
一、JDK 和 JRE 有什么区别?
JDK(Java Development Kit),Java开发工具包
JRE(Java Runtime Environment),Java运行环境
JDK中包含JRE,JDK中有一个名为jre的目录,里面包含两个文件夹bin和lib,bin就是JVM,lib就是JVM工作所需要的类库。
二、== 和 equals 的区别是什么?
- 对于基本类型,==比较的是值;
- 对于引用类型,==比较的是地址;
- equals不能用于基本类型的比较;
- 如果没有重写equals,equals就相当于==;
- 如果重写了equals方法,equals比较的是对象的内容;
三、final 在 java 中有什么作用?
- final修饰的成员变量,必须在声明的同时赋值,一旦创建不可修改;
- final修饰的方法,不能被子类重写;
- final类中的方法默认是final的;
- private类型的方法默认是final的;
四、java 中的 Math.round(-1.5) 等于多少?
Math提供了三个与取整有关的方法:ceil、floor、round
1、ceil:向上取整;
Math.ceil(11.3) = 12;
Math.ceil(-11.3) = 11;
2、floor:向下取整;
Math.floor(11.3) = 11;
Math.floor(-11.3) = -12;
3、round:四舍五入;
加0.5然后向下取整。
Math.round(11.3) = 11;
Math.round(11.8) = 12;
Math.round(-11.3) = -11;
Math.round(-11.8) = -12;
五、String 属于基础的数据类型吗?
不属于。
八种基本数据类型:byte、short、char、int、long、double、float、boolean。
六、String str="i"与 String str=new String(“i”)一样吗?
String str="i"会将起分配到常量池中,常量池中没有重复的元素,如果常量池中存中i,就将i的地址赋给变量,如果没有就创建一个再赋给变量。
String str=new String(“i”)会将对象分配到堆中,即使内存一样,还是会重新创建一个新的对象。
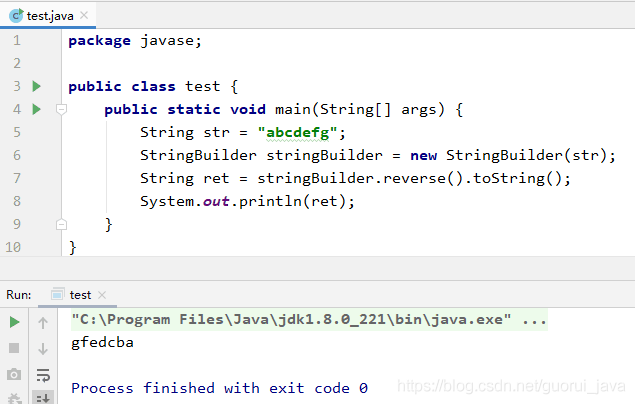
七、如何将字符串反转?
将对象封装到stringBuilder中,调用reverse方法反转。
八、String 类的常用方法都有那些?
1、常见String类的获取功能
- length:获取字符串长度;
- charAt(int index):获取指定索引位置的字符;
- indexOf(int ch):返回指定字符在此字符串中第一次出现处的索引;
- substring(int start):从指定位置开始截取字符串,默认到末尾;
- substring(int start,int end):从指定位置开始到指定位置结束截取字符串;
2、常见String类的判断功能
- equals(Object obj):?比较字符串的内容是否相同,区分大小写;
- contains(String str): 判断字符串中是否包含传递进来的字符串;
- startsWith(String str): 判断字符串是否以传递进来的字符串开头;
- endsWith(String str): 判断字符串是否以传递进来的字符串结尾;
- isEmpty(): 判断字符串的内容是否为空串"";
3、常见String类的转换功能
- byte[] getBytes(): 把字符串转换为字节数组;
- char[] toCharArray(): 把字符串转换为字符数组;
- String valueOf(char[] chs): 把字符数组转成字符串。valueOf可以将任意类型转为字符串;
- toLowerCase(): 把字符串转成小写;
- toUpperCase(): 把字符串转成大写;
- concat(String str): 把字符串拼接;
4、常见String类的其他常用功能
- replace(char old,char new) 将指定字符进行互换
- replace(String old,String new) 将指定字符串进行互换
- trim() 去除两端空格
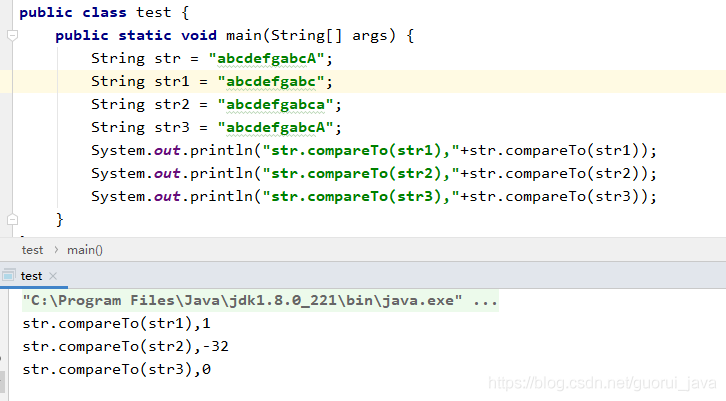
- int compareTo(String str) 会对照ASCII 码表 从第一个字母进行减法运算 返回的就是这个减法的结果,如果前面几个字母一样会根据两个字符串的长度进行减法运算返回的就是这个减法的结果,如果连个字符串一摸一样 返回的就是0。
九、new String("a") + new String("b") 会创建几个对象?
