7.MysqlЪ§ОнПтБэв§ЧцгызжЗћМЏ
1.ЗўЮёЦїДІРэПЭЛЇЖЫЧыЧѓ
ЦфЪЕВЛТлПЭЛЇЖЫНјГЬКЭЗўЮёЦїНјГЬЪЧВЩгУФФжжЗНЪННјааЭЈаХ,зюКѓЪЕЯжЕФаЇЙћЖМЪЧ:ПЭЛЇЖЫНјГЬЯђЗўЮёЦїНјГЬЗЂЫЭ
вЛЖЮЮФБО(MySQLгяОф),ЗўЮёЦїНјГЬДІРэКѓдйЯђПЭЛЇЖЫНјГЬЗЂЫЭвЛЖЮЮФБО(ДІРэНсЙћ)ЁЃФЧЗўЮёЦїНјГЬЖдПЭЛЇ
ЖЫНјГЬЗЂЫЭЕФЧыЧѓзіСЫЪВУДДІРэ,ВХФмВњЩњзюКѓЕФДІРэНсЙћФи?ПЭЛЇЖЫПЩвдЯђЗўЮёЦїЗЂЫЭдіЩОИФВщИїРрЧыЧѓ,ЮвУЧ
етРявдБШНЯИДдгЕФВщбЏЧыЧѓЮЊР§РДЛИіЭМеЙЪОвЛЯТДѓжТЕФЙ§ГЬ:
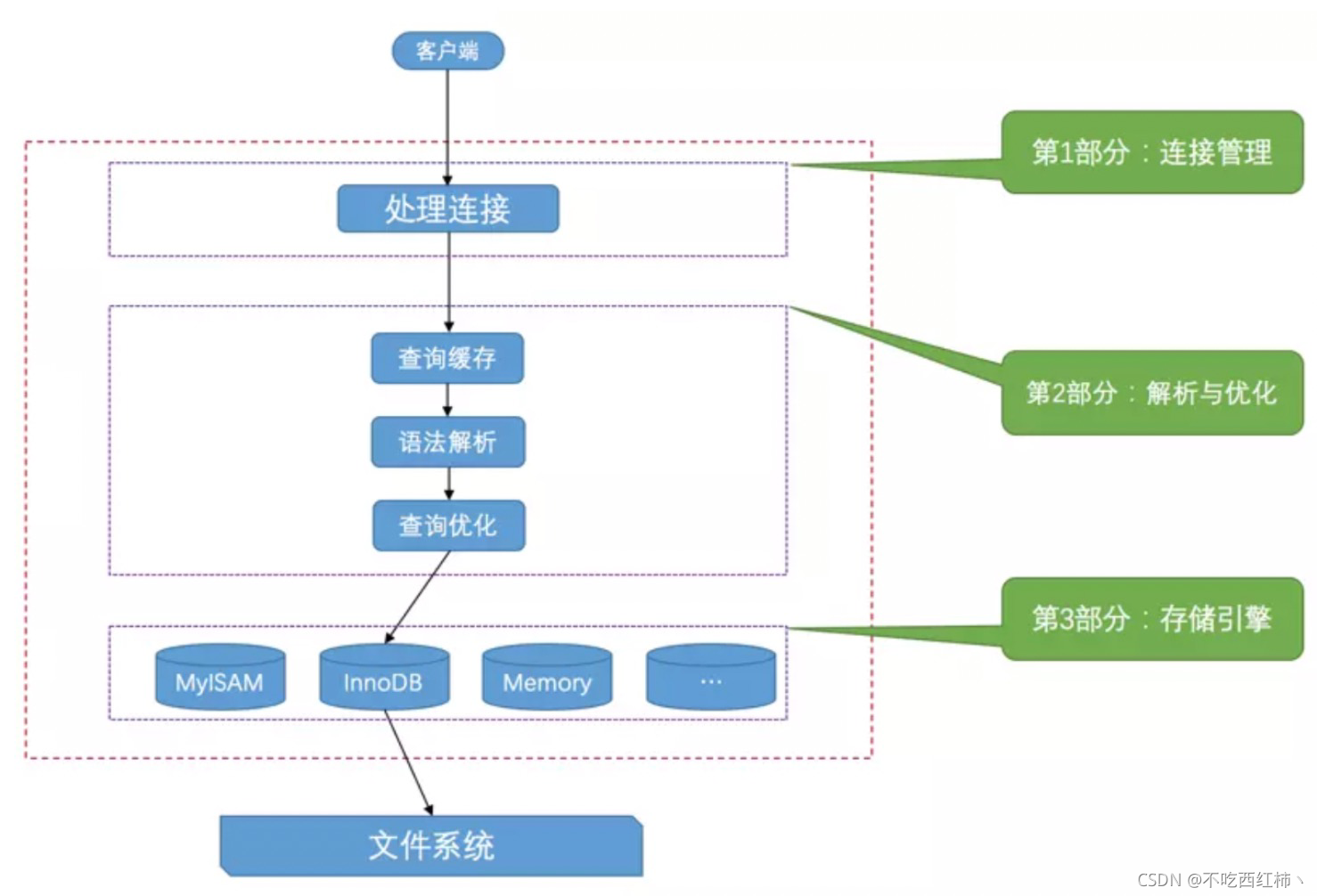
ЫфШЛВщбЏЛКДцгаЪБПЩвдЬсЩ§ЯЕЭГадФм,ЕЋвВВЛЕУВЛвђЮЌЛЄетПщЛКДцЖјдьГЩвЛаЉПЊЯњ,БШШчУПДЮЖМвЊШЅВщбЏЛК
ДцжаМьЫї,ВщбЏЧыЧѓДІРэЭъашвЊИќаТВщбЏЛКДц,ЮЌЛЄИУВщбЏЛКДцЖдгІЕФФкДцЧјгђЁЃДгMySQL 5.7.20ПЊЪМ,ВЛ
ЭЦМіЪЙгУВщбЏЛКДц,ВЂдкMySQL 8.0жаЩОГ§ЁЃ
2.ДцДЂв§Чц
MySQL?ЗўЮёЦїАбЪ§ОнЕФДцДЂКЭЬсШЁВйзїЖМЗтзАЕНСЫвЛИіНа?ДцДЂв§Чц?ЕФФЃПщРяЁЃЮвУЧжЊЕР?Бэ?ЪЧгЩвЛаавЛааЕФМЧТМзщГЩЕФ,ЕЋетжЛЪЧвЛИіТпМЩЯЕФИХФю,ЮяРэЩЯШчКЮБэЪОМЧТМ,дѕУДДгБэжаЖСШЁЪ§Он,дѕУДАбЪ§ОнаДШыОпЬхЕФЮяРэДцДЂЦїЩЯ,етЖМЪЧ?ДцДЂв§Чц?ИКд№ЕФЪТЧщЁЃЮЊСЫЪЕЯжВЛЭЌЕФЙІФм,?MySQL?ЬсЙЉСЫИїЪНИїбљЕФ?ДцДЂв§Чц?,ВЛЭЌ?ДцДЂв§Чц?ЙмРэЕФБэОпЬхЕФДцДЂНсЙЙПЩФмВЛЭЌ,ВЩгУЕФДцШЁЫуЗЈвВПЩФмВЛЭЌЁЃ
ДцДЂв§ЧцвдЧАНазі?БэДІРэЦї?,ЫќЕФЙІФмОЭЪЧНгЪеЩЯВуДЋЯТРДЕФжИСю,ШЛКѓЖдБэжаЕФЪ§ОнНјааЬсШЁЛђаДШыВйзїЁЃ
