#encoding:utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
#ЖСШЁЭМЦЌ
src = cv2.imread('img/cat.jpg')
#ЛёШЁЭМЯёДѓаЁ
rows, cols = src.shape[:2]
#ЩшжУЭМЯёЭИЪгБфЛЛОиеѓ
pos1 = np.float32([[114, 82], [287, 156], [8, 322], [216, 333]])
pos2 = np.float32([[0, 0], [188, 0], [0, 262], [188, 262]])
M = cv2.getPerspectiveTransform(pos1, pos2)
#ЭМЯёЭИЪгБфЛЛ
img_new= cv2.warpPerspective(src, M, (190, 272))
#ЯдЪОЭМЯё
images=[src,img_new]
for i in range(2):
plt.subplot(1,2,i+1)
plt.imshow(images[i])
plt.show()

ЫФЁЂЭМЯёуажЕЛЏгыЦНЛЌДІРэ
1ЁЂЭМЯёуажЕЛЏДІРэ
ЭМЯёЕФЖўжЕЛЏЛђуажЕЛЏ(Binarization)жМдкЬсШЁЭМЯёжаЕФФПБъЮяЬх,НЋБГОАвдМАдыЩљЧјЗжПЊРДЁЃЭЈГЃЛсЩшЖЈвЛИіуажЕT,ЭЈЙ§TНЋЭМЯёЕФЯёЫиЛЎЗжЮЊСНРр:ДѓгкTЕФЯёЫиШККЭаЁгкTЕФЯёЫиШКЁЃ
ЛвЖШзЊЛЛДІРэКѓЕФЭМЯёжа,УПИіЯёЫиЖМжЛгавЛИіЛвЖШжЕ,ЦфДѓаЁБэЪОУїАЕГЬЖШЁЃЖўжЕЛЏДІРэПЩвдНЋЭМЯёжаЕФЯёЫиЛЎЗжЮЊСНРрбеЩЋ,ЕБЛвЖШGrayаЁгкуажЕTЪБ,ЦфЯёЫиЩшжУЮЊ0,БэЪОКкЩЋ;ЕБЛвЖШGrayДѓгкЛђЕШгкуажЕTЪБ,ЦфYжЕЮЊ255,БэЪОАзЩЋЁЃ
ЖўжЕЛЏДІРэЙуЗКгІгУгкИїааИївЕ,БШШчЩњЮябЇжаЕФЯИАћЭМЗжИюЁЂНЛЭЈСьгђЕФГЕХЦЩшБ№ЕШЁЃдкЮФЛЏгІгУСьгђжа,ЭЈЙ§ЖўжЕЛЏДІРэНЋЫљашУёзхЮФЮяЭМЯёзЊЛЛЮЊКкАзСНЩЋЭМ,ДгЖјЮЊКѓУцЕФЭМЯёЪЖБ№ЬсЙЉИќКУЕФжЇГХзїгУЁЃ
OpenCVжаЬсЙЉСЫуажЕКЏЪ§threshold()ЪЕЯжЖўжЕЛЏДІРэ:retval, dst = cv2.threshold(src, thresh, maxval, type)
- dst: ЪфГіЭМ
- src: ЪфШыЭМ,жЛФмЪфШыЕЅЭЈЕРЭМЯё,ЭЈГЃРДЫЕЮЊЛвЖШЭМ
- thresh: уажЕ
- maxval: зюДѓжЕ,ЕБЯёЫижЕГЌЙ§СЫуажЕ(ЛђепаЁгкуажЕ,ИљОнtypeРДОіЖЈ),ЫљИГгшЕФжЕ
- type:ЖўжЕЛЏВйзїЕФРраЭ
ЖўжЕЛЏВйзїЕФРраЭжївЊАќКЌвдЯТ5жжРраЭ:
- cv2.THRESH_BINARY :ЖўНјжЦуажЕЛЏ,ГЌЙ§уажЕВПЗжШЁmaxval(зюДѓжЕ),ЗёдђШЁ0
- cv2.THRESH_BINARY_INV: ЗДЖўНјжЦуажЕЛЏ,ГЌЙ§уажЕВПЗжШЁ0,ЗёдђШЁmaxval(зюДѓжЕ)
- cv2.THRESH_TRUNC :НиЖЯуажЕЛЏ,ДѓгкуажЕВПЗжЩшЮЊуажЕ,ЗёдђВЛБф
- cv2.THRESH_TOZERO :уажЕЛЏЮЊ0,ДѓгкЕШгкуажЕВПЗжВЛИФБф,ЗёдђЩшЮЊ0
- cv2.THRESH_TOZERO_INV :ЗДуажЕЛЏЮЊ0,ДѓгкЕШгкуажЕВПЗжЩшЮЊ0,ЗёдђВЛБф
import cv2