对象1:new StringBuilder()
对象2:new String("a")
对象3:常量池中的"a"
对象4:new String("b")
对象5:常量池中的"b"
深入剖析:StringBuilder中的toString():
对象6:new String("ab")
强调一下,toString()的调用,在字符串常量池中,没有生成"ab"
附加题:
String s1 = new String("1") + new String("1");//s1变量记录的地址为:new String
s1.intern();//在字符串常量池中生成"11"。如何理解:jdk6:创建了一个新的对象"11",也就有新的地址;jdk7:此时常量池中并没有创建"11",而是创建了一个指向堆空间中new String("11")的地址;
String s2 = "11";
System.out.println(s1 == s2);//jdk6:false;jdk7:true
十、普通类和抽象类有哪些区别?
- 抽象类不能被实例化;
- 抽象类可以有抽象方法,只需申明,无须实现;
- 有抽象方法的类一定是抽象类;
- 抽象类的子类必须实现抽象类中的所有抽象方法,否则子类仍然是抽象类;
- 抽象方法不能声明为静态、不能被static、final修饰。
十一、接口和抽象类有什么区别?
1、接口
- 接口使用interface修饰;
- 接口不能实例化;
- 类可以实现多个接口;
- ①java8之前,接口中的方法都是抽象方法,省略了public abstract。②java8之后;接口中可以定义静态方法,静态方法必须有方法体,普通方法没有方法体,需要被实现;
2、抽象类
- 抽象类使用abstract修饰;
- 抽象类不能被实例化;
- 抽象类只能单继承;
- 抽象类中可以包含抽象方法和非抽象方法,非抽象方法需要有方法体;
- 如果一个类继承了抽象类,①如果实现了所有的抽象方法,子类可以不是抽象类;②如果没有实现所有的抽象方法,子类仍然是抽象类。
十二、java 中 IO 流分为几种?
1、按流划分,可以分为输入流和输出流;
2、按单位划分,可以分为字节流和字符流;
字节流:inputStream、outputStream;
字符流:reader、writer;
十三、说一下 jsp 的 4 种作用域?
application、session、request、page
十四、BIO、NIO、AIO 有什么区别?
1、同步阻塞BIO
一个连接一个线程。
JDK1.4之前,建立网络连接的时候采用BIO模式,先在启动服务端socket,然后启动客户端socket,对服务端通信,客户端发送请求后,先判断服务端是否有线程响应,如果没有则会一直等待或者遭到拒绝请求,如果有的话会等待请求结束后才继续执行。
2、同步非阻塞NIO
NIO主要是想解决BIO的大并发问题,BIO是每一个请求分配一个线程,当请求过多时,每个线程占用一定的内存空间,服务器瘫痪了。
JDK1.4开始支持NIO,适用于连接数目多且连接比较短的架构,比如聊天服务器,并发局限于应用中。
一个请求一个线程。
3、异步非阻塞AIO
一个有效请求一个线程。
JDK1.7开始支持AIO,适用于连接数目多且连接比较长的结构,比如相册服务器,充分调用OS参与并发操作。
十五、Files的常用方法都有哪些?
- exist
- createFile
- createDirectory
- write
- read
- copy
- size
- delete
- move
十六、什么是反射?
