目录
- 01直接生成
- 一、基础类型
- 1、月牙形数据集合
- 2、方形数据集
- 3、螺旋形数据集合
- 02样本生成器
- 一、基础数据集
- 1、点簇形数据集合
- 2、线簇形数据集合
- 3、环形数据集合
- 4、月牙数据集合
- 测试结论

01直接生成
这类方法是利用基本程序软件包numpy的随机数产生方法来生成各类用于聚类算法数据集合,也是自行制作轮子的生成方法。
一、基础类型
1、月牙形数据集合
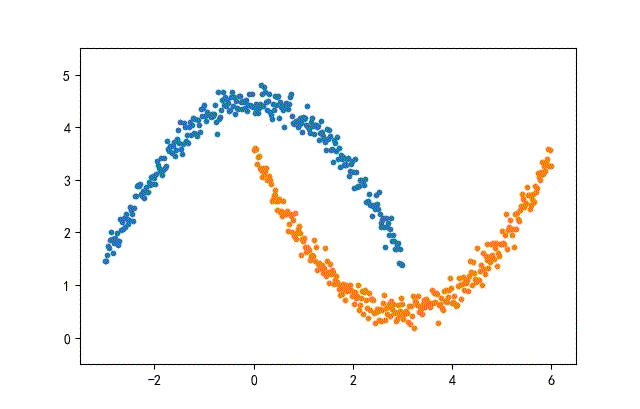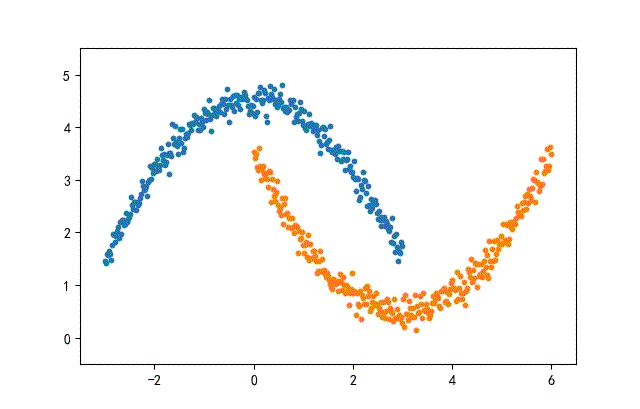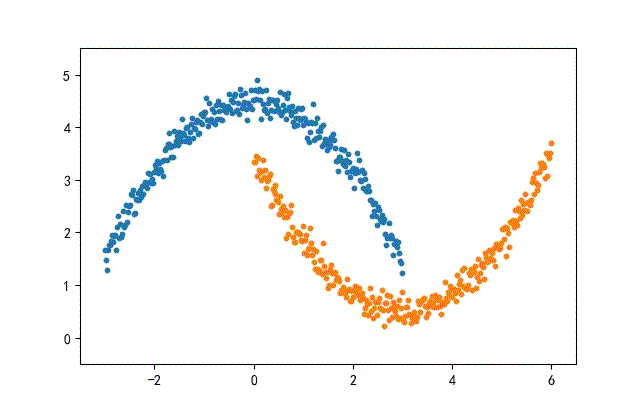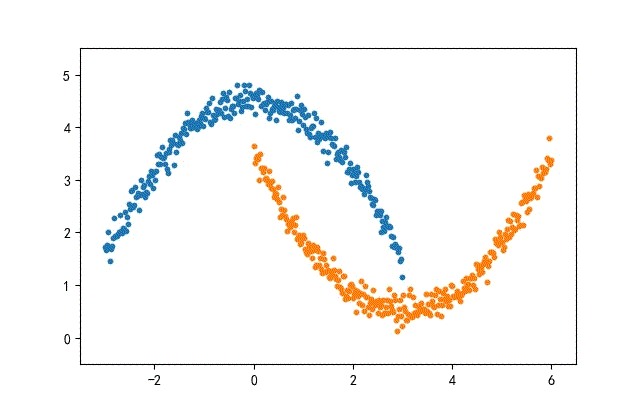
from headm import *
import numpy as np
pltgif = PlotGIF()
def moon2Data(datanum):
x1 = linspace(-3, 3, datanum)
noise = np.random.randn(datanum) * 0.15
y1 = -square(x1) / 3 + 4.5 + nois
x2 = linspace(0, 6, datanum)
noise = np.random.randn(datanum) * 0.15
y2 = square(x2 - 3) / 3 + 0.5 + noise