import matplotlib.pyplot as plt
import numpy as np
img=cv2.imread('data/cat.jpg')
img_gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh1 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
ret, thresh2 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY_INV)
ret, thresh3 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TRUNC)
ret, thresh4 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO)
ret, thresh5 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original Image', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
cv2.threshold()КЏЪ§жаЕФВЮЪ§img_grayБэЪОЛвЖШЭМ,ВЮЪ§127БэЪОЖдЯёЫижЕНјааЗжРрЕФуажЕ,ВЮЪ§255БэЪОЯёЫижЕИпгкуажЕЪБгІИУБЛИГгшЕФаТЯёЫижЕ,зюКѓвЛИіВЮЪ§ЖдгІВЛЭЌЕФуажЕДІРэЗНЗЈЁЃНсЙћШчЯТЭМ:

2ЁЂЭМЯёЦНЛЌДІРэ
ЭМЯёдіЧП:ЭМЯёдіЧПЪЧЖдЭМЯёНјааДІРэ,ЪЙЦфБШдЪМЭМЯёИќЪЪКЯгкЬиЖЈЕФгІгУ,ЫќашвЊгыЪЕМЪгІгУЯрНсКЯЁЃЖдгкЭМЯёЕФФГаЉЬиеїШчБпдЕЁЂТжРЊЁЂЖдБШЖШЕШ,ЭМЯёдіЧПЪЧНјааЧПЕїЛђШёЛЏ,вдБугкЯдЪОЁЂЙлВьЛђНјвЛВНЗжЮігыДІРэЁЃЭМЯёдіЧПЕФЗНЗЈЪЧвђгІгУВЛЭЌЖјВЛЭЌ,баОПФкШнАќРЈ:
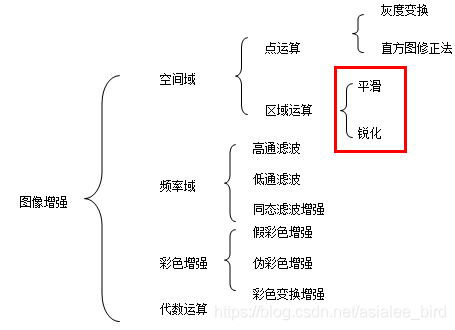
ЭМЯёЦНЛЌ:ЭМЯёЦНЛЌЪЧвЛжжЧјгђдіЧПЕФЫуЗЈ,ЦНЛЌЫуЗЈгаСкгђЦНОљЗЈЁЂжажЕТЫВЈЁЂБпНчБЃГжРрТЫВЈЕШЁЃдкЭМЯёВњЩњЁЂДЋЪфКЭИДжЦЙ§ГЬжа,ГЃГЃЛсвђЮЊЖрЗНУцдвђЖјБЛдыЩљИЩШХЛђГіЯжЪ§ОнЖЊЪЇ,НЕЕЭСЫЭМЯёЕФжЪСП(ФГвЛЯёЫи,ШчЙћЫќгыжмЮЇЯёЫиЕуЯрБШгаУїЯдЕФВЛЭЌ,дђИУЕуБЛдыЩљЫљИаШО)ЁЃетОЭашвЊЖдЭМЯёНјаавЛЖЈЕФдіЧПДІРэвдМѕаЁетаЉШБЯнДјРДЕФгАЯьЁЃ
СкгђЦНОљЗЈ:ЭМЯёМђЕЅЦНЛЌЪЧжИЭЈЙ§СкгђМђЕЅЦНОљЖдЭМЯёНјааЦНЛЌДІРэЕФЗНЗЈ,гУетжжЗНЗЈдквЛЖЈГЬЖШЩЯЯћГ§дЪМЭМЯёжаЕФдыЩљЁЂНЕЕЭдЪМЭМЯёЖдБШЖШЕФзїгУЁЃЫќРћгУОэЛ§дЫЫуЖдЭМЯёСкгђЕФЯёЫиЛвЖШНјааЦНОљ,ДгЖјДяЕНМѕаЁЭМЯёжадыЩљгАЯьЁЂНЕЕЭЭМЯёЖдБШЖШЕФФПЕФЁЃСкгђЦНОљЗЈжївЊШБЕуЪЧдкНЕЕЭдыЩљЕФЭЌЪБЪЙЭМЯёБфЕУФЃК§,ЬиБ№дкБпдЕКЭЯИНкДІ,ЖјЧвСкгђдНДѓ,дкШЅдыФмСІдіЧПЕФЭЌЪБФЃК§ГЬЖШдНбЯжиЁЃ
