Ŀ¼
һ��Bert Ԥѵ��ģ����
����Bert ģ���ı�����
1��������
2������ʵ��
3�������������
һ��Bert Ԥѵ��ģ����
����Ԥѵ��ģ������? ? ??��Bert����Keras:�������Bert��Ĵ�����? ? ??keras-bert
��ͬģ�͵����ܶԱ�����(�ɸ����Լ�������ѡ����ʵ�ģ��,ģ��Խ����Ҫѵ����ʱ��Խ��)
| ģ�� | ������ | ���Լ� |
|---|
| BERT | 83.1 (82.7) / 89.9 (89.6) | 82.2 (81.6) / 89.2 (88.8) |
| ERNIE | 73.2 (73.0) / 83.9 (83.8) | 71.9 (71.4) / 82.5 (82.3) |
| BERT-wwm | 84.3 (83.4) / 90.5 (90.2) | 82.8 (81.8) / 89.7 (89.0) |
| BERT-wwm-ext | 85.0 (84.5) / 91.2 (90.9) | 83.6 (83.0) / 90.4 (89.9) |
| RoBERTa-wwm-ext | 86.6 (85.9) / 92.5 (92.2) | 85.6 (85.2) / 92.0 (91.7) |
| RoBERTa-wwm-ext-large | 89.6 (89.1) / 94.8 (94.4) | 89.6 (88.9) / 94.5 (94.1) |
����Bert ģ���ı�����
1��������
ʹ�õ������û�������м����б������
ѵ����:data_train.csv ,������Ϊ82025,��м��Ա�ǩ(0:���桢1:���ԡ�2:����)?
���Լ�:data_test.csv ,������Ϊ35157
����������Ҫ����:ʳƷ������,����ס����,���ڷ�����,ҽ�Ʒ�����,���������;������������:

2������ʵ��
import pandas as pd
import codecs, gc
import numpy as np
from sklearn.model_selection import KFold
from keras_bert import load_trained_model_from_checkpoint, Tokenizer
from keras.metrics import top_k_categorical_accuracy
from keras.layers import *
from keras.callbacks import *
from keras.models import Model
import keras.backend as K
from keras.optimizers import Adam
from keras.utils import to_categorical
#��ȡѵ�����Ͳ��Լ�
train_df=pd.read_csv('data/data_train.csv', sep='\t', names=['id', 'type', 'contents', 'labels']).astype(str)
test_df=pd.read_csv('data/data_test.csv', sep='\t', names=['id', 'type', 'contents']).astype(str)
maxlen = 100 #�������г���Ϊ120,Ҫ��֤���г��Ȳ�����512
#Ԥѵ���õ�ģ��
config_path = 'chinese_roberta_wwm_large_ext_L-24_H-1024_A-16/bert_config.json'
checkpoint_path = 'chinese_roberta_wwm_large_ext_L-24_H-1024_A-16/bert_model.ckpt'
dict_path = 'chinese_roberta_wwm_large_ext_L-24_H-1024_A-16/vocab.txt'
#���ʱ��еĴʱ��ת��Ϊ�ֵ�
token_dict = {}
with codecs.open(dict_path, 'r', 'utf8') as reader:
for line in reader:
token = line.strip()
token_dict[token] = len(token_dict)
#��дtokenizer
class OurTokenizer(Tokenizer):
def _tokenize(self, text):
