Ŀ¼
һ��PyTorch�е�Tensor����
1��Tensor����
2��Tensor��������
3��Tensor���ú���
��������PyTorch�����������ģ��
1������������ģ��
2��Pytorch�Զ��ݶ�
3��ʹ���Զ��ݶȺ��Զ��庯�������������ģ��
����torch.nn��torch.optim
1��ʹ��torch.nn�������ģ��
2��ʹ��torch.optim�Ż�ģ��
һ��PyTorch�е�Tensor����
1��Tensor����
Tensor��PyTorch�и���洢��������,PyTorch���TensorҲ�ṩ����Էḻ�ĺ����ͷ���,����PyTorch�е�Tensor��NumPy��������м��ߵ�������,ͬʱ Tensor����ʹ�� GPU ���м��㡣
2��Tensor��������
(1)torch.FloatTensor? ? # �˱�������������������Ϊ�����͵�Tensor,���ݸ�torch.FloatTensor�IJ���������һ���б�,Ҳ������һ��ά��ֵ;
import torch
a=torch.FloatTensor(2,3) #������������Ϊ�����͵�Tensor
print(a)
b=torch.FloatTensor([2,3,4,5])
print(b)
tensor([[0., 0., 0.],
[0., 0., 0.]])
tensor([2., 3., 4., 5.])
(2)torch.IntTensor? ? # ����������������Ϊ���͵�Tensor
3��Tensor���ú���
(1)torch.rand? ? # ����������������Ϊ��������ά��ָ�������Tensor,����Numpy��ʹ��numpy.rand����������ķ�������,������ɵĸ���������0~1������ȷֲ���
(2)torch.randn? ? # ����������������Ϊ��������ά��ָ�������Tensor,����Numpy��ʹ��numpy.randn����������ķ�������,������ɵĸ�������ȡֵ�����ֵΪ0,����Ϊ1����̫�ֲ���
(3)torch.range? ? #?����������������Ϊ���������Զ�����ʵ��Χ�ͽ�����Χ��Tensor,���Դ��ݸ�torch.range�IJ���������,�ֱ��Ƿ�Χ����ʼֵ,��Χ�Ľ���ֵ�Ͳ���,����,��������ָ������ʼֵ������ֵ��ÿ�������ݼ����
(4)torch.zeros? ? # ����������������Ϊ��������ά��ָ����Tensor,������������͵�Tensor�е�Ԫ��ֵȫ��Ϊ0��
(5)torch.abs? ? # ���������ݵ�torch.abs����������ľ���ֵ��Ϊ���,�������������һ��Tensor�������͵ı�����
(6)torch.add? ? # ���������ݵ�torch.add�������������ͽ����Ϊ���,��������ȿ���ȫ����Tensor�������͵ı���,Ҳ������һ��Tensor�������͵ı���,��һ���DZ�����
(7)torch.clamp? ? # ��������������Զ���ķ�Χ���вü�,������ü��Ľ����Ϊ����������������һ��������,�ֱ�����Ҫ���вü���Tensor�������͵ı������ü����ϱ߽�Ͳü����±߽�,����IJü�������:ʹ�ñ����е�ÿ��Ԫ�طֱ�Ͳü����ϱ߽缰�ü����±߽��ֵ���бȽ�,���Ԫ�ص�ֵС�ڲü����±߽��ֵ,��Ԫ�ؾͱ���д�ɲü����±߽��ֵ;ͬ��,���Ԫ�ص�ֵ���ڲü����ϱ߽��ֵ,��Ԫ�ؾͱ���д�ɲü����ϱ߽��ֵ��
a=torch.randn(2,3)
print(a)
b=torch.clamp(a,-0.1,0.1) #�߽�ֵ�ü�
print(b)
tensor([[-0.6895, -0.2334, -1.1246],
[ 0.2961, -1.4742, 1.7083]])
tensor([[-0.1000, -0.1000, -0.1000],
[ 0.1000, -0.1000, 0.1000]])
(8)torch.div? ? # ���������ݵ�torch.div��������������̽����Ϊ���,ͬ��,��������IJ�������ȫ����Tensor�������͵ı���,Ҳ������Tensor�������͵ı����ͱ�������ϡ�
(9)torch.pow? ? # ���������ݵ�torch.pow��������������ݽ����Ϊ���,��������IJ�������ȫ����Tensor�������͵ı���,Ҳ������Tensor�������͵ı����ͱ�������ϡ�
