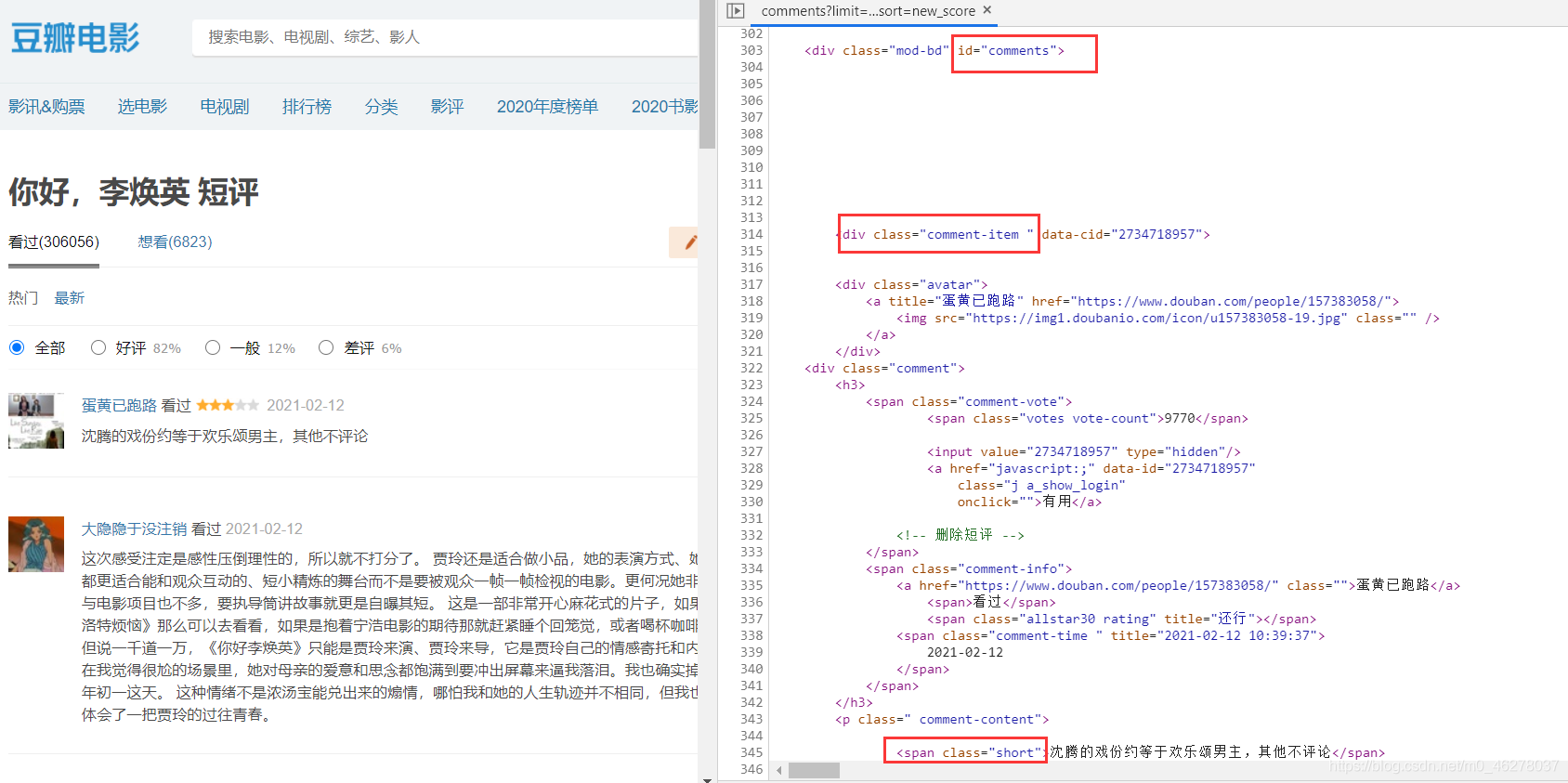
comment_list = re.findall('<span class="short">(.*)</span>', req.text)
print("当前页数:%s,总评论数:%s" % (i, len(comment_list)))
return comment_list
def wordcloud(comment_list):
wordlist = jieba.lcut(' '.join(comment_list))
text = ' '.join(wordlist)
print(text)
backgroud_Image = np.array(Image.open(path.join(d, "wordcloud.png")))
wordcloud = WordCloud(
font_path="simsun.ttc",
background_color="white",
mask=backgroud_Image,
stopwords=STOPWORDS,
width=2852,
height=2031,
margin=2,
max_words=6000,
max_font_size=250,
random_state=1,
scale=1)
wordcloud.generate(text)
wordcloud.to_image()
wordcloud.to_file("cloud.png")
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
if __name__ == '__main__':
movie_id = '34841067'
page = 11
comment_list = spider_comment(movie_id, page)
wordcloud(comment_list)
WordCloud各含义参数如下:
font_path : string
width : int (default=400)
height : int (default=200)
prefer_horizontal : float (default=0.90)
mask : nd-array or None (default=None)
scale : float (default=1)
min_font_size : int (default=4)
font_step : int (default=1)
max_words : number (default=200)
stopwords : set of strings or None
background_color : color value (default=”black”)
max_font_size : int or None (default=None)
mode : string (default=”RGB”)
relative_scaling : float (default=.5)
color_func : callable, default=None
regexp : string or None (optional)
collocations : bool, default=True
colormap : string or matplotlib colormap, default=”viridis”
random_state : int or None
fit_words(frequencies)
generate(text)
generate_from_frequencies(frequencies[, ...])
generate_from_text(text)
process_text(text)
recolor([random_state, color_func, colormap])
to_array()
to_file(filename)

cs