plt.clf()
plt.axis([-3.5, 6.5, -.5, 5.5])
plt.scatter(x1, y1, s=10)
plt.scatter(x2, y2, s=10)
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
moon2Data(300)
pltgif.save(r'd:\temp\GIF1.GIF')
2、方形数据集
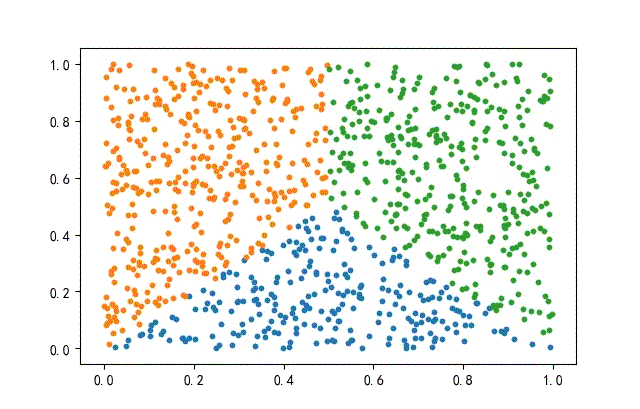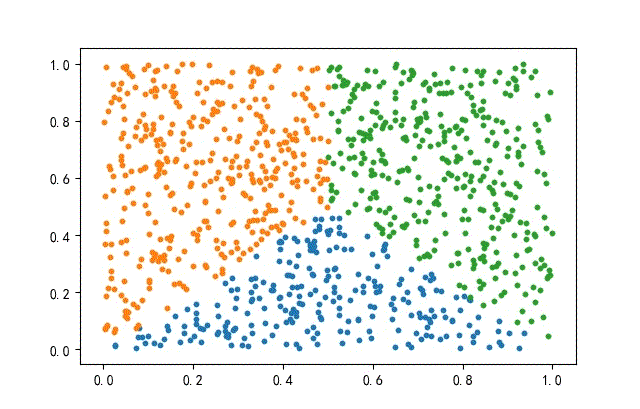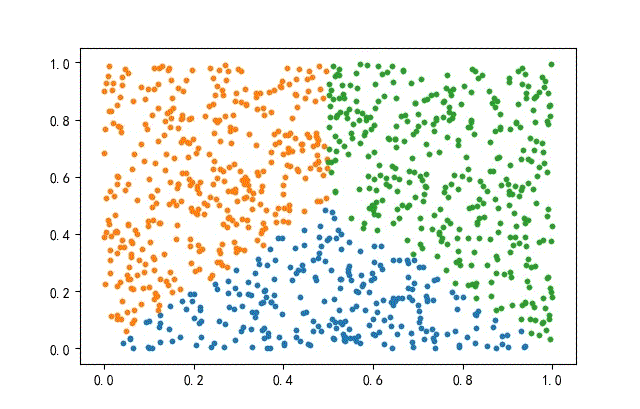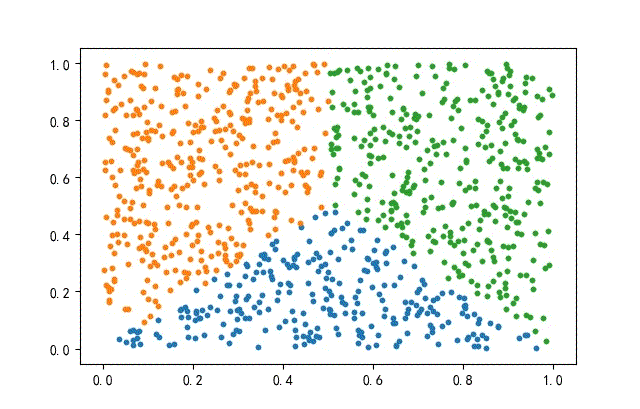
from headm import *
import numpy as np
pltgif = PlotGIF()
def moon2Data(datanum):
x = np.random.rand(datanum, 2)
condition1 = x[:, 1] <= x[:, 0]
condition2 = x[:, 1] <= (1-x[:, 0])
index1 = np.where(condition1 & condition2)
x1 = x[index1]
x = np.delete(x, index1, axis=0)