(10)torch.mul? ? # ���������ݵ� torch.mul�������������Ľ����Ϊ���,��������IJ�������ȫ����Tensor�������͵ı���,Ҳ������Tensor�������͵ı����ͱ�������ϡ�
(11)torch.mm? ? # ���������ݵ� torch.mm�������������������Ϊ���,�����������ķ�ʽ��֮ǰ��torch.mul���㷽ʽ��̫��,torch.mm���þ���֮��ij˷�������м���,���Ա�����IJ����ᱻ����������д���,������ά����ȻҲҪ�������˷���ǰ������,��ǰһ���������������ͺ�һ��������������,�����ܽ��м��㡣
(12)torch.mv? ? # ���������ݵ�torch.mv�������������������Ϊ���,torch.mv���þ���������֮��ij˷�������м���,������IJ����еĵ�1��������������,��2��������������,˳���ܵߵ���
(13)torch.view? ? # �ı�һ�� tensor �Ĵ�С������״��
x=torch.randn(4,4)
y=x.view(16)
z=x.view(-1,8) #-1��ʾ��ά�ȴ�С�Ǵ�����ά���ƶϳ�����
print(x.size(),y.size(),z.size())
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
��������PyTorch�����������ģ��
1������������ģ��
# coding:utf-8
import torch
batch_n = 100 #һ���������������ݵ�����,ֵ��100��ʾ��һ������������100������
input_data = 1000 #ÿ�����ݰ�������������
hidden_layer = 100 #�������ز���������������ĸ���
output_data = 10 #������ݱ�ʾ������ֵ������
#��ʼ��Ȩ��
x = torch.randn(batch_n, input_data) #�����ά��Ϊ(100,1000)
y = torch.randn(batch_n, output_data) #�����ά��Ϊ(100,10)
w1 = torch.randn(input_data, hidden_layer) #����㵽���ز��Ȩ�ز���ά��Ϊ(1000,100)
w2 = torch.randn(hidden_layer, output_data) #���ز㵽������Ȩ�ز���ά��Ϊ(100,10)
epoch_n = 20 #ѵ���Ĵ���
learning_rate = 1e-6 #ѧϰЧ��
#�ݶ��½��Ż����������
for epoch in range(epoch_n):
h1 = x.mm(w1) # 100*1000
h1 = h1.clamp(min=0) #ʹ��clamp�������вü�,��С�����ֵȫ�����¸�ֵ��0
y_pred = h1.mm(w2) # 100*10
# print(y_pred)
loss = (y_pred - y).pow(2).sum() #������������ʧ
print("Epoch:{} , Loss:{:.4f}".format(epoch, loss))
gray_y_pred = 2 * (y_pred - y)
gray_w2 = h1.t().mm(gray_y_pred) #.t()�ǽ�Tensor����ת��
grad_h = gray_y_pred.clone()
grad_h = grad_h.mm(w2.t())
grad_h.clamp_(min=0)
grad_w1 = x.t().mm(grad_h) #Ȩ�ز�����Ӧ���ݶ�
w1 -= learning_rate * grad_w1 #����ѧϰ�ʶ�w1��w2��Ȩ�ز������и���
w2 -= learning_rate * gray_w2
�������:
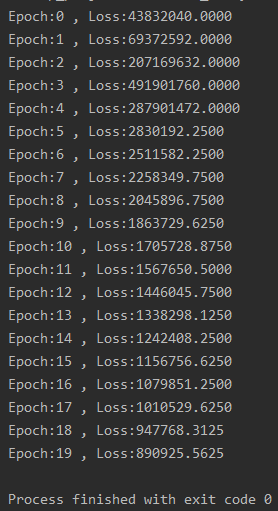
2��Pytorch�Զ��ݶ�
autograd package?��PyTorch������������ĺ���,���ṩ��Tensors������������Զ�����,ͨ��torch.autograd��,����ʹģ�Ͳ����Զ��������Ż���������Ҫ�õ����ݶ�ֵ,�ںܴ�̶��ϰ���������ʵ�ֺ�������ĸ��Ӷȡ�
torch.autograd?������Ҫ�������������������е���ʽ��
autograd.Variable �����package�������ࡣ�������һ��Tensor,����֧�ּ����������㡣һ�����������ļ���,���Ե���.backward(),�����ݶȾͿ����Զ����㡣
3��ʹ���Զ��ݶȺ��Զ��庯�������������ģ��
import torch
from torch.autograd import Variable