所谓反射,是java在运行时进行自我观察的能力,通过class、constructor、field、method四个方法获取一个类的各个组成部分。
在Java运行时环境中,对任意一个类,可以知道类有哪些属性和方法。这种动态获取类的信息以及动态调用对象的方法的功能来自于反射机制。
十七、什么是 java 序列化?什么情况下需要序列化?
序列化就是一种用来处理对象流的机制。将对象的内容流化,将流化后的对象传输于网络之间。
序列化是通过实现serializable接口,该接口没有需要实现的方法,implement Serializable只是为了标注该对象是可被序列化的,使用一个输出流(FileOutputStream)来构造一个ObjectOutputStream对象,接着使用ObjectOutputStream对象的writeObejct(Object object)方法就可以将参数的obj对象到磁盘,需要恢复的时候使用输入流。
序列化是将对象转换为容易传输的格式的过程。
例如,可以序列化一个对象,然后通过HTTP通过Internet在客户端和服务器之间传输该对象。在另一端,反序列化将从流中心构造成对象。
一般程序在运行时,产生对象,这些对象随着程序的停止而消失,但我们想将某些对象保存下来,这时,我们就可以通过序列化将对象保存在磁盘,需要使用的时候通过反序列化获取到。
对象序列化的最主要目的就是传递和保存对象,保存对象的完整性和可传递性。
譬如通过网络传输或者把一个对象保存成本地一个文件的时候,需要使用序列化。
十八、为什么要使用克隆?如何实现对象克隆?深拷贝和浅拷贝区别是什么?
1、什么要使用克隆?
想对一个对象进行复制,又想保留原有的对象进行接下来的操作,这个时候就需要克隆了。
2、如何实现对象克隆?
- 实现Cloneable接口,重写clone方法;
- 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深克隆。
- BeanUtils,apache和Spring都提供了bean工具,只是这都是浅克隆。
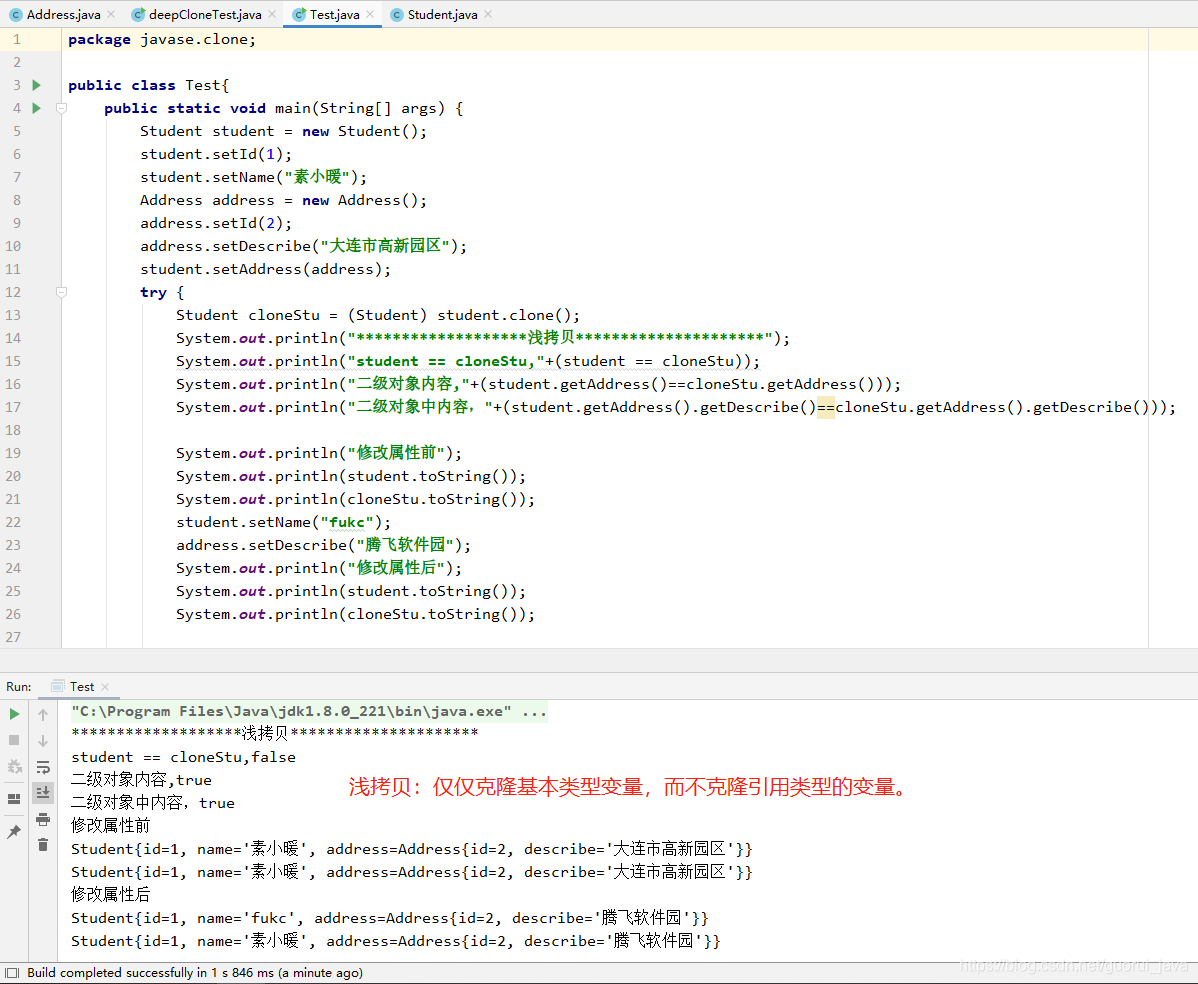
3、深拷贝和浅拷贝区别是什么?
- 浅拷贝:仅仅克隆基本类型变量,不克隆引用类型变量;
- 深克隆:既克隆基本类型变量,又克隆引用类型变量;
4、代码实例
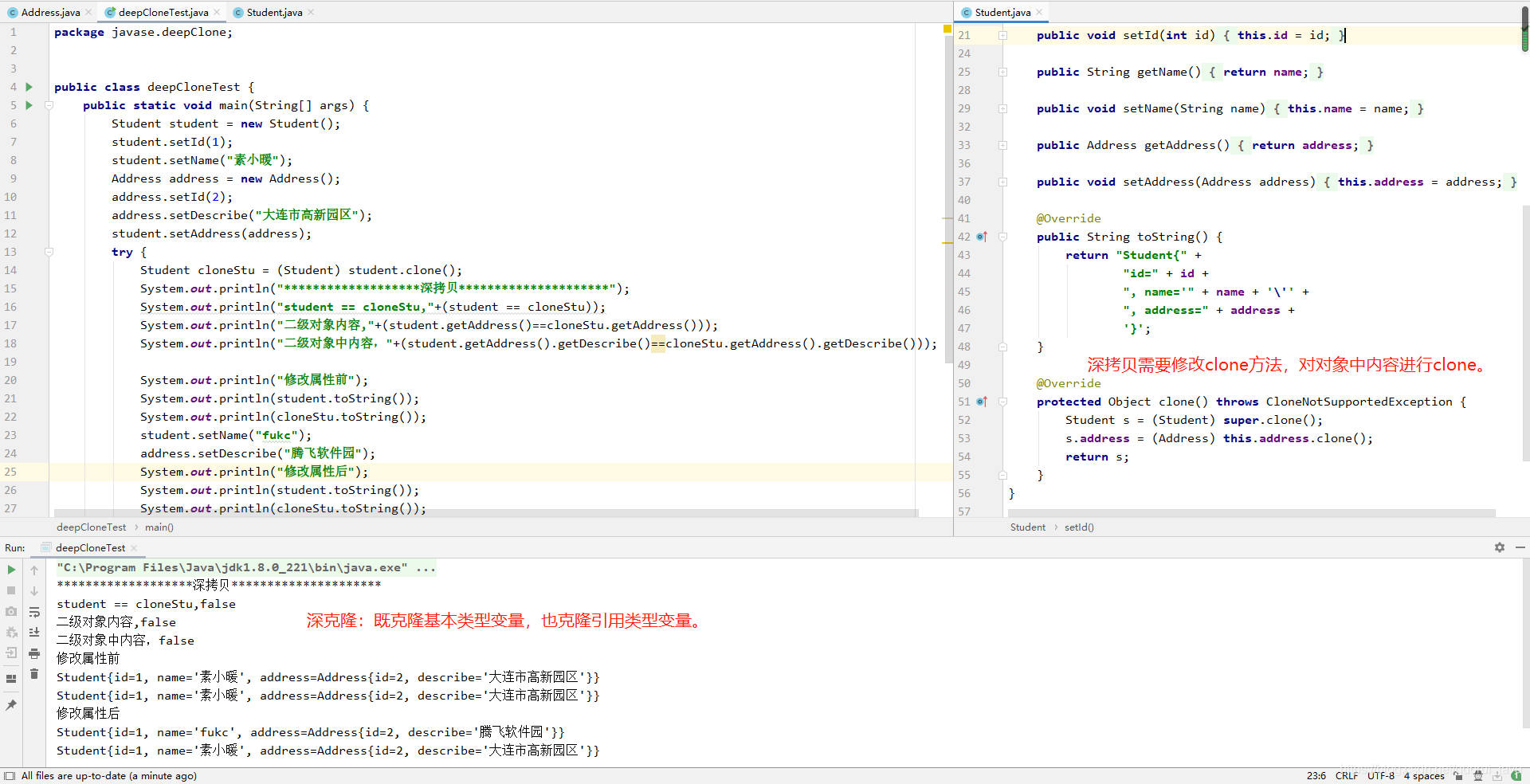
十九、throw 和 throws 的区别?
