����Ѷ����ϵĶ�����������Ϊ�������زġ�

Ȼ����û�гɹ��������еĶ���,һ������,����ֻ������500��,��Ȼ��Ҳ�Ƕ���Ŀǰ�ɼ����������,���Ľ�ϸ�·����������������,�������������ݼ��Է���,��С����
?
��ƪ���¹����������ı�����������,��Ϊ���������ݰ�����Ϣ����,���Է���������Լ�,��������ͳ�Ʒ�������з����ͷִʴ���,��Ҫ�����ڸ����ָ���,��Ҫ����������������������ں�̨�ظ�"����2����",����ֱ�����С�
?
1. ���沿��
?
����˵��һ��Ŀ�����
����:python3.6
packages:selenium??jieba??snownlp??wordcloud
��������֮���ı������õġ�
Ŀ����ַ:https://movie.douban.com/subject/26636712/comments?status=P
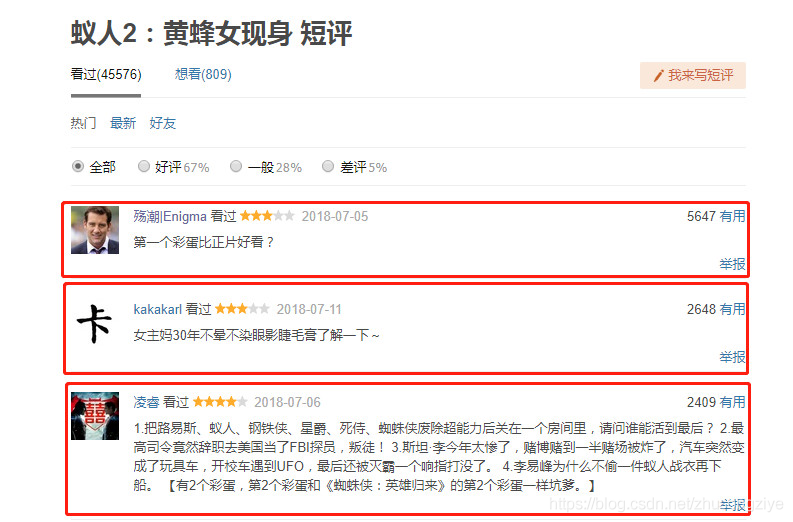
�����ϵ�Ӱ��������,һ���dz�ƪ���۵�Ӱ��,����һ���Ƕ���,������ͼ��,��������Ŀ�������ͼ�к�ɫ�����е�����,��Ϣ�����û���,�Ǽ�����,����,������,��������,��˵��ҳ��ʾ45576��,����ʵ�ɼ���ֻ��500��,ÿҳ��20������,��һ��������,�ֶ�ȥ��,�㵽25ҳ֮���û���κ���Ϣ�ˡ�
?
��һ��ֱ����seleniumȥ��ֻ������200��,200��֮����Զ�ֹͣ��,��������˰��췢�������¼������ȥ���ܿ������������,Ȼ���ּ��˵�½�Ĵ���,�������Թ����е�½��̫����������֤��,�ּ���һ���ֶ�������֤���IJ���,���ճɹ�������500��,��Ϊ֮ǰû�д�������½��ص�,���������˺ܳ�ʱ��,����������¡�
?
��½
��½ҳ���Ƕ�����ҳhttps://www.douban.com/,������������ȡ����վ,��������ͨ��seleniumģ���½֮��,�ٻ�ȡ����2����ҳ��������档
?
