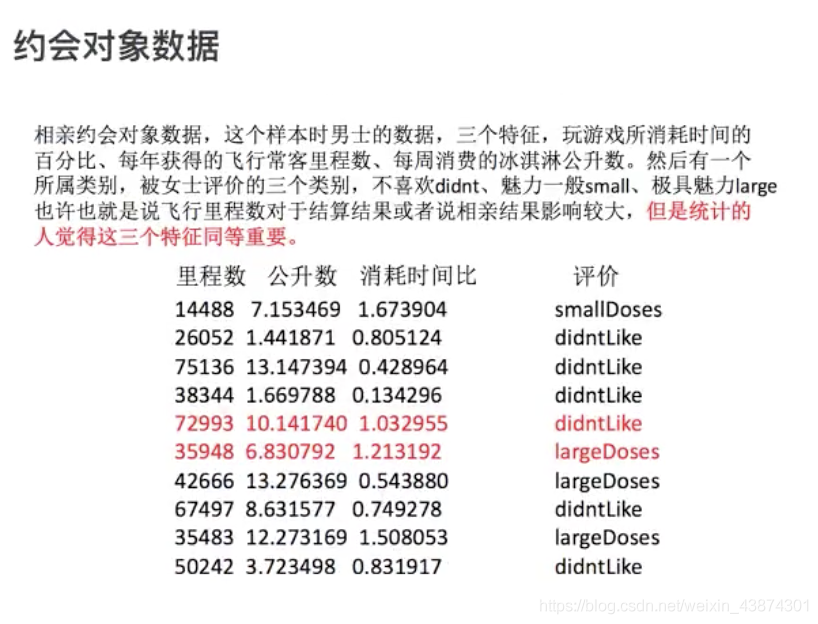
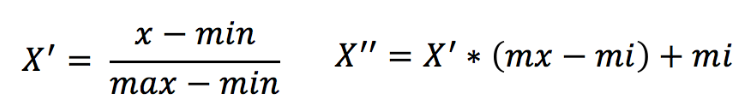milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
38344,1.669788,0.134296,1
分析
-
实例化MinMaxScalar
-
通过fit_transform转换
def minmax_demo():
"""
归一化
:return:
"""
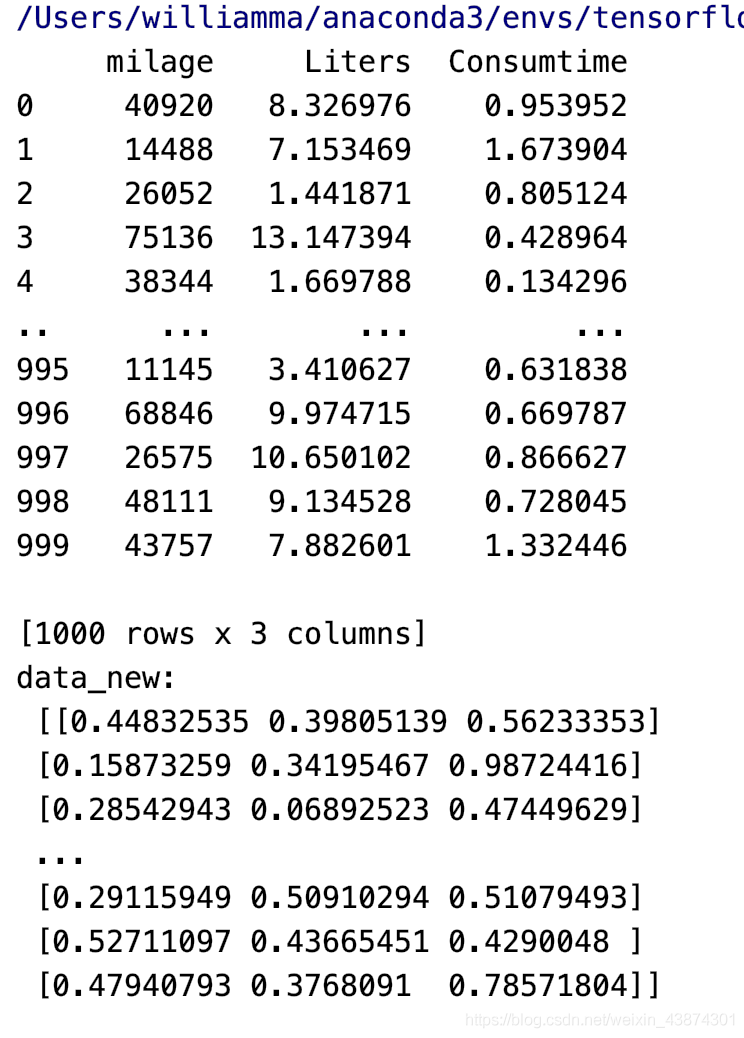