index2 = np.where(x[:, 0] <= 0.5)
x2 = x[index2]
x3 = np.delete(x, index2, axis=0)
plt.clf()
plt.scatter(x1[:, 0], x1[:, 1], s=10)
plt.scatter(x2[:, 0], x2[:, 1], s=10)
plt.scatter(x3[:, 0], x3[:, 1], s=10)
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
moon2Data(1000)
pltgif.save(r'd:\temp\GIF1.GIF')
3、螺旋形数据集合
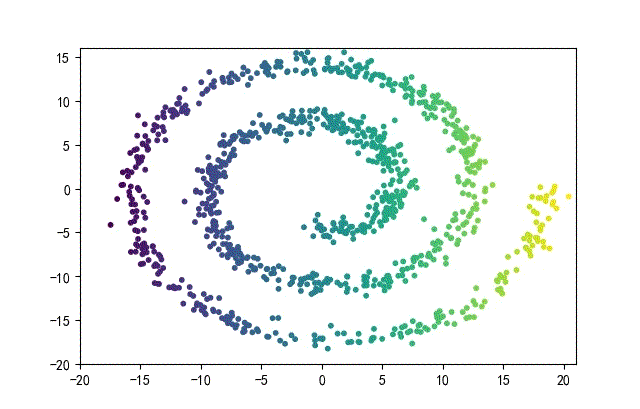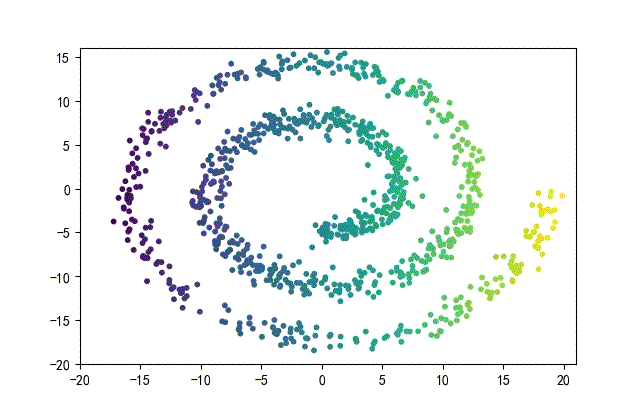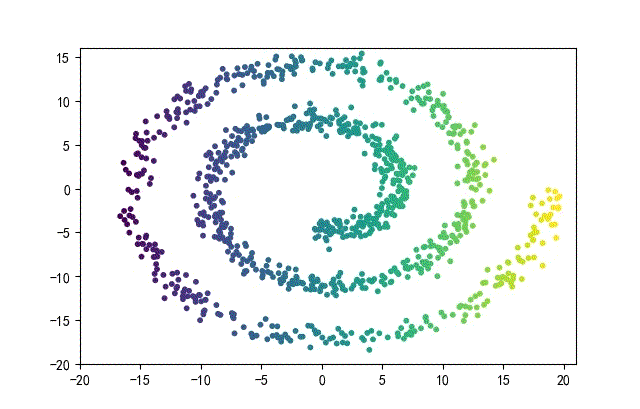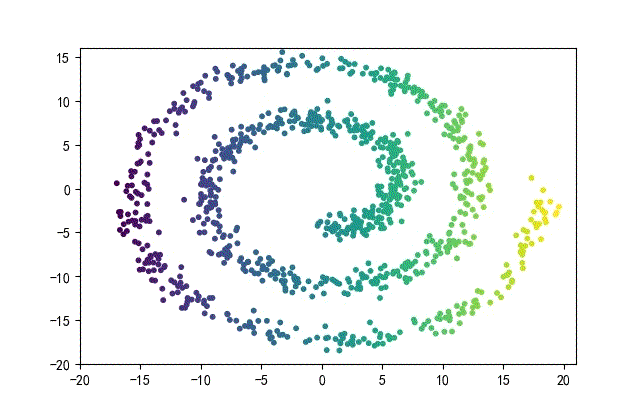
from headm import *
import numpy as np
pltgif = PlotGIF()
def randData(datanum):
t = 1.5 * pi * (1+3*random.rand(1, datanum))
x = t * cos(t)
y = t * sin(t)
X = concatenate((x,y))
