目标
K-近邻算法(KNN)
定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,即由你的“邻居”来推断出你的类别
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
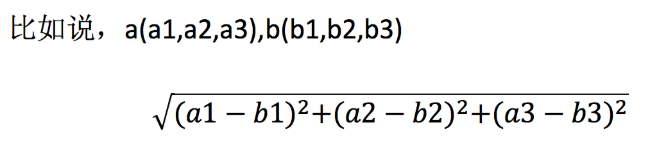
曼哈顿距离 绝对值距离
明可夫斯基距离
电影类型分析
假设我们有现在几部电影
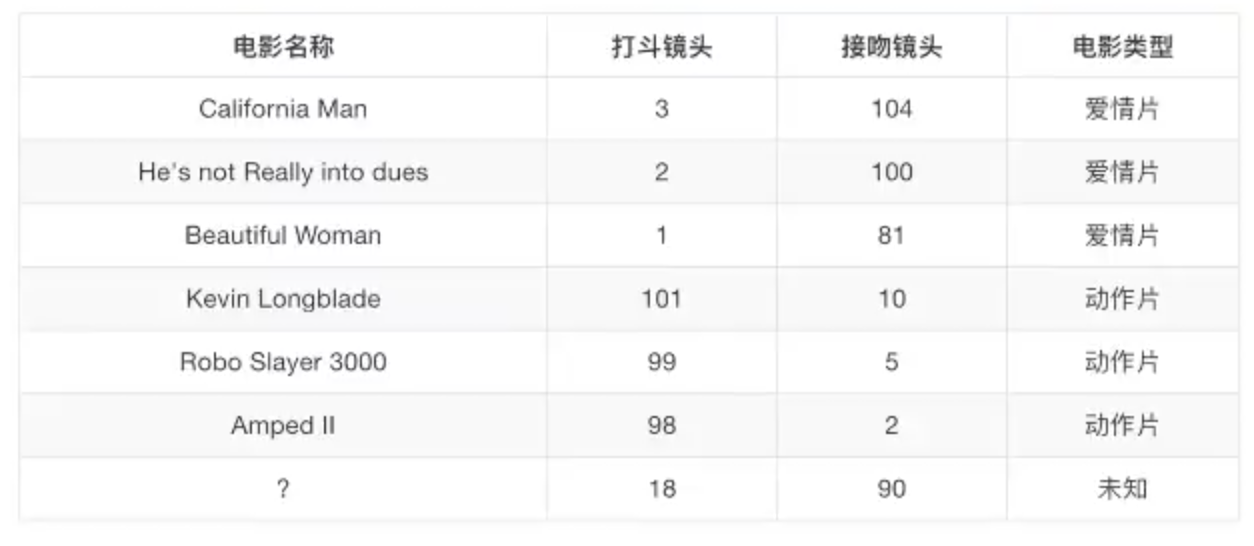
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想
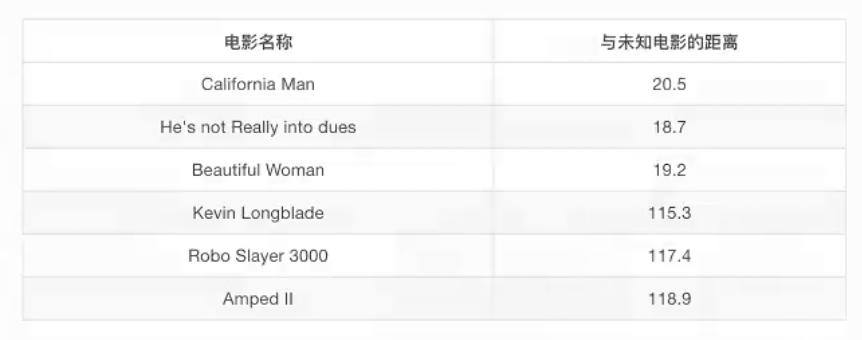
问题
如果取的最近的电影数量不一样?会是什么结果?
k 值取值过大,样本不均衡的影响
k 值取值过小,容易受到异常点影响
结合前面的约会对象数据,分析k-近邻算法需要做怎么样的处理
无量纲化的处理
推荐 标准还
K-近邻算法数据的特征工程处理
结合前面的约会对象数据,分析K-近邻算法需要做什么样的处理
K-近邻算法API
案例1 鸢尾花种类预测
数据集介绍
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:

步骤
-
获取数据
-
数据集划分
-
特征工程
-
机器学习训练 KNN 预估器流程
-
模型评估
代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
def knn_iris():
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
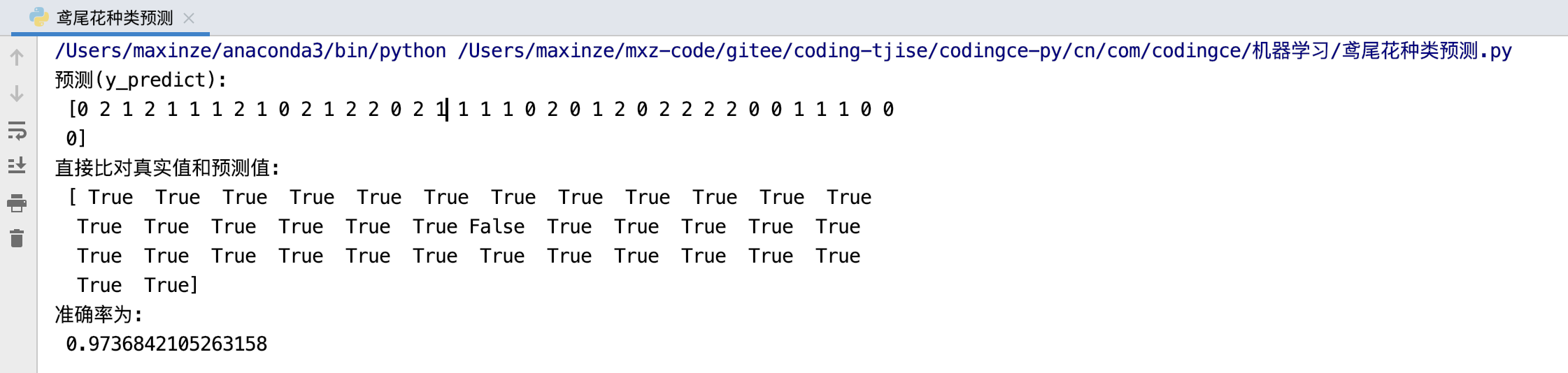
print("预测(y_predict):\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
if __name__ == '__main__':
knn_iris()
K-近邻总结
优点
简单,易于理解,易于实现,无需训练
缺点
cs