ЮЊСЫЙмРэЗНБу,ШЫУЧАб?СЌНгЙмРэ?ЁЂ?ВщбЏЛКДц?ЁЂ?гяЗЈНтЮі?ЁЂ?ВщбЏгХЛЏ?етаЉВЂВЛЩцМАецЪЕЪ§ОнДцДЂЕФЙІФмЛЎЗжЮЊMySQL server?ЕФЙІФм,АбецЪЕДцШЁЪ§ОнЕФЙІФмЛЎЗжЮЊ?ДцДЂв§Чц?ЕФЙІФмЁЃИїжжВЛЭЌЕФДцДЂв§ЧцЯђЩЯБпЕФ?MySQLserver?ВуЬсЙЉЭГвЛЕФЕїгУНгПк(вВОЭЪЧДцДЂв§ЧцAPI),АќКЌСЫМИЪЎИіЕзВуКЏЪ§,Яё"ЖСШЁЫїв§ЕквЛЬѕФкШн"ЁЂ"ЖСШЁЫїв§ЯТвЛЬѕФкШн"ЁЂ"ВхШыМЧТМ"ЕШЕШЁЃ
Ыљвддк?MySQL server?ЭъГЩСЫВщбЏгХЛЏКѓ,жЛашАДееЩњГЩЕФжДааМЦЛЎЕїгУЕзВуДцДЂв§ЧцЬсЙЉЕФAPI,ЛёШЁЕНЪ§ОнКѓЗЕЛиИјПЭЛЇЖЫОЭКУСЫЁЃ
MySQL?жЇГжЗЧГЃЖржжДцДЂв§Чц:
ARCHIVE?гУгкЪ§ОнДцЕЕ(ааБЛВхШыКѓВЛФмдйаоИФ)
BLACKHOLE?ЖЊЦњаДВйзї,ЖСВйзїЛсЗЕЛиПеФкШн
CSV?дкДцДЂЪ§ОнЪБ,вдЖККХЗжИєИїИіЪ§ОнЯю
FEDERATED?гУРДЗУЮЪдЖГЬБэ
InnoDB?ОпБИЭтМќжЇГжЙІФмЕФЪТЮёДцДЂв§Чц
MEMORY?жУгкФкДцЕФБэ
MERGE?гУРДЙмРэЖрИіMyISAMБэЙЙГЩЕФБэМЏКЯ
MyISAM?жївЊЕФЗЧЪТЮёДІРэДцДЂв§Чц
NDB?MySQLМЏШКзЈгУДцДЂв§Чц
3.MyISAMКЭInnoDBБэв§ЧцЕФЧјБ№
1)?ЪТЮёжЇГж
MyISAMВЛжЇГжЪТЮё,ЖјInnoDBжЇГжЁЃ
ЪТЮё:ЗУЮЪВЂИќаТЪ§ОнПтжаЪ§ОнЕФжДааЕЅдЊЁЃЪТЮяВйзїжа,вЊУДЖМжДаавЊУДЖМВЛжДаа
2)?ДцДЂНсЙЙ
MyISAM:УПИіMyISAMдкДХХЬЩЯДцДЂГЩШ§ИіЮФМўЁЃ
- .frmЮФМўДцДЂБэНсЙЙЁЃ
- .MYDЮФМўДцДЂЪ§ОнЁЃ
- .MYIЮФМўДцДЂЫїв§ЁЃ
InnoDB:жївЊЗжЮЊСНжжЮФМўНјааДцДЂ
- .frm?ДцДЂБэНсЙЙ