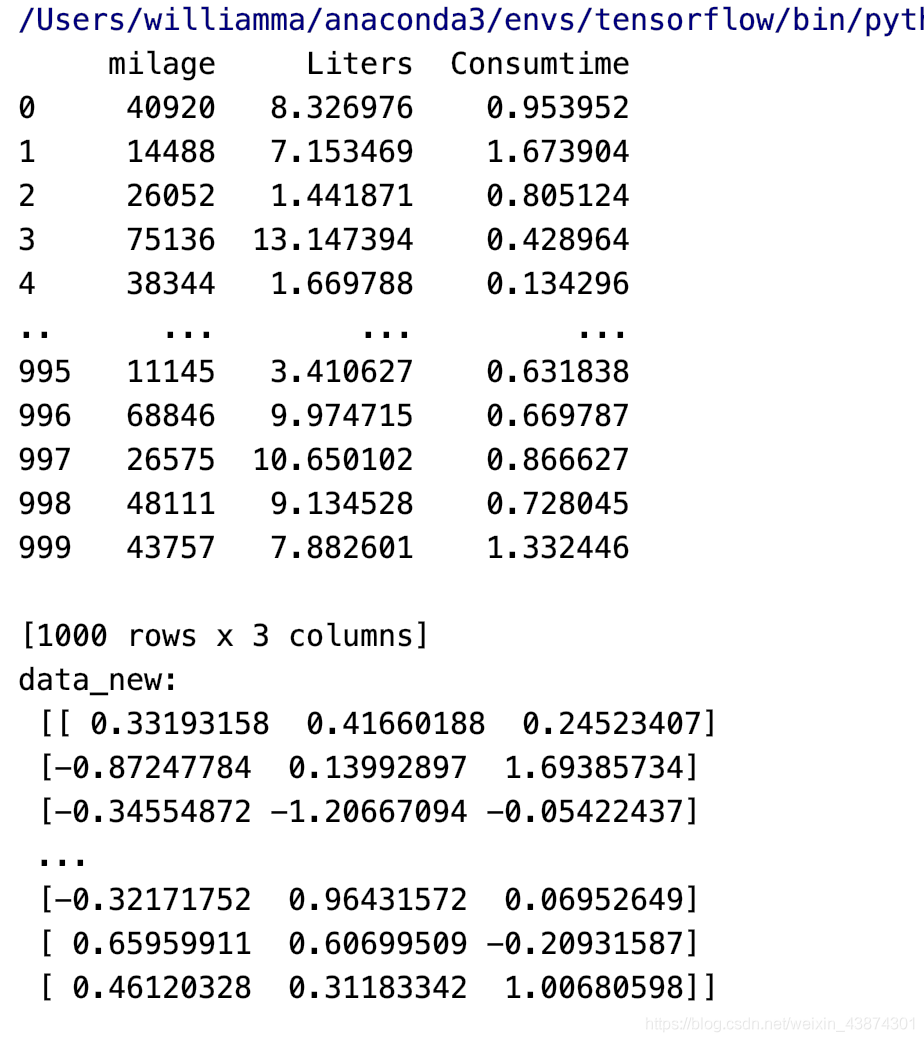
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print(data)
transform = MinMaxScaler()
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)
return None
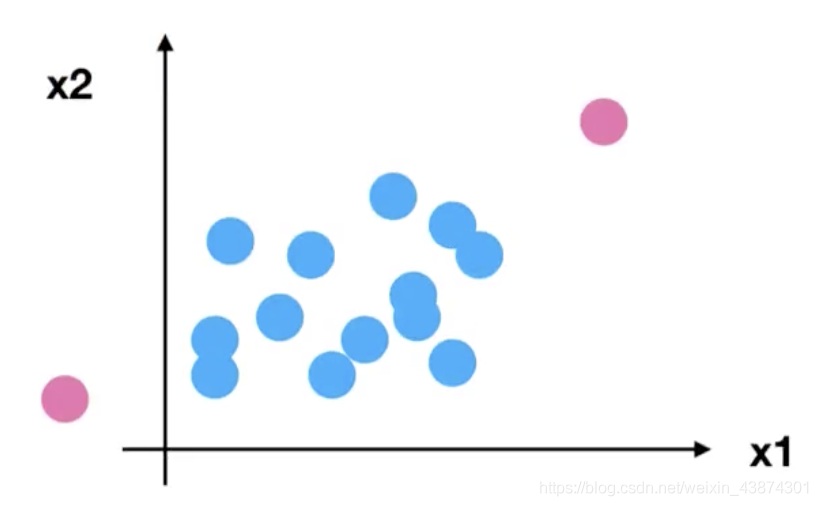
问题:如果数据中异常点较多,会有什么影响?