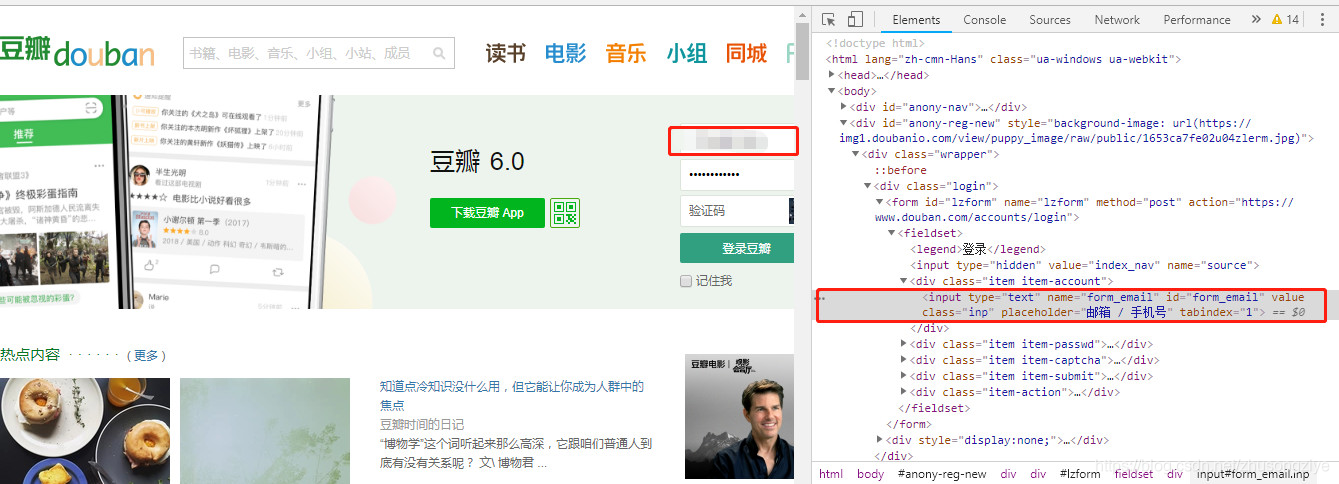
ͨ��chrome�����߹�����˻���,����,��֤���λ��,�˻���������ֱ������,��֤���ȡͼƬ���ȴ浽����,���ֶ�����,����֮��ص���֤��ͼƬ,�������ִ��,�͵�¼�ɹ���,�տ�ʼ�ǵ�ʱ����Ҫ��֤�롣
?
�˻���λ��(�㿪�Ŵ�)
����λ��(�㿪�Ŵ�)
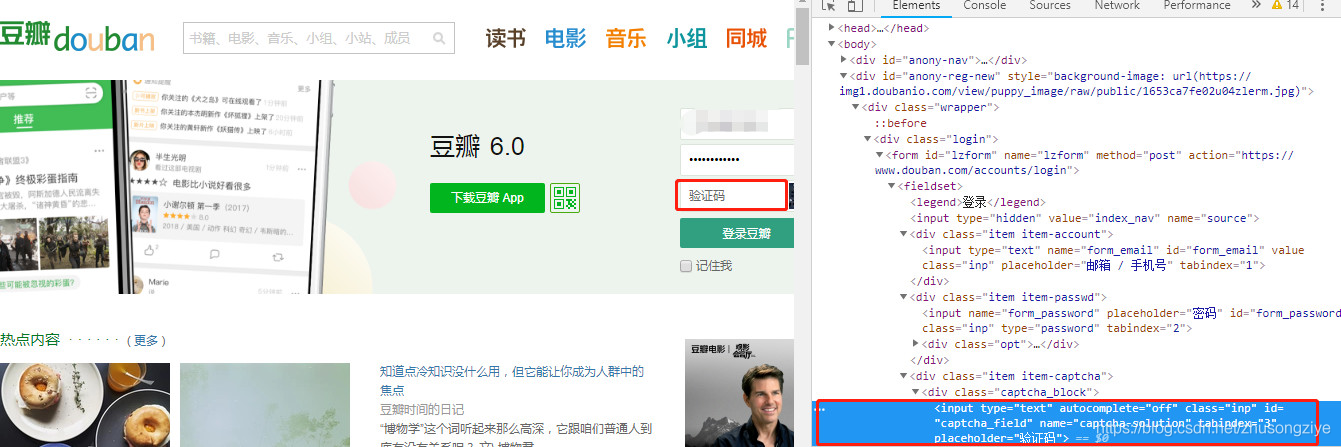
��֤��λ��(�㿪�Ŵ�)
?
��������
1def?gethtml(url):
2????loginurl='https://www.douban.com/'????#?��¼ҳ��
3
4????browser?=?webdriver.PhantomJS()????
5????browser.get(loginurl)????#?�����¼ҳ��
6????browser.find_element_by_name('form_email').clear()??#?��ȡ�û��������,�������
7????browser.find_element_by_name('form_email').send_keys(u'����û���')?#?�����û���
8????browser.find_element_by_name('form_password').clear()??#?��ȡ�����,�����
9????browser.find_element_by_name('form_password').send_keys(u'�������')?#?��������
10
11????#?��֤���ֶ�����,�����,��Ҫ��ͼƬ�رղ��ܼ���ִ����һ��
12????captcha_link?=?browser.find_element_by_id('captcha_image').get_attribute('src')
13????urllib.request.urlretrieve(captcha_link,'captcha.jpg')
14????Image.open('captcha.jpg').show()
15????captcha_code?=?input('Pls?input?captcha?code:')
16????browser.find_element_by_id('captcha_field').send_keys(captcha_code)???