- .ibd?ДцДЂЪ§ОнКЭЫїв§?(вВПЩФмЪЧЖрИі.ibdЮФМў,ЛђепЪЧЖРСЂЕФБэПеМфЮФМў)
3)?БэЫјВювь
MyISAM:жЛжЇГжБэМЖЫј,гУЛЇдкВйзїmyisamБэЪБ,select,update,delete,insertгяОфЖМЛсИјБэздЖЏМгЫј,ШчЙћМгЫјвдКѓЕФБэТњзуinsertВЂЗЂЕФЧщПіЯТ,ПЩвддкБэЕФЮВВПВхШыаТЕФЪ§ОнЁЃ
?InnoDB:жЇГжЪТЮёКЭааМЖЫј,ЪЧinnodbЕФзюДѓЬиЩЋЁЃ
ааЫјДѓЗљЖШЬсИпСЫЖргУЛЇВЂЗЂВйзїЕФаТФмЁЃЕЋЪЧInnoDBЕФааЫј,жЛЪЧдкWHEREЕФжїМќЪЧгааЇЕФ,ЗЧжїМќЕФWHEREЖМЛсЫјШЋБэЕФЁЃ
4)?БэжїМќ
MyISAM:дЪаэУЛгаШЮКЮЫїв§КЭжїМќЕФБэДцдк,Ыїв§ЖМЪЧБЃДцааЕФЕижЗЁЃ?InnoDB:ШчЙћУЛгаЩшЖЈжїМќЛђепЗЧПеЮЈвЛЫїв§,ОЭЛсздЖЏЩњГЩвЛИі6зжНкЕФжїМќ(гУЛЇВЛПЩМћ),Ъ§ОнЪЧжїЫїв§ЕФвЛВПЗж,ИНМгЫїв§БЃДцЕФЪЧжїЫїв§ЕФжЕЁЃ
InnoDBЕФжїМќЗЖЮЇИќДѓ,зюДѓЪЧMyISAMЕФ2БЖЁЃ
5)?БэЕФОпЬхааЪ§
MyISAM:БЃДцгаБэЕФзмааЪ§,ШчЙћselect count() from table;ЛсжБНгШЁГіГіИУжЕЁЃ?InnoDB:УЛгаБЃДцБэЕФзмааЪ§
(жЛФмБщРњ),ШчЙћЪЙгУselect count() from table;ОЭЛсБщРњећИіБэ,ЯћКФЯрЕБДѓ,ЕЋЪЧдкМгСЫwehreЬѕМўКѓ,
myisamКЭinnodbДІРэЕФЗНЪНЖМвЛбљЁЃ
6) CURDВйзї
MyISAM:ШчЙћжДааДѓСПЕФSELECT,MyISAMЪЧИќКУЕФбЁдёЁЃ?InnoDB:ШчЙћФуЕФЪ§ОнжДааДѓСПЕФINSERTЛђUPDATE,ГігкадФмЗНУцЕФПМТЧ,гІИУЪЙгУInnoDBБэЁЃDELETE?ДгадФмЩЯInnoDBИќгХ,ЕЋDELETE FROM tableЪБ,InnoDBВЛЛсжиаТНЈСЂБэ,ЖјЪЧвЛаавЛааЕФЩОГ§,дкinnodbЩЯШчЙћвЊЧхПеБЃДцгаДѓСПЪ§ОнЕФБэ,зюКУЪЙгУtruncate tableетИіУќСюЁЃ