X += 0.7 * random.randn(2, datanum)
X = X.T
norm = plt.Normalize(y.min(), y.max())
plt.clf()
plt.scatter(X[:, 0], X[:, 1], s=10, c=norm(X[:,0]), cmap='viridis')
plt.axis([-20, 21, -20, 16])
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
randData(1000)
pltgif.save(r'd:\temp\GIF1.GIF')
下面的知识螺旋线,没有随机移动的点。
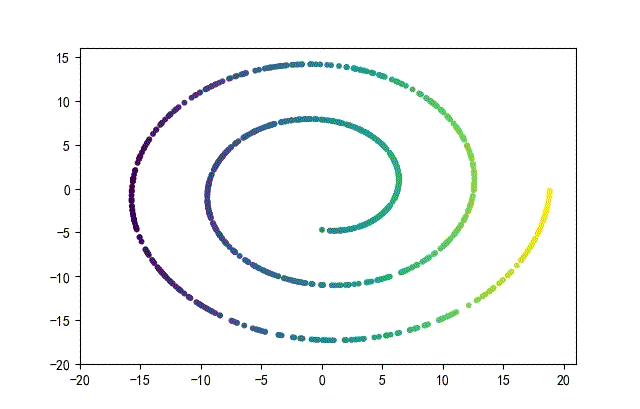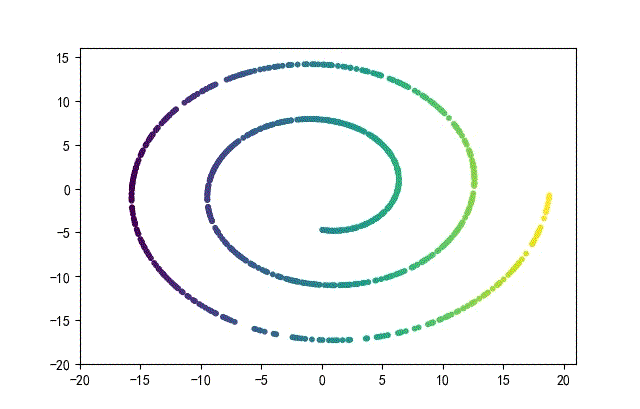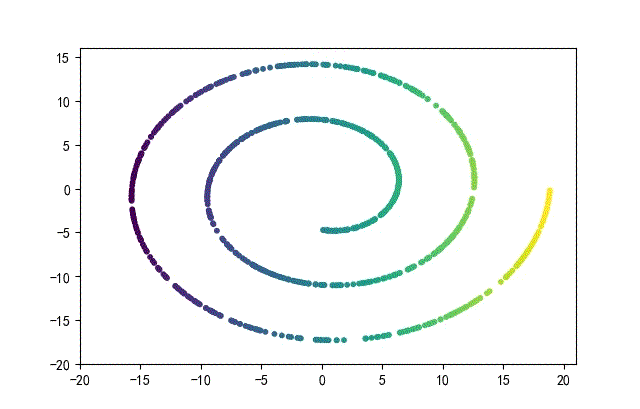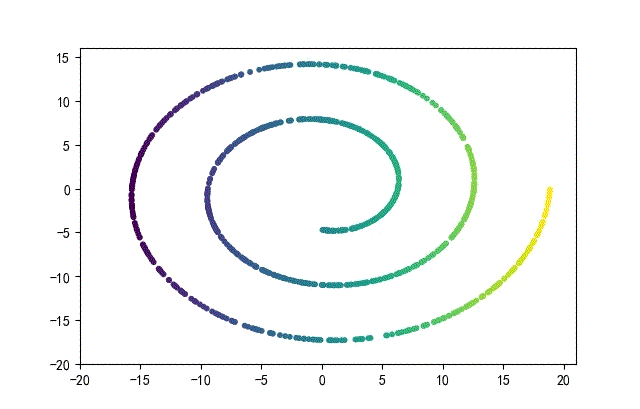
将随机幅值从原来的0.7增大到1.5,对应的数据集合为:
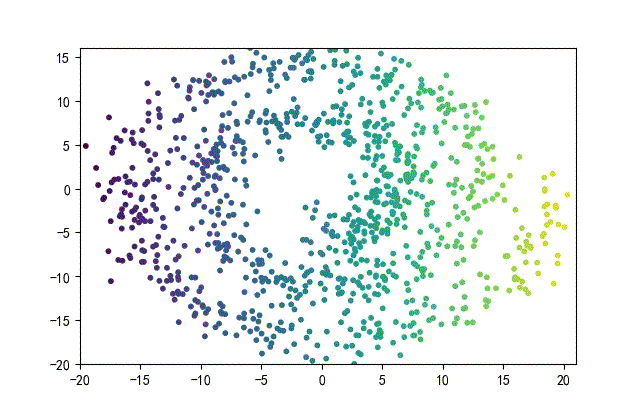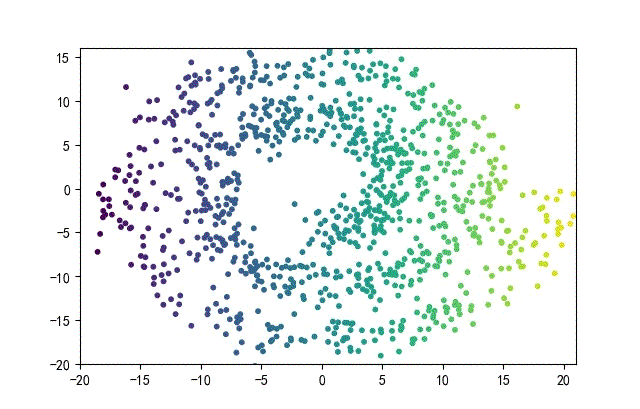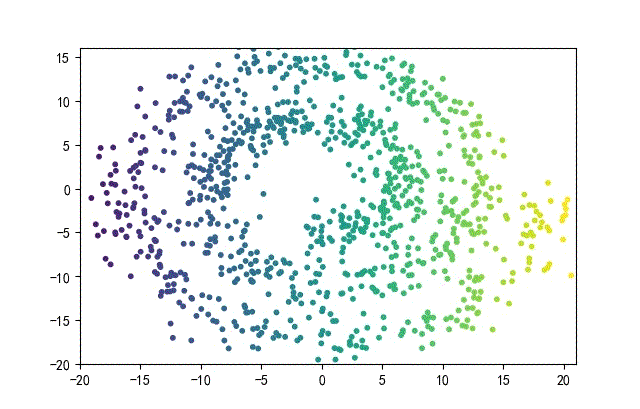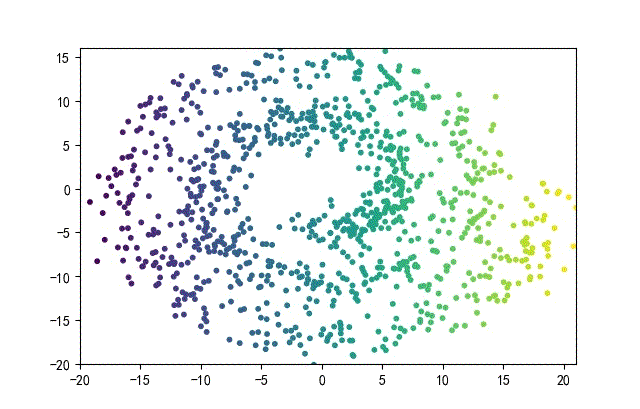
