index,pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expense,date,return
0,000001.XSHE,5.9572,1.1818,85252550922.0,0.8008,14.9403,1211444855670.0,2.01,20701401000.0,10882540000.0,2012-01-31,0.027657228229937388
1,000002.XSHE,7.0289,1.588,84113358168.0,1.6463,7.8656,300252061695.0,0.326,29308369223.2,23783476901.2,2012-01-31,0.08235182370820669
2,000008.XSHE,-262.7461,7.0003,517045520.0,-0.5678,-0.5943,770517752.56,-0.006,11679829.03,12030080.04,2012-01-31,0.09978900335112327
3,000060.XSHE,16.476,3.7146,19680455995.0,5.6036,14.617,28009159184.6,0.35,9189386877.65,7935542726.05,2012-01-31,0.12159482758620697
4,000069.XSHE,12.5878,2.5616,41727214853.0,2.8729,10.9097,81247380359.0,0.271,8951453490.28,7091397989.13,2012-01-31,-0.0026808154146886697
def variance_demo():
"""
过滤低方差特征
:return:
"""
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1: -2]
print(data)
transfer = VarianceThreshold(threshold=5)
data_new = transfer.fit_transform(data)
print("data_new", data_new, data_new.shape)
return None
if __name__ == '__main__':
variance_demo()

相关系数
皮尔逊相关系数(Pearson Correlation Coefficient): 反映变量之间相关关系密切程度的统计指标
公式计算案例(了解,不用记忆)
公式:
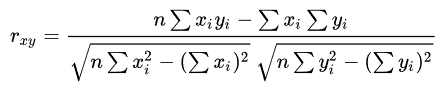
比如说我们计算年广告费投入与月均销售额
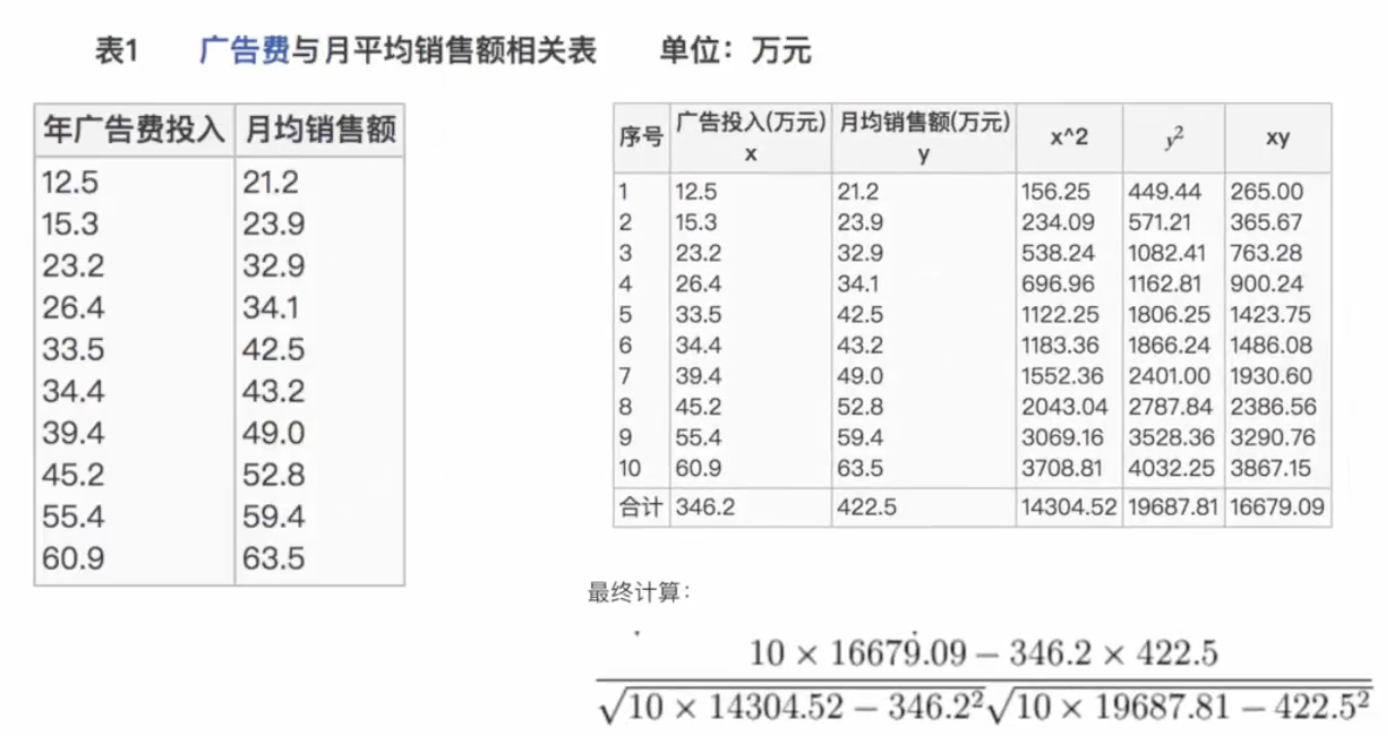
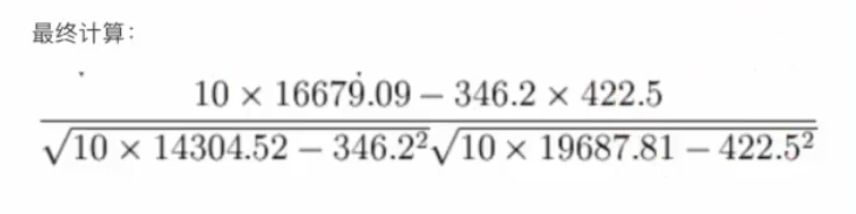
= 0.9942
所以我们最终得出结论是广告投入费与月平均销售额之间有高度的正相关关系。
特点
相关系数的值介于–1与+1之间,即–1≤ r ≤+1。其性质如下:
-
当r>0时,表示两变量正相关,r<0时,两变量为负相关
-
当|r|=1时,表示两变量为完全相关,当r=0时,表示两变量间无相关关系
-
当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱
一般可按三级划分:|r|<0.4为低度相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关
这个符号:|r|为r的绝对值, |-5| = 5
API
from scipy.stats import pearsonr
x : (N,) array_like
y : (N,) array_like Returns: (Pearson’s correlation coefficient, p-value)
cs