7)?ЭтМќ
MyISAM:ВЛжЇГж?InnoDB:жЇГж
8)?ВщбЏаЇТЪ
MyISAMЯрЖдМђЕЅ,ЫљвддкаЇТЪЩЯвЊгХгкInnoDB,аЁаЭгІгУПЩвдПМТЧЪЙгУMyISAMЁЃ
ЭЦМіПМТЧЪЙгУInnoDBРДЬцДњMyISAMв§Чц,двђЪЧInnoDBздЩэКмЖрСМКУЕФЬиЕу,БШШчЪТЮёжЇГжЁЂДцДЂ?Й§ГЬЁЂЪгЭМЁЂааМЖЫјЖЈЕШЕШ,дкВЂЗЂКмЖрЕФЧщПіЯТ,ЯраХInnoDBЕФБэЯжПЯЖЈвЊБШMyISAMЧПКмЖрЁЃ
СэЭт,ШЮКЮвЛжжБэЖМВЛЪЧЭђФмЕФ,жЛгУЧЁЕБЕФеыЖдвЕЮёРраЭРДбЁдёКЯЪЪЕФБэРраЭ,ВХФмзюДѓЕФЗЂЛгMySQLЕФадФмгХЪЦЁЃШчЙћВЛЪЧКмИДдгЕФWebгІгУ,ЗЧЙиМќгІгУ,ЛЙЪЧПЩвдМЬајПМТЧMyISAMЕФ,етИіОпЬхЧщПіПЩвдздМКехзУЁЃ
9)MyISAMКЭInnoDBСНепЕФгІгУГЁОА
MyISAMЙмРэЗЧЪТЮёБэЁЃЫќЬсЙЉИпЫйДцДЂКЭМьЫї,вдМАШЋЮФЫбЫїФмСІЁЃШчЙћгІгУжаашвЊжДааДѓСПЕФSELECTВщбЏ,ФЧУДMyISAMЪЧИќКУЕФбЁдёЁЃ?InnoDBгУгкЪТЮёДІРэгІгУГЬађ,ОпгажкЖрЬиад,АќРЈACIDЪТЮёжЇГжЁЃШчЙћгІгУжаашвЊжДааДѓСПЕФINSERTЛђUPDATEВйзї,дђгІИУЪЙгУInnoDB,етбљПЩвдЬсИпЖргУЛЇВЂЗЂВйзїЕФадФмЁЃЯждкФЌШЯЪЙгУInnoDBЁЃ
4.СЫНтвЛЯТзжЗћМЏКЭТвТы
зжЗћМЏМђНщ
ЮвУЧжЊЕРдкМЦЫуЛњжажЛФмДцДЂЖўНјжЦЪ§Он,ФЧИУдѕУДДцДЂзжЗћДЎФи?ЕБШЛЪЧНЈСЂзжЗћгыЖўНјжЦЪ§ОнЕФгГЩфЙиЯЕСЫ,
НЈСЂетИіЙиЯЕзюЦ№ТывЊИуЧхГўСНМўЪТЖљ:
1.?ФувЊАбФФаЉзжЗћгГЩфГЩЖўНјжЦЪ§Он?
вВОЭЪЧНчЖЈЧхГўзжЗћЗЖЮЇЁЃ
2.?дѕУДгГЩф?
