🍅 作者主页:不吃西红柿
🍅 简介:CSDN博客专家🏆、信息技术智库公号作者?简历模板、PPT模板、技术资料尽管【关注】私聊我。历史文章目录:https://t.1yb.co/zHJo
🍅 欢迎点赞 👍 收藏 ?留言 📝 如有错误敬请指正!
本文重点:
1、爬虫获取csdn大佬之间的关系
2、可视化分析暧昧关系,复杂堪比娱乐圈
大佬简介
🍅 Java李杨勇:一个性感的计算机专业毕业的3年java开发者。
🍅 沉默王二:CSDN 头牌博主,Java 领域优质创作者,2019、2020 两届博客之星 Top5?。
🍅 擦姐yyds:现象级专栏 《Python 爬虫 100 例》作者、《滚雪球学 Python 专栏》原创者。
🍅 涛歌依旧:涛哥不知何许人也,亦不详其姓字。闲静少言,不慕荣利。好读书,求甚解。
🍅 Lucifer三思而后行:灵感来源于生活,故而热爱生活~
🍅 曲鸟:python领域新星创作者。
🍅 孤寒者:深入浅出的讲解Python基础知识&爬虫初阶及进阶&主流Web框架(Django等)
🍅 肥学大师:目前还是学生喜欢分享从每个项目得到的技术和趣闻类的文章。
不甚枚举......
目录
效果展示(动图不会录屏,只能截图了)
第一步:获取api
第二步:爬虫获取关注名单
第三步:python数据可视化
第四步:main函数启动
效果展示(动图不会录屏,只能截图了)
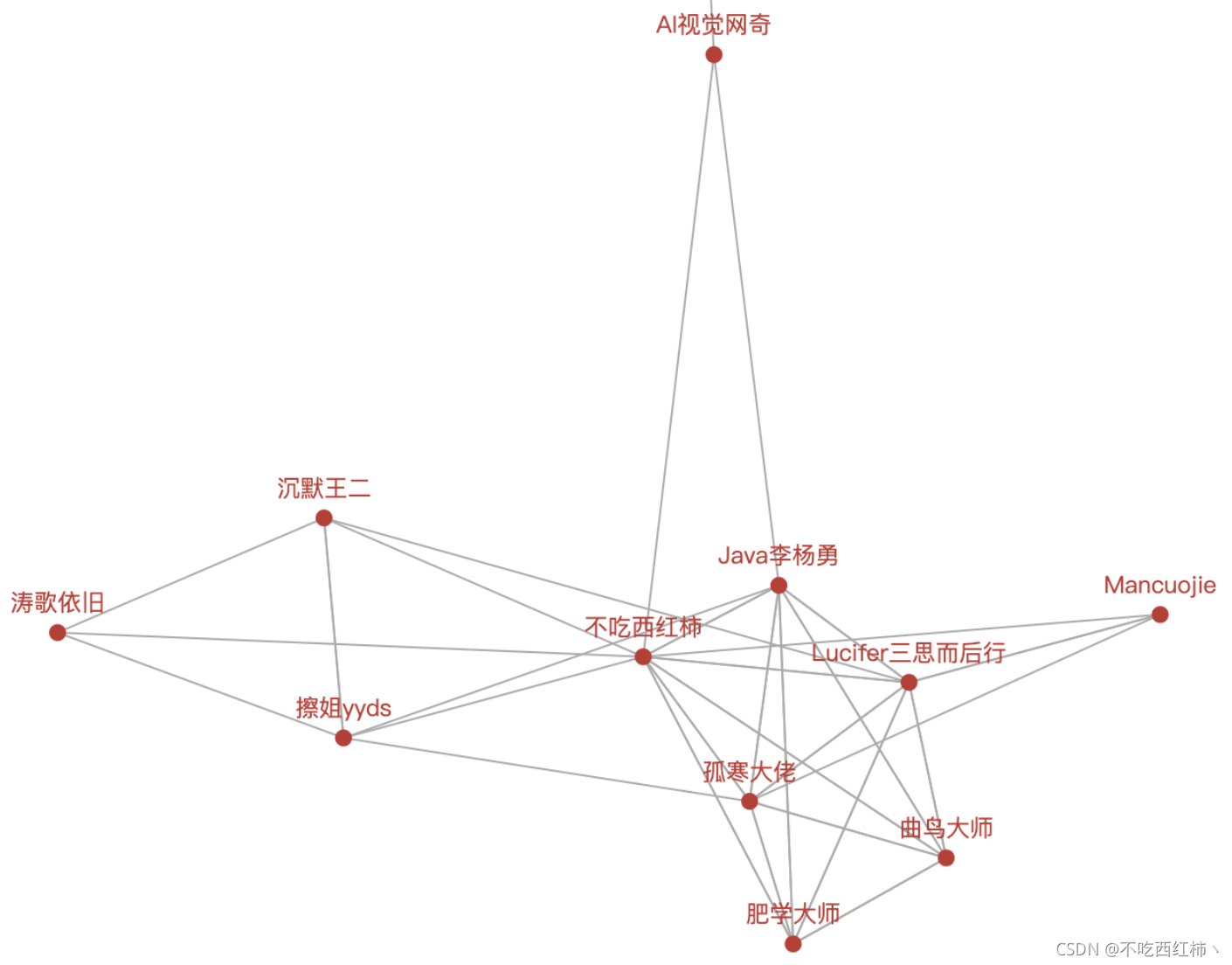
我们尤其可以看到:
这个「不吃西红柿」竟然关注了所有人,简直是朵交际花,不仅文章写得好,还爱交朋友! 据说,他最近有评论必回关? ?
第一步:获取api

C站的关注api:
https://blog.csdn.net/community/home-api/v1/get-follow-list?page=%s&size=20&noMore=false&blogUsername=%s"%(p,Username)
需要传入两个参数:页数、用户id
%(p,Username)
第二步:爬虫获取关注名单
还是经典的爬虫包: import requests
def get_follow(Username):
headers = {
"User-Agent": "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)",
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"cookie": "cookie",
}
data ={
"page": "1",
"size": "20",
"noMore": "false",
"blogUsername": Username
}
follow_list = []
for p in range(1,101):
url = "https://blog.csdn.net/community/home-api/v1/get-follow-list?page=%s&size=20&noMore=false&blogUsername=%s"%(p,Username)