17
18????browser.find_element_by_css_selector('input[class="bn-submit"]').click()
19????browser.get(url)
20????browser.implicitly_wait(10)
21????return(browser)
?
������
��¼֮��,ת������Ҫ��������2����ҳ��,����һҳ֮��,�ҵ���ҳ��λ��click��ת����һҳ������,ѭ��һֱ�����һҳ,�ӿ����߹��߿��Կ���,��һҳ�ĺ�ҳxpath��"//*[@id='paginator']/a",֮��ÿһҳ�ĺ�ҳ��xpath����"//*[@id='paginator']/a[3]",�����һҳ��xpath��Ϊ������,��˿���ͨ��ѭ���ķ�ʽ,��һҳ֮��,ֻҪ"//*[@id='paginator']/a[3]"�ҵõ�,����ת����һҳ������,ֱ���Ҳ���Ϊֹ��
��������ʱ��,��һ��dataframe�������е���Ϣ,һ��Ϊһ���û�����������,����λ����Ȼͨ�������߹����,ϸ�ڲ�������
?
����
1def?getComment(url):
2????i?=?1
3????AllArticle?=?pd.DataFrame()
4????browser?=?gethtml(url)
5????while?True:
6????????s?=?browser.find_elements_by_class_name('comment-item')
7????????articles?=?pd.DataFrame(s,columns?=?['web'])
8????????articles['uesr']?=?articles.web.apply(lambda?x:x.find_element_by_tag_name('a').get_attribute('title'))
9????????articles['comment']?=?articles.web.apply(lambda?x:x.find_element_by_class_name('short').text)
10????????articles['star']?=?articles.web.apply(lambda?x:x.find_element_by_xpath("//*[@id='comments']/div[1]/div[2]/h3/span[2]/span[2]").get_attribute('title'))
11????????articles['date']?=?articles.web.apply(lambda?x:x.find_element_by_class_name('comment-time').get_attribute('title'))
12????????articles['vote']?=?articles.web.apply(lambda?x:np.int(x.find_element_by_class_name('votes').text))
13????????del?articles['web']
14????????AllArticle?=?pd.concat([AllArticle,articles],axis?=?0)
15????????print?('��'?+?str(i)?+?'ҳ���!')
16
17????????try:
18????????????if?i==1:
19????????????????browser.find_element_by_xpath("//*[@id='paginator']/a").click()??
20????????????else:
21????????????????browser.find_element_by_xpath("//*[@id='paginator']/a[3]").click()
22????????????browser.implicitly_wait(10)
23????????????time.sleep(3)?#?��ͣ3��
24????????????i?=?i?+?1
25????????except:
26????????????AllArticle?=?AllArticle.reset_index(drop?=?True)
27????????????return?AllArticle
28????AllArticle?=?AllArticle.reset_index(drop?=?True)
29????return?AllArticle
?
������������������ȡ����,��ʵ���ڶ����ϱ�ĵ�ӰӰ��,��������һ��Ҳ��������
1url?=?'https://movie.douban.com/subject/26636712/comments?status=P'
2result?=?getComment(url)
?
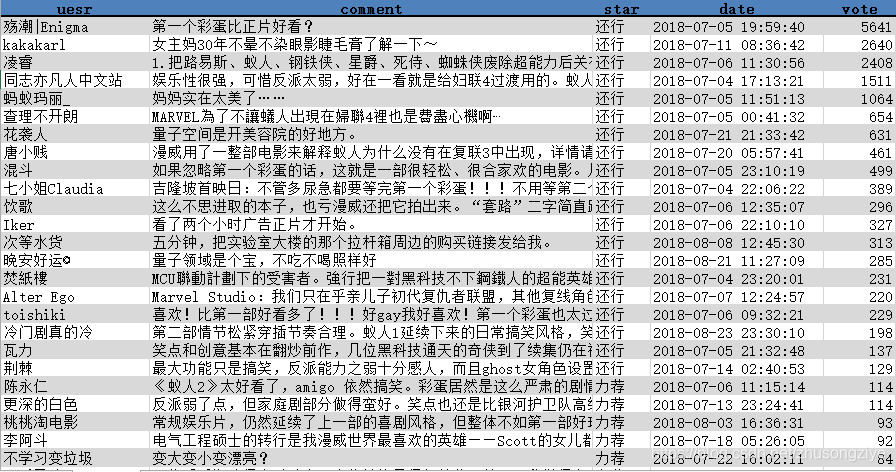
���������������ݴ����������
?