НЋвЛИізжЗћгГЩфГЩвЛИіЖўНјжЦЪ§ОнЕФЙ§ГЬвВНазі?БрТы?,НЋвЛИіЖўНјжЦЪ§ОнгГЩфЕНвЛИізжЗћЕФЙ§ГЬНазі?НтТы?ЁЃШЫУЧГщЯѓГівЛИі?зжЗћМЏ?ЕФИХФюРДУшЪіФГИізжЗћЗЖЮЇЕФБрТыЙцдђ
ЮвУЧПДвЛЯТвЛаЉГЃгУзжЗћМЏЕФЧщПі:
ASCII?зжЗћМЏ
ЙВЪеТМ128ИізжЗћ,АќРЈПеИёЁЂБъЕуЗћКХЁЂЪ§зжЁЂДѓаЁаДзжФИКЭвЛаЉВЛПЩМћзжЗћЁЃгЩгкзмЙВВХ128ИізжЗћ,ЫљвдПЩвдЪЙгУ1ИізжНкРДНјааБрТы,ЮвУЧПДвЛаЉзжЗћЕФБрТыЗНЪН:
- 'L' -> 01001100(ЪЎСљНјжЦ:0x4C,ЪЎНјжЦ:76)
- 'M' -> 01001101(ЪЎСљНјжЦ:0x4D,ЪЎНјжЦ:77)
ISO 8859-1?зжЗћМЏ
ЙВЪеТМ256ИізжЗћ,ЪЧдк?ASCII?зжЗћМЏЕФЛљДЁЩЯгжРЉГфСЫ128ИіЮїХЗГЃгУзжЗћ(АќРЈЕТЗЈСНЙњЕФзжФИ),вВПЩвдЪЙгУ1ИізжНкРДНјааБрТыЁЃетИізжЗћМЏвВгавЛИіБ№Ућ?latin1?ЁЃ
GB2312?зжЗћМЏ
ЪеТМСЫККзжвдМАРЖЁзжФИЁЂЯЃРАзжФИЁЂШеЮФЦНМйУћМАЦЌМйУћзжФИЁЂЖэгяЮїРяЖћзжФИЁЃЦфжаЪеТМККзж6763Иі,ЦфЫћЮФзжЗћКХ682ИіЁЃЭЌЪБетжжзжЗћМЏгжМцШн?ASCII?зжЗћМЏ,ЫљвддкБрТыЗНЪНЩЯЯдЕУгааЉЦцЙж:
- ШчЙћИУзжЗћдк?ASCII?зжЗћМЏжа,дђВЩгУ1зжНкБрТыЁЃ
- ЗёдђВЩгУ2зжНкБрТыЁЃ
етжжБэЪОвЛИізжЗћашвЊЕФзжНкЪ§ПЩФмВЛЭЌЕФБрТыЗНЪНГЦЮЊ?БфГЄБрТыЗНЪН?ЁЃБШЗНЫЕзжЗћДЎ?'АЎu'?,Цф
жа?'АЎ'?ашвЊгУ2ИізжНкНјааБрТы,БрТыКѓЕФЪЎСљНјжЦБэЪОЮЊ?0xCED2?,?'u'?ашвЊгУ1ИізжНкНјааБрТы,БрТыКѓЕФЪЎСљНјжЦБэЪОЮЊ?0x75?,ЫљвдЦДКЯЦ№РДОЭЪЧ?0xCED275?ЁЃ
аЁЬљЪП:?ЮвУЧдѕУДЧјЗжФГИізжНкДњБэвЛИіЕЅЖРЕФзжЗћЛЙЪЧДњБэФГИізжЗћЕФвЛВПЗжФи?Б№ЭќСЫ?ASCII?зжЗћМЏжЛЪеТМ128ИізжЗћ,ЪЙгУ0~127ОЭПЩвдБэЪОШЋВПзжЗћ,ЫљвдШчЙћФГИізжНкЪЧдк0~127жЎФкЕФ,ОЭвтЮЖзХвЛИізжНкДњБэвЛИіЕЅЖРЕФзжЗћ,ЗёдђОЭЪЧСНИізжНкДњБэвЛИіЕЅЖРЕФзжЗћЁЃ
GBK?зжЗћМЏ
GBK?зжЗћМЏжЛЪЧдкЪеТМзжЗћЗЖЮЇЩЯЖд?GB2312?зжЗћМЏзїСЫРЉГф,БрТыЗНЪНЩЯМцШн?GB2312?ЁЃ
utf8?зжЗћМЏ