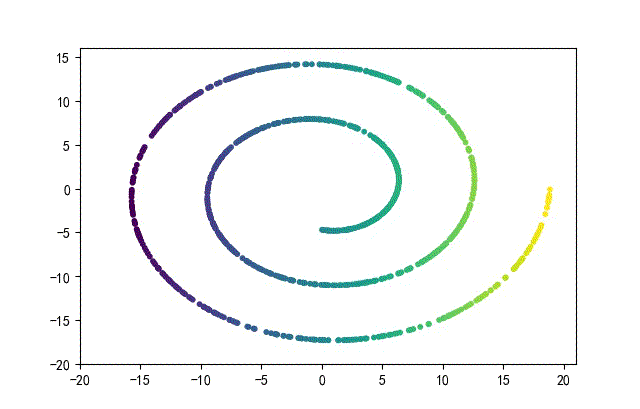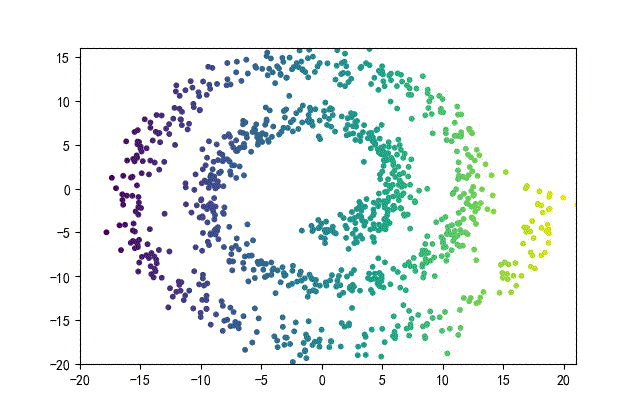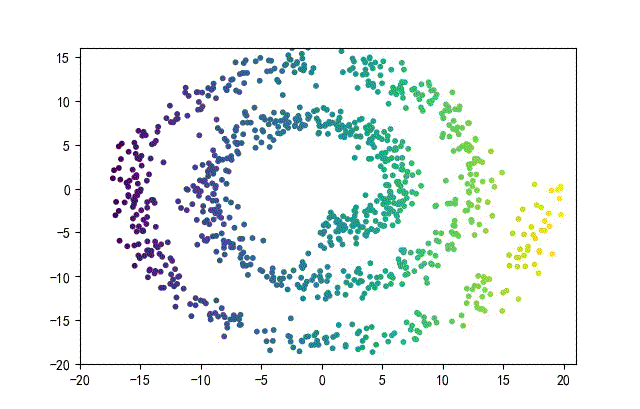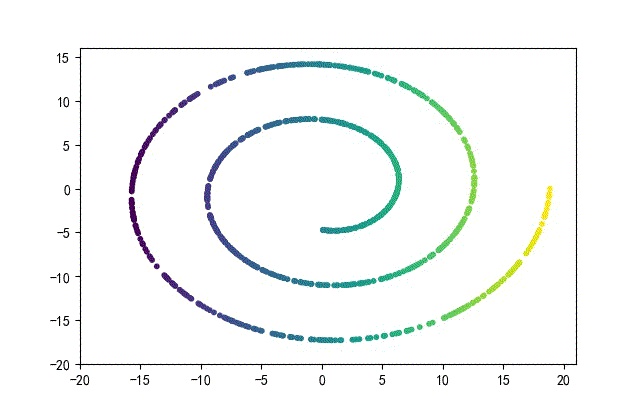
02样本生成器
利用sklearn.datasets自带的样本生成器来生成相应的数据集合。
一、基础数据集
1、点簇形数据集合
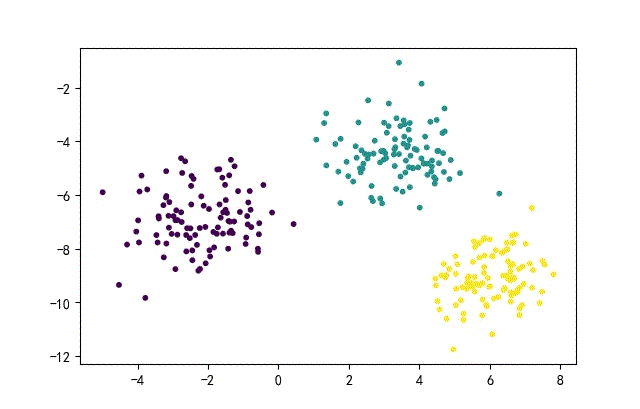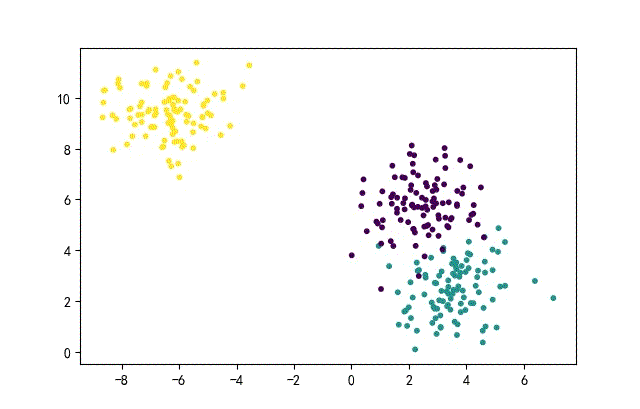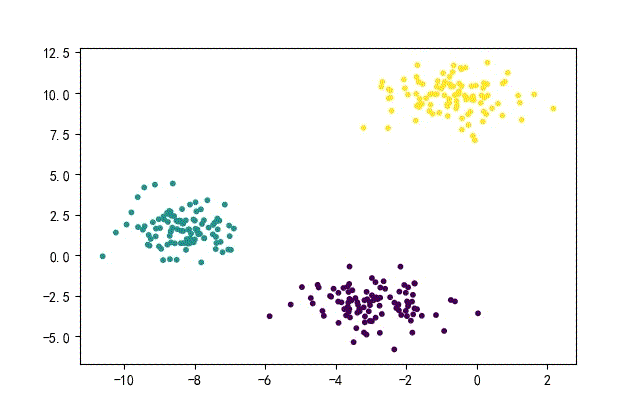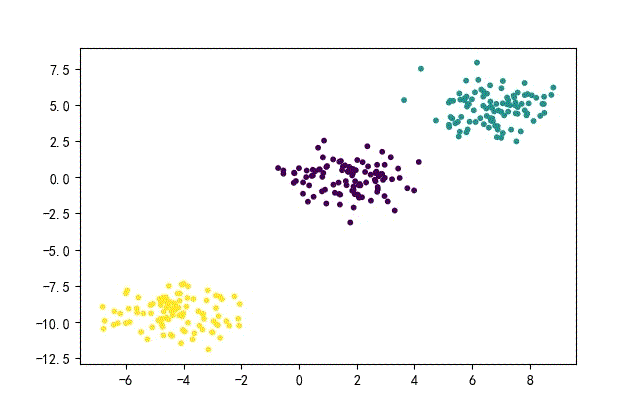
from headm import *
from sklearn.datasets import make_blobs
pltgif = PlotGIF()
def randData(datanum):
x1,y1 = make_blobs(n_samples=datanum, n_features=2, centers=3, random_state=random.randint(0, 1000))
plt.clf()
plt.scatter(x1[:,0], x1[:, 1], c=y1, s=10)