2. �ı�����
?
����ͳ�Ʒ���
���ȿ�һ���õ��������и��Ǽ����۵ķֲ����,None��ʾû���Ǽ����ۡ�
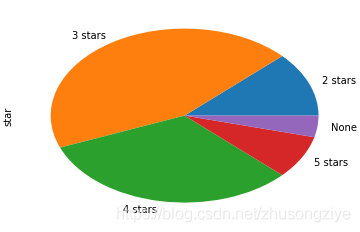
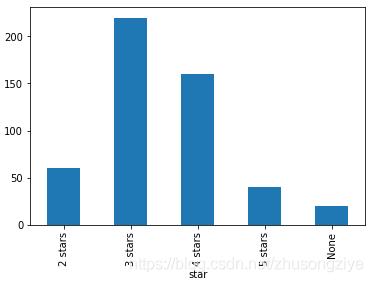
��������,�����������۾�,˵����Ҷ�������2�������ۻ�������
?
����������Щ����������Ͽ�,ͶƱ�����

?
��,��ô˵��

�����Ʒ�Ů�İ�������Ъ�����Ʒ�Ҳ�ɹ������˹��Ӱ�Ե�ע������
?
����
��з������ıȽϼ�,��Ҫ������snownlp��,�������۵���������������,0-1֮��,Խ�������������Ӧ�ķ�ֵԽ��,�������ݹٷ�˵��,�����õ���ģ�����ù�����������ѵ��������,�õ��������������Щ��, ����һ��,�о�Ч�������ԡ�
1#?����
2def?sentiment(content):
3????s?=?SnowNLP(str(content))
4????return?s.sentiments
5
6
7result['sentiment']?=?result.comment.apply(sentiment)
8
9#?��������
10result.sort(['sentiment'],ascending?=?True)[:10][['comment','sentiment']]
11
12#?��������
13result.sort(['sentiment'],ascending?=?False)[:10][['comment','sentiment']]
?
����������������,sentiment��ʾ��е÷֡�
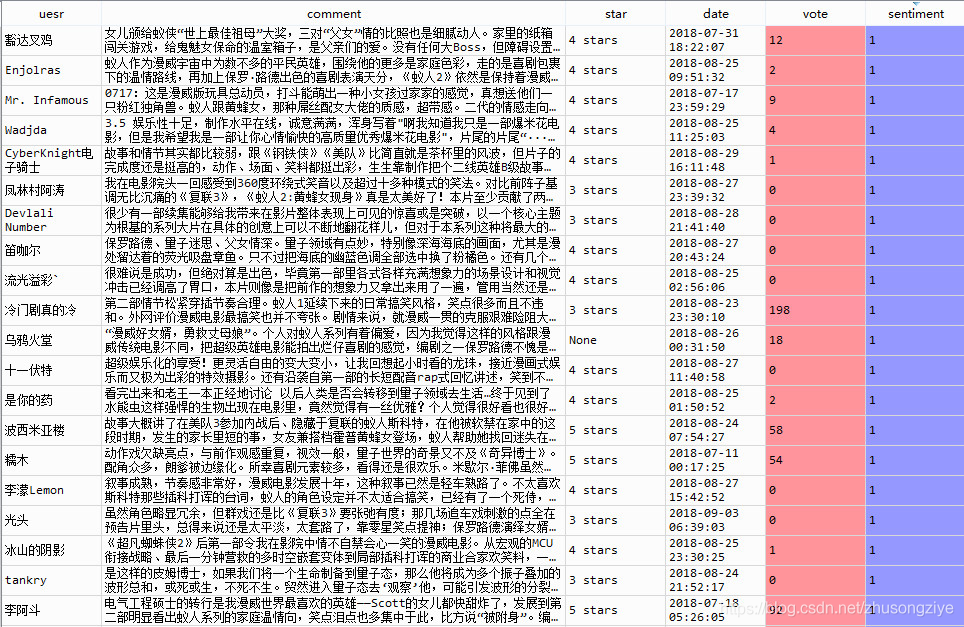
?