ЪеТМЕиЧђЩЯФмЯыЕНЕФЫљгазжЗћ,ЖјЧвЛЙдкВЛЖЯРЉГфЁЃетжжзжЗћМЏМцШн?ASCII?зжЗћМЏ,ВЩгУБфГЄБрТыЗНЪН,БрТывЛИізжЗћашвЊЪЙгУ1~4ИізжНк,БШЗНЫЕетбљ:
- 'L' -> 01001100(ЪЎСљНјжЦ:0x4C)
- 'АЁ' -> 111001011001010110001010(ЪЎСљНјжЦ:0xE5958A)
аЁЬљЪП:?ЦфЪЕзМШЗЕФЫЕ,utf8жЛЪЧUnicodeзжЗћМЏЕФвЛжжБрТыЗНАИ,UnicodeзжЗћМЏПЩвдВЩгУutf8ЁЂ
utf16ЁЂutf32етМИжжБрТыЗНАИ,utf8ЪЙгУ1~4ИізжНкБрТывЛИізжЗћ,utf16ЪЙгУ2ИіЛђ4ИізжНкБрТывЛИізжЗћ,utf32ЪЙгУ4ИізжНкБрТывЛИізжЗћЁЃИќЯъЯИЕФUnicodeКЭЦфБрТыЗНАИЕФжЊЪЖВЛЪЧБОЪщЕФжиЕу,ДѓМвЩЯЭјВщВщЙў~?MySQLжаВЂВЛЧјЗжзжЗћМЏКЭБрТыЗНАИЕФИХФю,ЫљвдКѓБппыпЖЕФЪБКђАбutf8ЁЂutf16ЁЂutf32 ЖМЕБзївЛжжзжЗћМЏЖдД§ЁЃ
ЖдгкЭЌвЛИізжЗћ,ВЛЭЌзжЗћМЏвВПЩФмгаВЛЭЌЕФБрТыЗНЪНЁЃБШШчЖдгкККзж?'Юв'?РДЫЕ,?ASCII?зжЗћМЏжаИљБОУЛгаЪеТМетИізжЗћ,?utf8?КЭ?gb2312?зжЗћМЏЖдККзж?Юв?ЕФБрТыЗНЪНШчЯТ:
- utf8БрТы:111001101000100010010001 (3ИізжНк,ЪЎСљНјжЦБэЪОЪЧ:0xE68891)
- gb2312БрТы:1100111011010010 (2ИізжНк,ЪЎСљНјжЦБэЪОЪЧ:0xCED2)
5.MySQLжаЕФutf8КЭutf8mb4
ЮвУЧЩЯБпЫЕ?utf8?зжЗћМЏБэЪОвЛИізжЗћашвЊЪЙгУ1~4ИізжНк,ЕЋЪЧЮвУЧГЃгУЕФвЛаЉзжЗћЪЙгУ1~3ИізжНкОЭПЩвдБэЪОСЫЁЃЖјдк?MySQL?жазжЗћМЏБэЪОвЛИізжЗћЫљгУзюДѓзжНкГЄЖШдкФГаЉЗНУцЛсгАЯьЯЕЭГЕФДцДЂКЭадФм,ЫљвдЩшМЦ?MySQLЕФДѓЪхЭЕЭЕЕФЖЈвхСЫСНИіИХФю:
- utf8mb3?:бЫИюЙ§ЕФ?utf8?зжЗћМЏ,жЛЪЙгУ1~3ИізжНкБэЪОзжЗћЁЃ
- utf8mb4?:е§зкЕФ?utf8?зжЗћМЏ,ЪЙгУ1~4ИізжНкБэЪОзжЗћЁЃ
гавЛЕуашвЊДѓМвЪЎЗжЕФзЂвт,дк?MySQL?жа?utf8?ЪЧ?utf8mb3?ЕФБ№Ућ,ЫљвджЎКѓдк?MySQL?жаЬсЕН?utf8?ОЭвтЮЖзХЪЙгУ1~3ИізжНкРДБэЪОвЛИізжЗћ,ШчЙћДѓМвгаЪЙгУ4зжНкБрТывЛИізжЗћЕФЧщПі,БШШчДцДЂвЛаЉemojiБэЧщЩЖЕФ,ФЧЧыЪЙгУ?utf8mb4?ЁЃ
зжЗћМЏЕФВщПД
MySQL?жЇГжКУЖрКУЖржжзжЗћМЏ,ВщПДЕБЧА?MySQL?жажЇГжЕФзжЗћМЏПЩвдгУЯТБпетИігяОф:
show?charset;
cs