1、throw
- 作用在方法内,表示抛出具体异常,由方法体内的语句处理;
- 一定抛出了异常;
2、throws
- 作用在方法的声明上,表示抛出异常,由调用者来进行异常处理;
- 可能出现异常,不一定会发生异常;
二十、final、finally、finalize 有什么区别?
final可以修饰类,变量,方法,修饰的类不能被继承,修饰的变量不能重新赋值,修饰的方法不能被重写
finally用于抛异常,finally代码块内语句无论是否发生异常,都会在执行finally,常用于一些流的关闭。
finalize方法用于垃圾回收。
一般情况下不需要我们实现finalize,当对象被回收的时候需要释放一些资源,比如socket链接,在对象初始化时创建,整个生命周期内有效,那么需要实现finalize方法,关闭这个链接。
但是当调用finalize方法后,并不意味着gc会立即回收该对象,所以有可能真正调用的时候,对象又不需要回收了,然后到了真正要回收的时候,因为之前调用过一次,这次又不会调用了,产生问题。所以,不推荐使用finalize方法。
二十一、try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
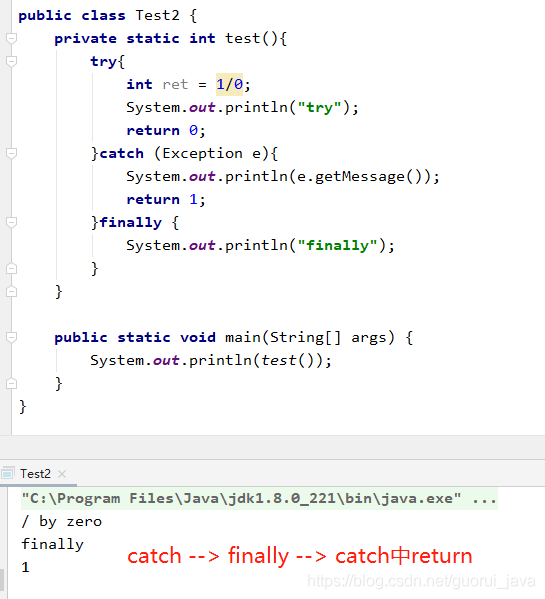
二十二、常见的异常类有哪些?
- NullPointerException:空指针异常;
- SQLException:数据库相关的异常;
- IndexOutOfBoundsException:数组下角标越界异常;
- FileNotFoundException:打开文件失败时抛出;
- IOException:当发生某种IO异常时抛出;
- ClassCastException:当试图将对象强制转换为不是实例的子类时,抛出此异常;
- NoSuchMethodException:无法找到某一方法时,抛出;
- ArrayStoreException:试图将错误类型的对象存储到一个对象数组时抛出的异常;
- NumberFormatException:当试图将字符串转换成数字时,失败了,抛出;
- IllegalArgumentException?抛出的异常表明向方法传递了一个不合法或不正确的参数。
- ArithmeticException当出现异常的运算条件时,抛出此异常。例如,一个整数“除以零”时,抛出此类的一个实例。?
?
上一篇:Java基础知识总结(绝对经典)
下一篇:Java面试题总结(绝对经典)
?

?
cs