��,����ȥ�������ۻ������Ǹ��Ǽ����ֵĹ��ڸ�����,�����о�,�����ŷ�������������������
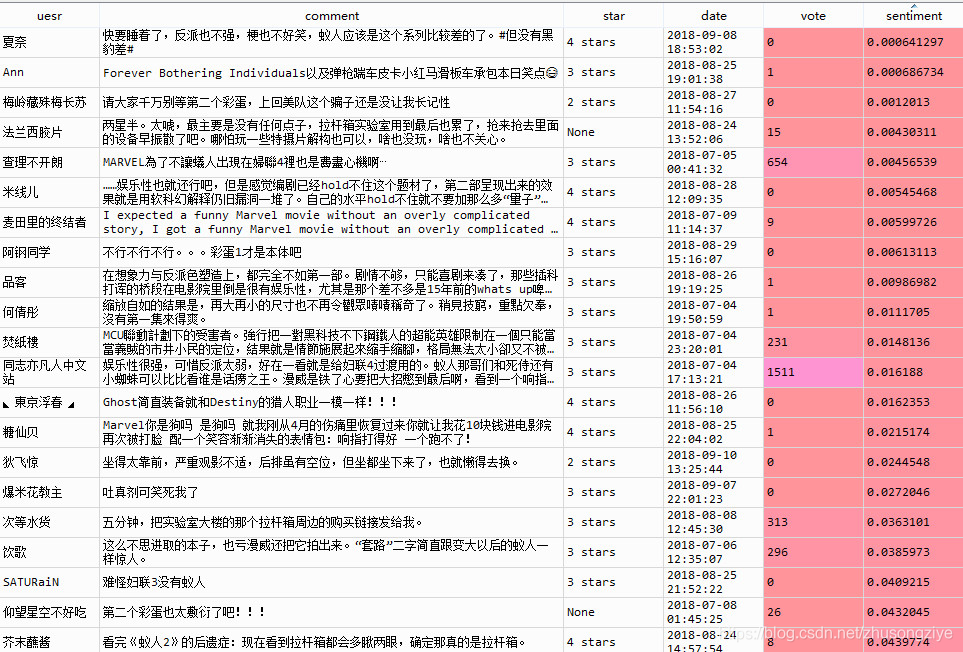
?
�ִʴ���
ͨ��jieba���зִ�,����TF-IDF�㷨��ȡ�ؼ���,���뼰���ֹؼ�������
1texts?=?';'.join(result.comment.tolist())
2cut_text?=?"?".join(jieba.cut(texts))
3keywords?=?jieba.analyse.extract_tags(cut_text,?topK=500,?withWeight=True,?allowPOS=('a','e','n','nr','ns'))
4
5
6ss?=?pd.DataFrame(keywords,columns?=?['����','��Ҫ��'])
7
8fig?=?plt.axes()
9plt.barh(range(len(ss.��Ҫ��[:20][::-1])),ss.��Ҫ��[:20][::-1],color?=?'darkred')
10fig.set_yticks(np.arange(len(ss.��Ҫ��[:20][::-1])))
11fig.set_yticklabels(ss.����[:20][::-1],fontproperties=font)
12fig.set_xlabel('Importance')
13
14alice_mask?=?np.array(Image.open(?"yiren.jpg"))
15text_cloud?=?dict(keywords)
16cloud?=?WordCloud(
17????????width?=?600,height?=400,
18????????font_path="STSONG.TTF",
19????????#?���ñ���ɫ
20????????background_color='white',
21
22????????mask=alice_mask,
23????????#�������ʻ�
24????????max_words=500,
25????????#��������
26????????max_font_size=150,
27????????#random_state=777,
28???#?????colormap?=?'Accent_r'
29????)
30
31
32
33plt.figure(figsize=(12,12))
34word_cloud?=?cloud.generate_from_frequencies(text_cloud)
35plt.imshow(word_cloud)
36plt.axis('off')
37plt.show()
?
�ؼ���
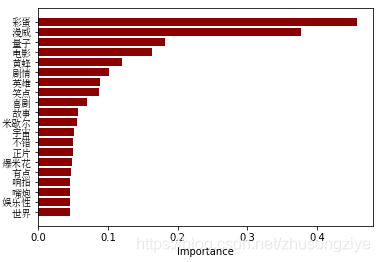
�ִʽ������,"�ʵ�"����������������2�д������ĵĵ㡣���,�����˷ִʴ�����Ϊ���½�β!

?
cs