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
randData(300)
pltgif.save(r'd:\temp\gif1.gif')
绘制三簇点集合,也可以使用如下的语句:
plt.scatter(x1[y1==0][:,0], x1[y1==0][:,1], s=10)
plt.scatter(x1[y1==1][:,0], x1[y1==1][:,1], s=10)
plt.scatter(x1[y1==2][:,0], x1[y1==2][:,1], s=10)
2、线簇形数据集合
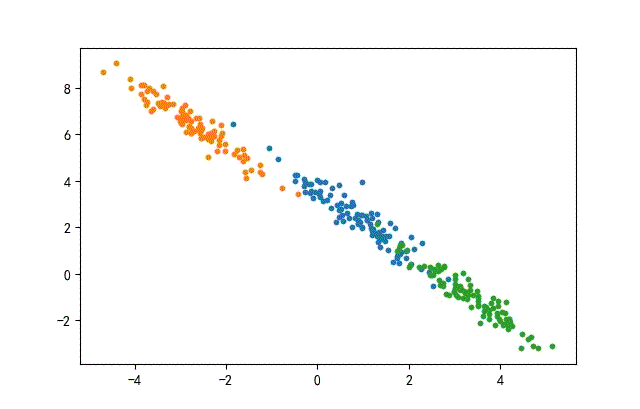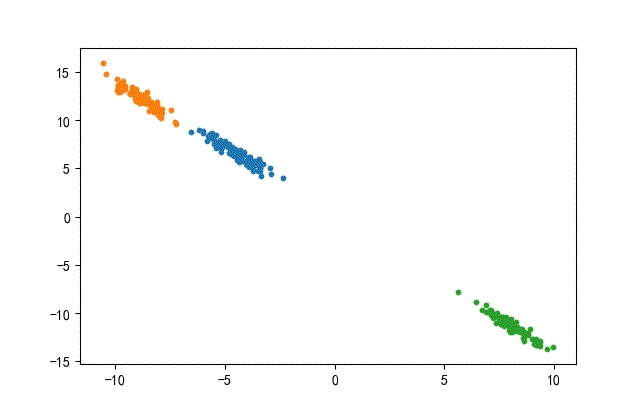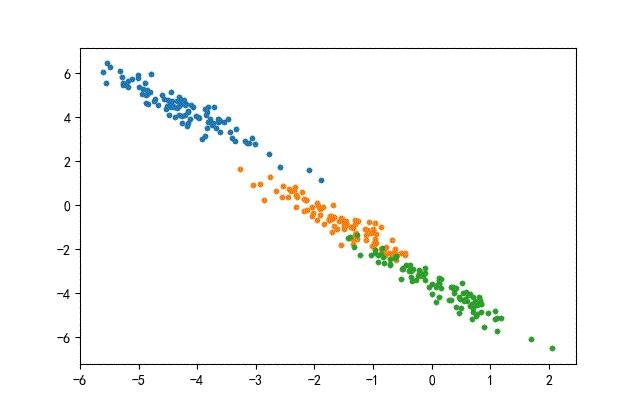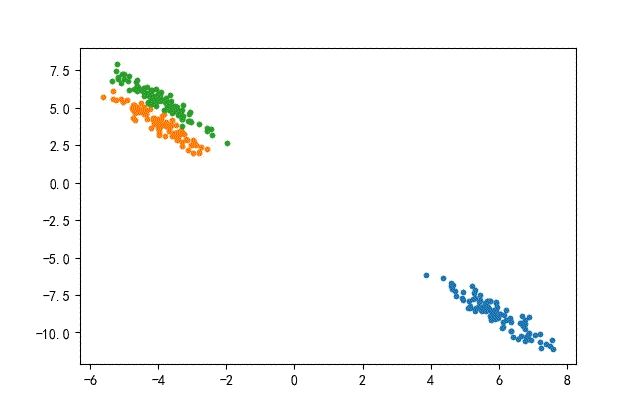
生成代码,只要在前面的x1后面使用旋转矩阵。
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
x1 = dot(x1, transformation)
其中转换矩阵的特征值与特征向量为:
- 特征值:[0.20581711.25506068]
- 特征向量:[[-0.845237740.7015526][-0.53439045-0.71261768]]
3、环形数据集合