2.5 归一化总结
注意最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
3 标准化
3.1 定义
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
3.2 公式
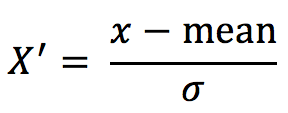
作用于每一列,mean为平均值,σ为标准差
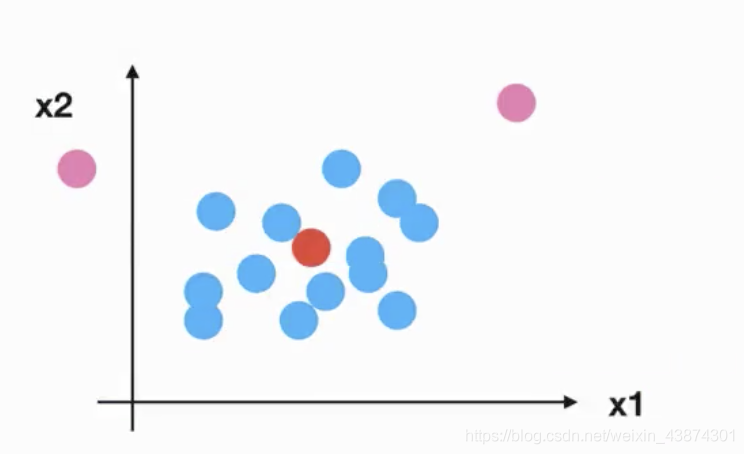
所以回到刚才异常点的地方,我们再来看看标准化
API
- sklearn.preprocessing.StandardScaler( )
- 处理之后每列来说所有数据都聚集在均值0附近标准差差为1
- StandardScaler.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
数据计算
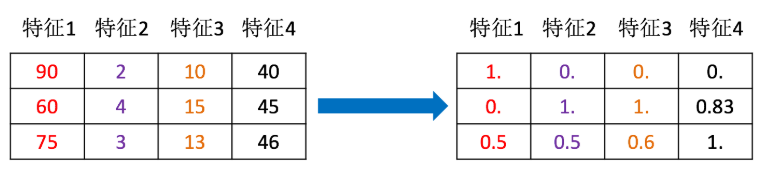
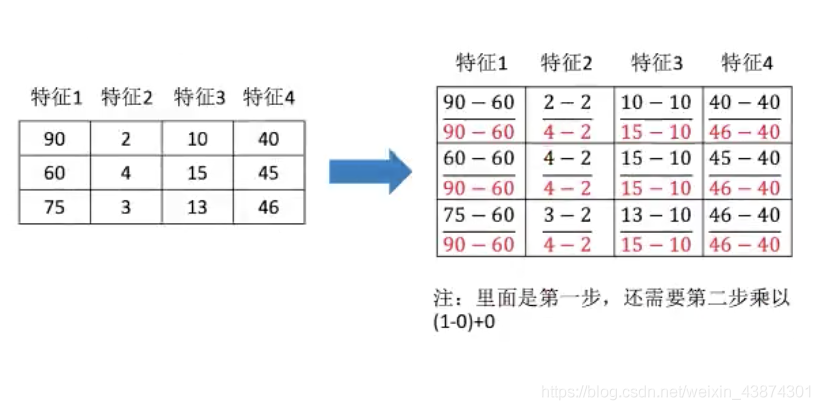
同样对上面的数据进行处理
[[90,2,10,40],
[60,4,15,45],
[75,3,13,46]]
分析
-
实例化StandardScaler
-
通过fit_transform转换
def stand_demo():
"""
进行标准化
在已有样本足够多的情况下,适合现在嘈杂大数据场景
:return:
"""
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print(data)
transform = StandardScaler()
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)
return None
标准化总结
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
cs