#����������ģ��
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
#super().__init__()
def forward(self,input,w1,w2):
x=torch.mm(input,w1)
x=torch.clamp(x,min=0)
x=torch.mm(x,w2)
return x
def backward(self):
pass
batch_n = 100 # ���������������
hidden_layer = 100 # ͨ�����ز�������������
input_data = 1000 # �������ݵ���������
output_data = 10 # �������ķ�������
#��ʼ��Ȩ��
x = Variable(torch.randn(batch_n, input_data), requires_grad=False)
y = Variable(torch.randn(batch_n, output_data), requires_grad=False)
w1 = Variable(torch.randn(input_data, hidden_layer), requires_grad=True)
w2 = Variable(torch.randn(hidden_layer, output_data), requires_grad=True)
epoch_n = 20 #ѵ���Ĵ���
learning_rate = 1e-6 #ѧϰЧ��
model=Model() #��ģ������е���
#ģ��ѵ���Ͳ����Ż�
for epoch in range(epoch_n):
y_pred = model(x,w1,w2) #��ɶ�ģ��Ԥ��ֵ�����
loss = (y_pred - y).pow(2).sum()
print("Epoch:{} , Loss:{:.4f}".format(epoch, loss.data))
loss.backward() #�Զ����������ݶ�
w1.data -= learning_rate * w1.grad.data
w2.data -= learning_rate * w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
�������:
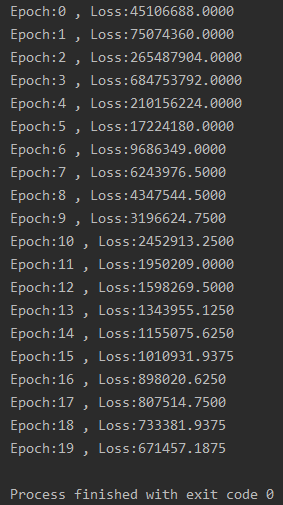
����˵��:
(1)class Model(torch.nn.Module)
����ͨ��class Model(torch.nn.Module)�������̳еIJ���,֮��ֱ�����ij�ʼ��,�Լ�forward������backward������forward����ʵ����ģ�͵�ǰ���еľ�������,backwardʵ����ģ�͵ĺ����е��Զ��ݶȼ���,�������û���ر������,����һ������²��ý��е�����
(2)requires_grad����
��������ĸ�ֵ�����Dz�����,���requires_grad��ֵ��False,��ô��ʾ�ñ����ڽ����Զ��ݶȼ���Ĺ����в��ᱣ���ݶ�ֵ�����ǽ����������x�����������y��requires_grad����������ΪFalse,������Ϊ�������������������ǵ�ģ����Ҫ�Ż��IJ���,������Ȩ��w1��w2��requires_grad������ֵΪTrue��
(3).backward()����
��������Ĺ���������ģ���ݼ���ͼ�Զ�����ÿ���ڵ���ݶ�ֵ������������б���,������һ��,���ǵ�Ȩ�ز��� w1.data�� w2.data�Ϳ���ֱ��ʹ�����Զ��ݶȹ�������õ��ݶ�ֵw1.data.grad��w2.data.grad,�����ѧϰ�����������еIJ������и��¡��Ż��ˡ�
(4).zero_()����
�����μ���õ��ĸ��������ڵ���ݶ�ֵͨ��grad.data.zero_()ȫ������,���������,�������ݶ�ֵ�ᱻһֱ�ۼ�,�����ͻ�Ӱ�쵽�����ļ��㡣
����torch.nn��torch.optim
torch.nn ���ṩ�˺ܶ���ʵ���������еľ��幦����ص���,��Щ�ອ�������������ģ���ڴ�Ͳ����Ż������еij�������,�����������еľ����㡢�ػ��㡢ȫ���Ӳ������ι���ķ�������ֹ����ϵIJ�����һ��������Dropout ����,���м�������ֵ����Լ�����������Լ������صķ����ȡ�
torch.optim �����ṩ�˷dz���Ŀ�ʵ�ֲ����Զ��Ż�����,����SGD��AdaGrad��RMSProp��Adam�ȡ�
1��ʹ��torch.nn�������ģ��
# _*_coding:utf-8_*_
import torch
from torch.autograd import Variable
batch_n = 100 # ���������������
input_data = 1000 # �������ݵ���������
hidden_layer = 100 # ͨ�����ز�������������
output_data = 10 # �������ķ�������
x = Variable(torch.randn(batch_n, input_data), requires_grad=False)
y = Variable(torch.randn(batch_n, output_data), requires_grad=False)
# ģ�ʹ
models = torch.nn.Sequential(
# ����ͨ������ɴ�����㵽���ز�����Ա任
torch.nn.Linear(input_data, hidden_layer),
# ���������
torch.nn.ReLU(),
# �����ɴ����ز㵽���������Ա任
torch.nn.Linear(hidden_layer, output_data)
)
epoch_n = 10000
learning_rate = 1e-4
loss_fn = torch.nn.MSELoss() #���������ʧ����
# �����Ż�
for epoch in range(epoch_n):
y_pred = models(x)
loss = loss_fn(y_pred, y)
if epoch % 1000 == 0:
print("Epoch:{},Loss:{:.4f}".format(epoch, loss.data))
models.zero_grad()
loss.backward()
# ����ģ���е�ȫ��������ͨ���ԡ�models.parameters()�����б�����ɵ�
# ��ÿ�������IJ��������ݶȸ���
for param in models.parameters():
param.data -= param.grad.data * learning_rate
�������:
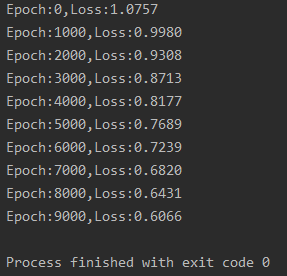
����˵��:
(1)torch.nn.Sequential
torch.nn.Sequential ����torch.nn�е�һ����������,ͨ����������Ƕ����ʵ���������о��幦����ص���,����ɶ�������ģ�͵Ĵ,����Ҫ����,�����ᰴ�����Ƕ���õ������Զ�������ȥ�����ǿ��Խ�Ƕ���������еĸ������ֿ������ֲ�ͬ��ģ��,��Щģ�����������ϡ�
ģ��ļ���һ�������ַ�ʽ,һ���������ϴ�����ʹ�õ�ֱ��Ƕ��,��һ������ orderdict �����ֵ�ķ�ʽ���д���,�����ַ�ʽ��Ψһ������,ʹ�ú��ߴ��ģ�͵�ÿ��ģ�鶼�������Զ��������,��ǰ��Ĭ��ʹ�ô��㿪ʼ������������Ϊÿ��ģ������֡����ַ�ʽ����:
import torch
from torch.autograd import Variable
batch_n = 100 # ���������������
input_data = 1000 # �������ݵ���������
hidden_layer = 100 # ͨ�����ز�������������
output_data = 10 # �������ķ�������
#ģ�ʹ
models = torch.nn.Sequential(
# ����ͨ������ɴ�����㵽���ز�����Ա任
torch.nn.Linear(input_data, hidden_layer),
# ���������
torch.nn.ReLU(),
# �����ɴ����ز㵽���������Ա任
torch.nn.Linear(hidden_layer, output_data))
print(models)
�������:
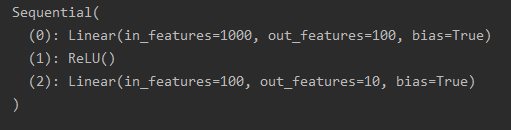
import torch
from torch.autograd import Variable
from collections import OrderedDict
batch_n = 100 # ���������������
input_data = 1000 # �������ݵ���������
hidden_layer = 100 # ͨ�����ز�������������
output_data = 10 # �������ķ�������
#ģ�ʹ
models = torch.nn.Sequential(OrderedDict([
("Linel",torch.nn.Linear(input_data,hidden_layer)),
("ReLU1",torch.nn.ReLU()),
("Line2",torch.nn.Linear(hidden_layer,output_data))]))
print(models)
�������:
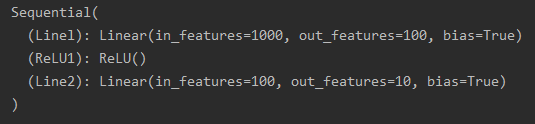
(2)torch.nn.ReLU
torch.nn.ReLU �����ڷ����Լ������,�ڶ���ʱĬ�ϲ���Ҫ����������� torch.nn���л�����������Լ������ɹ�ѡ��,����PReLU��LeakyReLU��Tanh��Sigmoid��Softmax�ȡ�
(3)torch.nn.Linear
torch.nn.Linear �����ڶ���ģ�͵����Բ�,�����ǰ���ᵽ�IJ�ͬ�IJ�֮������Ա任�������յIJ���������,�ֱ���������������������������Ƿ�ʹ��ƫ��,�����Ƿ�ʹ��ƫ�õIJ�����һ������ֵ,Ĭ��ΪTrue,��ʹ��ƫ�á�
��ʵ��ʹ�õĹ�����,����ֻ�轫���������������������������ݸ�torch.nn.Linear��,�ͻ��Զ����ɶ�Ӧά�ȵ�Ȩ�ز�����ƫ��,�������ɵ�Ȩ�ز�����ƫ��,���ǵ�ģ��Ĭ��ʹ����һ�ֱ�֮ǰ�ļ������ʽ���õIJ�����ʼ��������
(4)torch.nn.MSELoss
torch.nn.MSELoss ��ʹ�þ�����������ʧֵ���м���,�ڶ�����Ķ���ʱ���ô����κβ���,����ʹ��ʵ��ʱ��Ҫ��������ά��һ���IJ������ɽ��м��㡣
import torch
from torch.autograd import Variable
loss_f=torch.nn.MSELoss()
x=Variable(torch.randn(100,100))
y=Variable(torch.randn(100,100))
loss=loss_f(x,y)
print(loss)
tensor(2.0491)
������ʧ����ʹ�÷���ͬtorch.nn.MSELoss��һ����,��:torch.nn.L1Loss ��ʹ��ƽ��������������ʧֵ���м���;torch.nn.CrossEntropyLoss �����ڼ��㽻����;
2��ʹ��torch.optim�Ż�ģ��
# _*_coding:utf-8_*_
import torch
from torch.autograd import Variable
batch_n = 100 # ���������������
input_data = 1000 # �������ݵ���������
hidden_layer = 100 # ͨ�����ز�������������
output_data = 10 # �������ķ�������
x = Variable(torch.randn(batch_n, input_data), requires_grad=False)
y = Variable(torch.randn(batch_n, output_data), requires_grad=False)
# ģ�ʹ
models = torch.nn.Sequential(
# ����ͨ������ɴ�����㵽���ز�����Ա任
torch.nn.Linear(input_data, hidden_layer),
# ���������
torch.nn.ReLU(),
# �����ɴ����ز㵽���������Ա任
torch.nn.Linear(hidden_layer, output_data)
)
epoch_n = 20
learning_rate = 1e-4
loss_fn = torch.nn.MSELoss() # ���������ʧ����
optimzer=torch.optim.Adam(models.parameters(),lr=learning_rate) #
# ѵ��ģ��
for epoch in range(epoch_n):
y_pred = models(x)
loss = loss_fn(y_pred, y)
print("Epoch:{},Loss:{:.4f}".format(epoch, loss.data))
optimzer.zero_grad() # �����ݶȵĹ���
loss.backward()
optimzer.step() # �����ݶȸ���
�������:
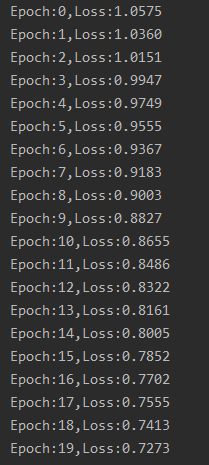
����˵��:
(1)torch.optim.Adam
����ʹ���� torch.optim ���е� torch.optim.Adam ����Ϊ���ǵ�ģ�Ͳ������Ż�����,�� torch.optim.Adam ����������DZ��Ż��IJ�����ѧϰ���ʵij�ʼֵ,���û������ѧϰ���ʵij�ʼֵ,��ôĬ��ʹ��0.001���ֵ����Ϊ������Ҫ�Ż�����ģ���е�ȫ������,���Դ��ݸ�torch.optim.Adam��IJ�����models.parameters������,Adam�Ż���������һ��ǿ��Ĺ���,���ǿ��Զ��ݶȸ���ʹ�õ���ѧϰ���ʽ�������Ӧ���ڡ�
(2)optimzer.zero_grad �� optimzer.step
optimzer.zero_grad ��ɶ�ģ�Ͳ����ݶȵĹ��㡣
optimzer.step ��Ҫ������ʹ�ü���õ����ݶ�ֵ�Ը����ڵ�IJ��������ݶȸ��¡�
�ο�:
1. PyTorch��װ:PyTorch����
2.?Pytorch�ٷ��̳����İ�
cs