# encoding: utf-8
import json
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.charts import Radar
def draw_Radar():
from pyecharts.charts import Radar
radar = Radar()
# //由于雷达图传入的数据得为多维数据,所以这里需要做一下处理
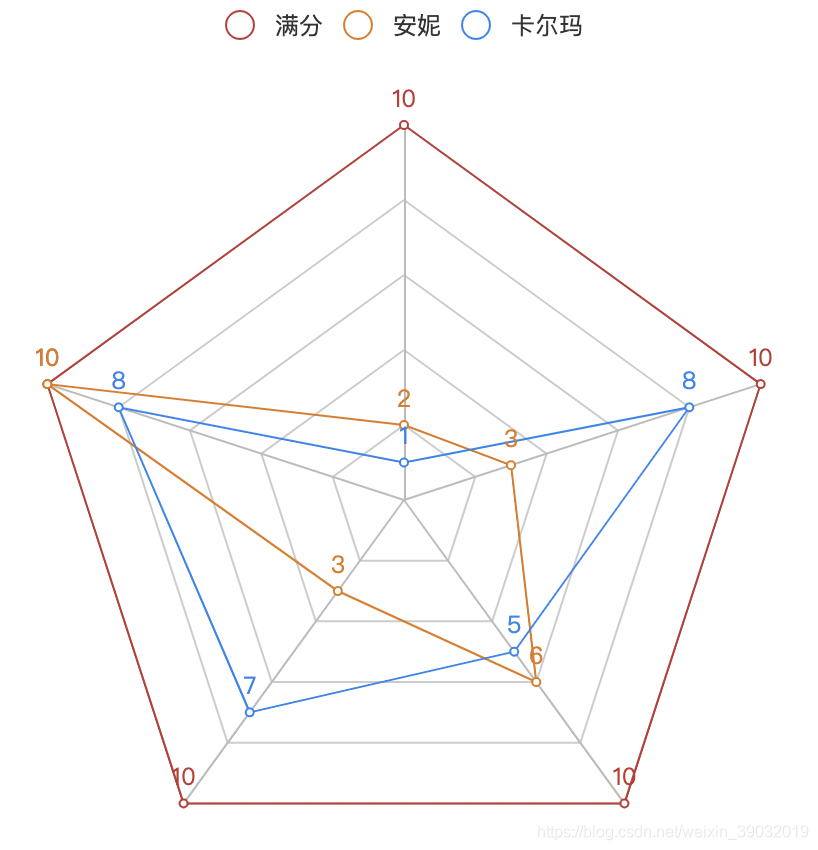
radar_data = [[10, 10, 10, 10, 10]]
radar_data1 = [[2, 10, 3, 6, 3]]
radar_data2 = [[1, 8, 7, 5, 8]]
# //设置column的最大值,为了雷达图更为直观,这里的月份最大值设置有所不同
schema = [
("物理", 100), ("魔法", 10), ("防御", 10),("难度", 10),("喜好", 10)
]
# //传入坐标
radar.add_schema(schema)
radar.add("满分", radar_data)
# //一般默认为同一种颜色,这里为了便于区分,需要设置item的颜色
radar.add("安妮", radar_data1, color="#E37911")
radar.add("卡尔玛", radar_data2, color="#1C86EE")
radar.render()
if __name__ == '__main__':
draw_Radar()
五、解析word(docx、doc)
依赖包:
# encoding: utf-8
import os, sys
import docx
def word_reader(file):
try:
# docx 直接读
if 'docx' in file:
res = ''
f = docx.Document(file)
for para in f.paragraphs:
res = res + '\n' +para.text
else:
# 先转格式doc>docx
os.system("textutil -convert docx '%s'"%file)
word_reader(file+'x')
res = ''
f = docx.Document(file+'x')
for para in f.paragraphs:
res = res + '\n' +para.text
return res
except:
# print(file, 'read failed')
return ''
六、计算器
math模块为浮点运算提供了对底层函数库的访问:
>>> import math
>>> math.cos(math.pi / 4)
0.70710678118654757
>>> math.log(1024, 2)
10.0
热门专栏推荐:
🥇 大数据集锦专栏:大数据-硬核学习资料 & 面试真题集锦?
🥈?数据仓库专栏:数仓发展史、建设方法论、实战经验、面试真题?
🥉?Python专栏:Python相关黑科技:爬虫、算法、小工具?
(优质好文持续更新中……)?

cs