res = requests.get(url,headers=headers,data=data)
fans = json.loads(res.text)['data']['list']
if fans:
follow_list.extend(fans)
else:
break
ff = []
for i in follow_list:
ff.append(i['username'])
return ff
第三步:python数据可视化
def graph(nodes, links):
graph = Graph()
graph.add("Name:", nodes,links, repulsion=8000)
graph.set_global_opts(title_opts=opts.TitleOpts("关系图"))
graph.render() #生成render.html
第四步:main函数启动
if __name__ == '__main__':
nodes,links = [],[]
blog = {
'weixin_39032019': '不吃西红柿',
'Mancuojie':'Mancuojie',
'weixin_39709134': 'Java李杨勇',
'zhongguomao': 'SAP剑客',
'qing_gee': '沉默王二',
'hihell': '擦姐yyds',
'stpeace': '涛歌依旧',
'jacke121': 'AI视觉网奇',
'weixin_40400177': 'DrogoZhang',
'm0_50546016': 'Lucifer三思而后行',
'momoda118': '曲鸟大师',
'qq_44907926': '孤寒大佬',
'jiahuiandxuehui': '肥学大师',
}
blog_key = blog.keys()
for blogUsername in blog:
follows = get_follow(blogUsername)
simple_follows = [val for val in follows if val in blog_key]
nodes.append({"name": blog[blogUsername] })
for one in simple_follows:
if blog[blogUsername] != blog[one]:
links.append({"source": blog[blogUsername] ,"target":blog[one] })
print(links)
graph(nodes,links)
好了,今天的「爬虫」和「数据可视化」小课堂,就到这里了,我是西红柿🍅,我们下期再见~
热门专栏推荐:
🥇 大数据集锦专栏:大数据-硬核学习资料 & 面试真题集锦?
🥈?数据仓库专栏:数仓发展史、建设方法论、实战经验、面试真题?
🥉?Python专栏:Python相关黑科技:爬虫、算法、小工具?
(优质好文持续更新中……)?

cs