R = []
for c in text:
if c in self._token_dict:
R.append(c)
elif self._is_space(c):
R.append('[unused1]') # ��[unused1]����ʾ�ո����ַ�
else:
R.append('[UNK]') # �����б����ַ���[UNK]��ʾ
return R
tokenizer = OurTokenizer(token_dict)
#��ÿ���ı��ij�����ͬ,��0���
def seq_padding(X, padding=0):
L = [len(x) for x in X]
ML = max(L)
return np.array([
np.concatenate([x, [padding] * (ML - len(x))]) if len(x) < ML else x for x in X
])
#data_generatorֻ��һ��Ϊ�˽�Լ�ڴ�����ݷ�ʽ
class data_generator:
def __init__(self, data, batch_size=32, shuffle=True):
self.data = data
self.batch_size = batch_size
self.shuffle = shuffle
self.steps = len(self.data) // self.batch_size
if len(self.data) % self.batch_size != 0:
self.steps += 1
def __len__(self):
return self.steps
def __iter__(self):
while True:
idxs = list(range(len(self.data)))
if self.shuffle:
np.random.shuffle(idxs)
X1, X2, Y = [], [], []
for i in idxs:
d = self.data[i]
text = d[0][:maxlen]
x1, x2 = tokenizer.encode(first=text)
y = d[1]
X1.append(x1)
X2.append(x2)
Y.append([y])
if len(X1) == self.batch_size or i == idxs[-1]:
X1 = seq_padding(X1)
X2 = seq_padding(X2)
Y = seq_padding(Y)
yield [X1, X2], Y[:, 0, :]
[X1, X2, Y] = [], [], []
#����top-k��ȷ��,��Ԥ��ֵ��ǰk��ֵ�д���Ŀ�������ΪԤ����ȷ
def acc_top2(y_true, y_pred):
return top_k_categorical_accuracy(y_true, y_pred, k=2)
#bertģ������
def build_bert(nclass):
bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path, seq_len=None) #����Ԥѵ��ģ��
for l in bert_model.layers:
l.trainable = True
x1_in = Input(shape=(None,))
x2_in = Input(shape=(None,))
x = bert_model([x1_in, x2_in])
x = Lambda(lambda x: x[:, 0])(x) # ȡ��[CLS]��Ӧ����������������
p = Dense(nclass, activation='softmax')(x)
model = Model([x1_in, x2_in], p)
model.compile(loss='categorical_crossentropy',
optimizer=Adam(1e-5), #���㹻С��ѧϰ��
metrics=['accuracy', acc_top2])
print(model.summary())
return model
#ѵ�����ݡ��������ݺͱ�ǩת��Ϊģ�������ʽ
DATA_LIST = []
for data_row in train_df.iloc[:].itertuples():
DATA_LIST.append((data_row.contents, to_categorical(data_row.labels, 3)))
DATA_LIST = np.array(DATA_LIST)
DATA_LIST_TEST = []