ТЫВЈЦї:дкЭМЯёМђЕЅЦНЛЌжа,ЫуЗЈРћгУОэЛ§ФЃАхж№вЛДІРэЭМЯёжаУПИіЯёЫи,етвЛЙ§ГЬПЩвдаЮЯѓЕиБШзїЖддЪМЭМЯёЕФЯёЫивЛвЛНјааЙ§ТЫећРэ,дкЭМЯёДІРэжаАбСкгђЯёЫиж№вЛДІРэЕФЫуЗЈЙ§ГЬГЦЮЊТЫВЈЦїЁЃЦНЛЌЯпадТЫВЈЦїЕФЙЄзїдРэЪЧРћгУФЃАхЖдСкгђФкЯёЫиЛвЖШНјааМгШЈЦНОљ,вВГЦЮЊОљжЕТЫВЈЦї
ЮЊЭМЯёдіМгдыЩљШчЯТ
# -*- coding:utf-8 -*-
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread("img/cat.jpg", cv2.IMREAD_UNCHANGED)
rows, cols, chn = img.shape
# ЮЊЭМЦЌдіМгдыЩљ
for i in range(5000):
x = np.random.randint(0, rows)
y = np.random.randint(0, cols)
img[x, y, :] = 255
plt.imshow(img)
plt.show()

(1)ОљжЕТЫВЈ
ОљжЕТЫВЈЪЧжИШЮвтвЛЕуЕФЯёЫижЕ,ЖМЪЧжмЮЇN*MИіЯёЫижЕЕФОљжЕЁЃPythonЕїгУOpenCVЪЕЯжОљжЕТЫВЈЕФКЫаФКЏЪ§ШчЯТ:
result = cv2.blur(дЪМЭМЯё,КЫДѓаЁ)Цфжа,КЫДѓаЁЪЧвд(ПэЖШ,ИпЖШ)БэЪОЕФдЊзцаЮЪНЁЃГЃМћЕФаЮЪНАќРЈ:КЫДѓаЁ(3,3)КЭ(5,5)ЁЃКЫШчЙћЩшжУЮЊ(1,1)ДІРэНсЙћОЭЪЧдЭМ,КЫжаУПИіШЈжижЕЯрЭЌ,ГЦЮЊОљжЕЁЃКЫдНДѓЭМЯёЛсБфЕФдНФЃК§ЁЃ
# -*- coding:utf-8 -*-
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread("img/cat.jpg", cv2.IMREAD_UNCHANGED)
rows, cols, chn = img.shape
# ЮЊЭМЦЌдіМгдыЩљ
for i in range(5000):
x = np.random.randint(0, rows)
y = np.random.randint(0, cols)
img[x, y, :] = 255
source = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# ОљжЕТЫВЈ
result = cv2.blur(source, (5, 5))
# ЯдЪОЭМаЮ
titles = ['Source Image', 'Blur Image']
images = [source, result]
for i in range(2):
plt.subplot(1, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()

(2)ЗНПђТЫВЈ
ЗНПђТЫВЈКЭОљжЕТЫВЈКЫЛљБОвЛжТ,ЧјБ№ЪЧашВЛашвЊОљвЛЛЏДІРэЁЃOpenCVЕїгУboxFilter()КЏЪ§ЪЕЯжЗНПђТЫВЈЁЃКЏЪ§ШчЯТ:
result = cv2.boxFilter(дЪМЭМЯё, ФПБъЭМЯёЩюЖШ, КЫДѓаЁ, normalizeЪєад),Цфжа,ФПБъЭМЯёЩюЖШЪЧintРраЭ,ЭЈГЃгУЁА-1ЁББэЪОгыдЪМЭМЯёвЛжТ;КЫДѓаЁжївЊАќРЈ(3,3)КЭ(5,5)normalizeЪєадБэЪОЪЧЗёЖдФПБъЭМЯёНјааЙщвЛЛЏДІРэЁЃЕБnormalizeЮЊtrueЪБашвЊжДааОљжЕЛЏДІРэ,ЕБnormalizeЮЊfalseЪБ,ВЛНјааОљжЕЛЏДІРэ,ЪЕМЪЩЯЮЊЧѓжмЮЇИїЯёЫиЕФКЭ,КмШнвзЗЂЩњвчГі,вчГіЪБОљЮЊАзЩЋ,ЖдгІЯёЫижЕЮЊ255ЁЃ