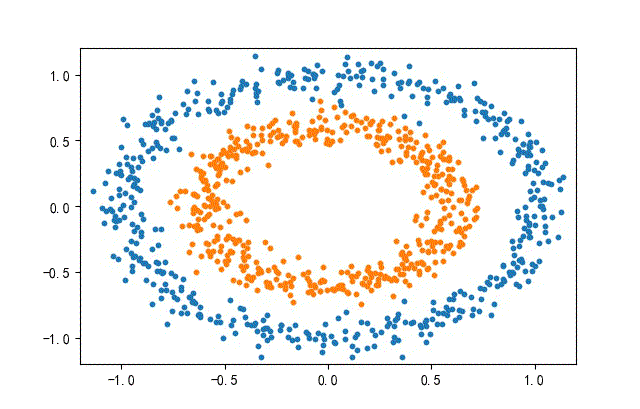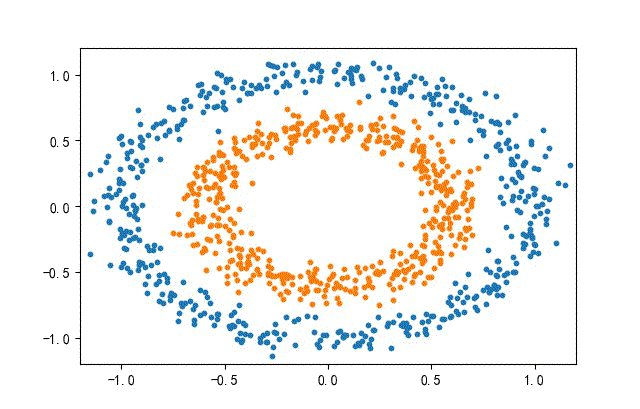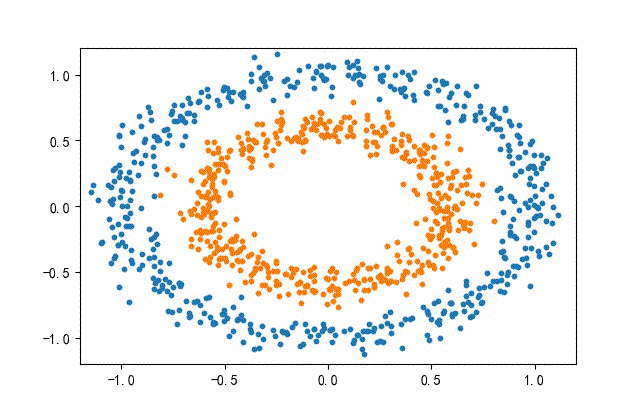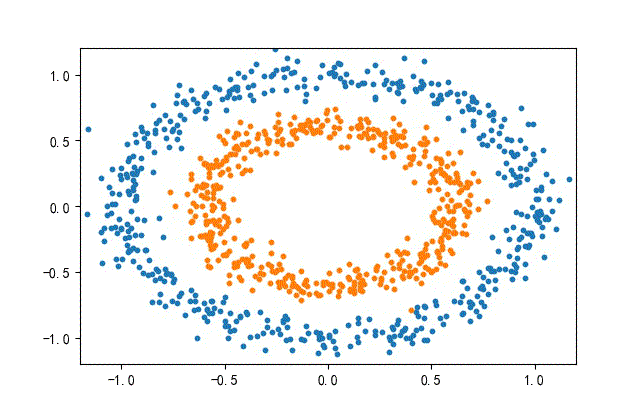
from headm import *
from sklearn.datasets import make_circles
pltgif = PlotGIF()
def randData(datanum):
x1,y1 = make_circles(n_samples=datanum, noise=0.07, random_state=random.randint(0, 1000), factor=0.6)
plt.clf()
plt.scatter(x1[y1==0][:,0], x1[y1==0][:,1], s=10)
plt.scatter(x1[y1==1][:,0], x1[y1==1][:,1], s=10)
plt.axis([-1.2, 1.2, -1.2, 1.2])
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
randData(1000)
pltgif.save(r'd:\temp\gif1.gif')
4、月牙数据集合