for data_row in test_df.iloc[:].itertuples():
DATA_LIST_TEST.append((data_row.contents, to_categorical(0, 3)))
DATA_LIST_TEST = np.array(DATA_LIST_TEST)
#������֤ѵ���Ͳ���ģ��
def run_cv(nfold, data, data_labels, data_test):
kf = KFold(n_splits=nfold, shuffle=True, random_state=520).split(data)
train_model_pred = np.zeros((len(data), 3))
test_model_pred = np.zeros((len(data_test), 3))
for i, (train_fold, test_fold) in enumerate(kf):
X_train, X_valid, = data[train_fold, :], data[test_fold, :]
model = build_bert(3)
early_stopping = EarlyStopping(monitor='val_acc', patience=3) #��ͣ��,��ֹ�����
plateau = ReduceLROnPlateau(monitor="val_acc", verbose=1, mode='max', factor=0.5, patience=2) #������ָ�겻������ʱ,����ѧϰ��
checkpoint = ModelCheckpoint('./bert_dump/' + str(i) + '.hdf5', monitor='val_acc',verbose=2, save_best_only=True, mode='max', save_weights_only=True) #������õ�ģ��
train_D = data_generator(X_train, shuffle=True)
valid_D = data_generator(X_valid, shuffle=True)
test_D = data_generator(data_test, shuffle=False)
#ģ��ѵ��
model.fit_generator(
train_D.__iter__(),
steps_per_epoch=len(train_D),
epochs=5,
validation_data=valid_D.__iter__(),
validation_steps=len(valid_D),
callbacks=[early_stopping, plateau, checkpoint],
)
# model.load_weights('./bert_dump/' + str(i) + '.hdf5')
# return model
train_model_pred[test_fold, :] = model.predict_generator(valid_D.__iter__(), steps=len(valid_D), verbose=1)
test_model_pred += model.predict_generator(test_D.__iter__(), steps=len(test_D), verbose=1)
del model
gc.collect() #�����ڴ�
K.clear_session() #clear_session�������һ��session
# break
return train_model_pred, test_model_pred
#n�۽�����֤
train_model_pred, test_model_pred = run_cv(2, DATA_LIST, None, DATA_LIST_TEST)
test_pred = [np.argmax(x) for x in test_model_pred]
#�����Լ�Ԥ����д���ļ�
output=pd.DataFrame({'id':test_df.id,'sentiment':test_pred})
output.to_csv('data/results.csv', index=None)
3�������������
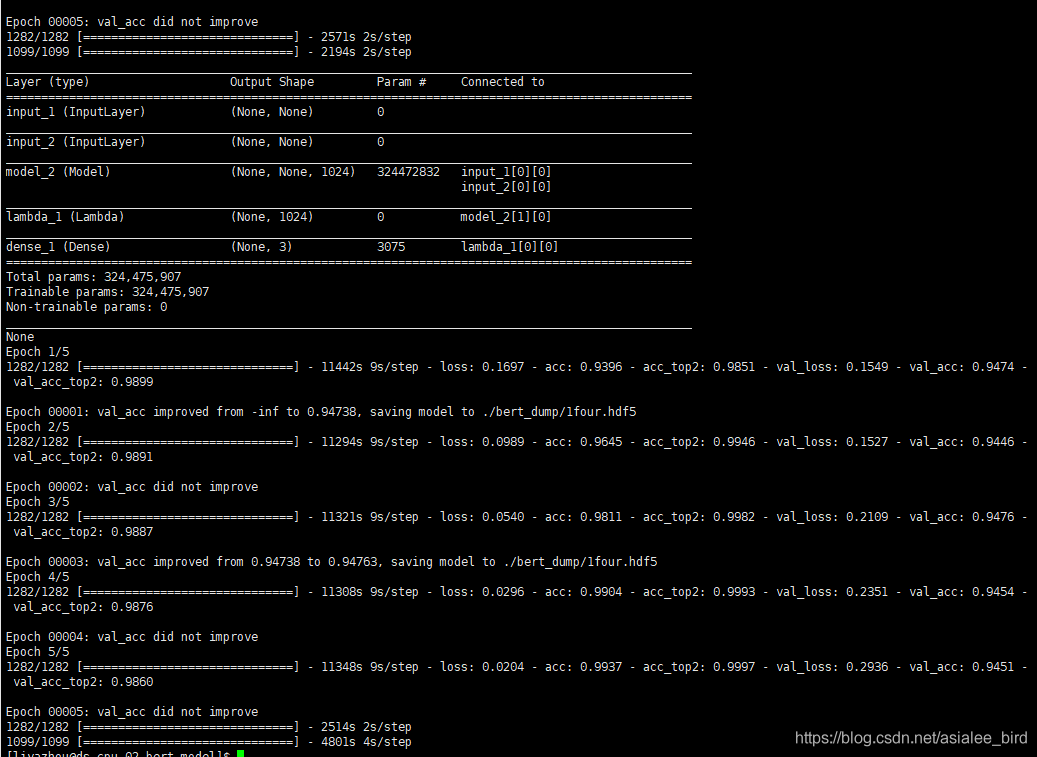
�ڷ���������������,��������ˡ���
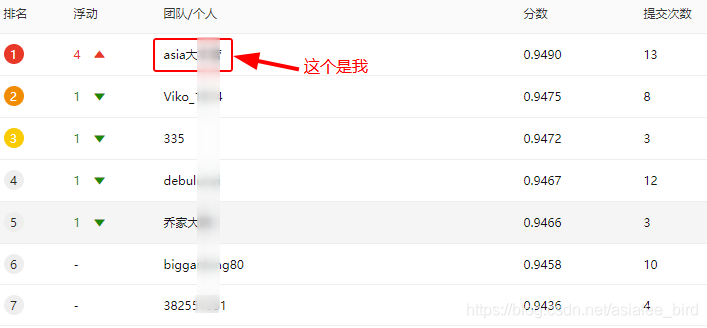
�����ύ���F1-score�ﵽ��94.90%,��ʹ�õ�����ģ��Ч�����á�
ֱ�ӿ��������,һ�����������˵�һ,������
?
?
cs