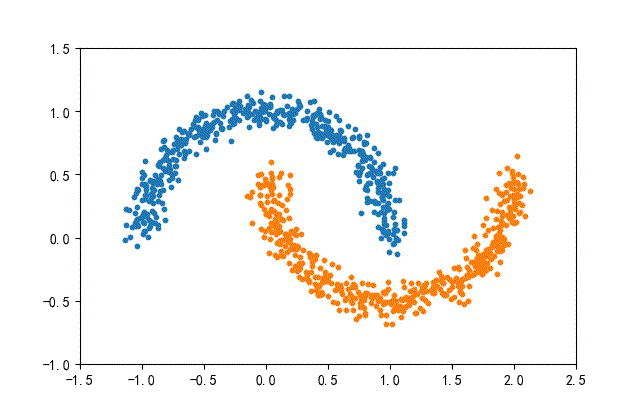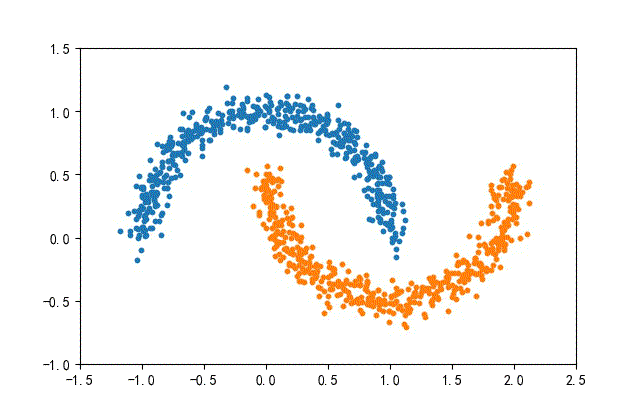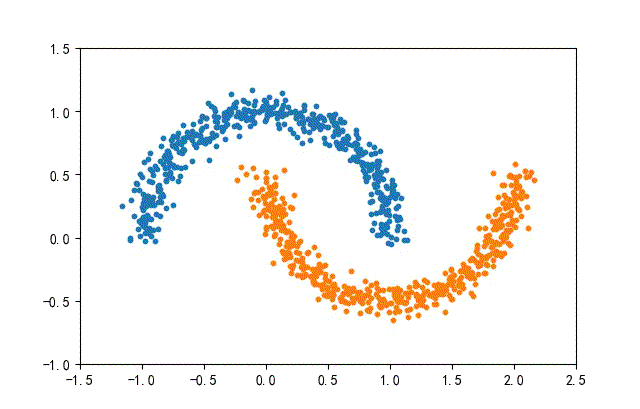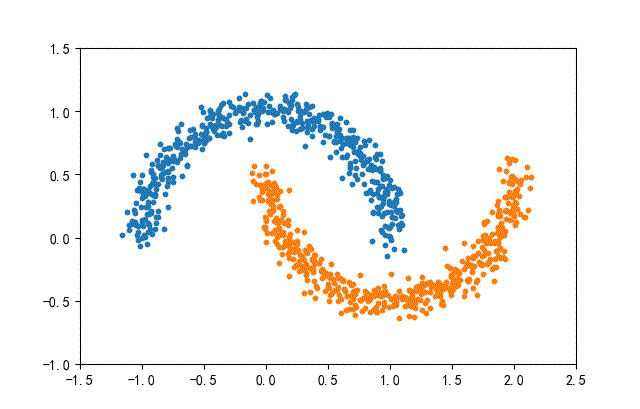
from headm import *
from sklearn.datasets import make_moons
pltgif = PlotGIF()
def randData(datanum):
x1,y1 = make_moons(n_samples=datanum, noise=0.07, random_state=random.randint(0, 1000))
plt.clf()
plt.scatter(x1[y1==0][:,0], x1[y1==0][:,1], s=10)
plt.scatter(x1[y1==1][:,0], x1[y1==1][:,1], s=10)
plt.axis([-1.5, 2.5, -1, 1.5])
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
randData(1000)
pltgif.save(r'd:\temp\gif1.gif')
测试结论
sklearn里面还有好多函数来自定制数据,除此之外还可以使用numpy生成,然后通过高级索引进行划分,最好结合着matplotlib中的cmap来做颜色映射,这样可以做出好玩又好看的数据集,希望大家以后多多支持站长博客!
jsjbwy