Ŀ¼
һ����Ե���
����ͼ�������
����ͼ���������
1������ͼ������
2���������ƻ���
3���������߽���ο�
4�����������Բ
�ġ�������ģ
�塢��������
һ����Ե���
��Ե���ͨ�����ڱ���ԭ��ͼ�����Ե������,��ͼ�����ݹ�ģ��������,��ȡͼ���Ե�����Ĵ�����ʽ����Ե����㷨��Ҫ�ǻ���ͼ��ǿ�ȵ�һ�Ͷ�����,������ͨ��������������,�����Ҫ�����˲�������������,������ͼ����ǿ����ֵ���㷨���д���,����ٽ��б�Ե��⡣
1��Roberts����
Roberts�����ֳ�Ϊ�������㷨,���ǻ��ڽ����ֵ��ݶ��㷨,ͨ���ֲ���ּ������Ե�������������������ж��͵ĵ�����ͼ��,��ͼ���Ե�ӽ�����45�Ȼ�45��ʱ,���㷨����Ч�������롣��ȱ���ǶԱ�Ե�Ķ�λ��̫ȷ,��ȡ�ı�Ե�����ϴ֡�Roberts���ӵ�ģ���Ϊˮƽ����ʹ�ֱ����
Roberts������Ҫͨ��Numpy����ģ��,�ٵ���OpenCV��filter2D()����ʵ�ֱ�Ե��ȡ���ú�����Ҫ�������ں�ʵ�ֶ�ͼ��ľ�������,�亯��ԭ��������ʾ:dst = filter2D(src, ddepth, kernel, anchor, delta, borderType) ����,src��ʾ����ͼ��,dst��ʾ����ı�Եͼ,���С��ͨ����������ͼ����ͬ,ddepth��ʾĿ��ͼ����������,kernel��ʾ������,һ����ͨ�������;���,anchor��ʾ�ں˵Ļ���,��Ĭ��ֵΪ(-1,-1),λ������λ��,delta��ʾ�ڴ���Ŀ��ͼ��ǰ��ѡ�����ӵ����ص�ֵ,Ĭ��ֵΪ0,borderType��ʾ�߿�ģʽ��
2��Prewitt����
Prewitt��һ��ͼ���Ե����������,��ԭ���������ض����������ػҶ�ֵ�����IJ��ʵ�ֱ�Ե��⡣����Prewitt���Ӳ���3*3ģ��������ڵ�����ֵ���м���,��Robert���ӵ�ģ��Ϊ2*2,��Prewitt���ӵı�Ե�������ˮƽ����ʹ�ֱ�������Robert���Ӹ������ԡ�Prewitt�����ʺ�����ʶ�������϶ࡢ�ҶȽ����ͼ��
��Python��,Prewitt���ӵ�ʵ�ֹ�����Roberts���ӱȽ����ơ�ͨ��Numpy����ģ��,�ٵ���OpenCV��filter2D()����ʵ�ֶ�ͼ��ľ�������,����ͨ��convertScaleAbs()��addWeighted()����ʵ�ֱ�Ե��ȡ��
3��Sobel����
Sobel������һ�����ڱ�Ե������ɢ������,������˸�˹ƽ�����������������ڼ���ͼ�������̶Ƚ���ֵ,����ͼ���Ե�Ա������̶ȰѸ������ڳ���ij�������ض����Ϊ��Ե��Sobel������Prewitt���ӵĻ�����������Ȩ�صĸ���,��Ϊ���ڵ�ľ���Զ���Ե�ǰ���ص��Ӱ���Dz�ͬ��,����Խ�������ص��Ӧ��ǰ���ص�Ӱ��Խ��,�Ӷ�ʵ��ͼ����ͻ����Ե������Sobel���ӵı�Ե��λ��ȷ,�����������϶ࡢ�ҶȽ����ͼ��
Sobel���Ӹ������ص����¡������ڵ�Ҷȼ�Ȩ��,�ڱ�Ե���ﵽ��ֵ��һ�������Ե������������ƽ������,�ṩ��Ϊ��ȷ�ı�Ե������Ϣ����ΪSobel���ӽ���˸�˹ƽ��������(�ֻ�),��˽������и���Ŀ�����,���Ծ���Ҫ���Ǻܸ�ʱ,Sobel������һ�ֽ�Ϊ���õı�Ե��ⷽ����
����ԭ��Ϊ:dst = cv2.Sobel(src, ddepth, dx, dy, ksize, scale, delta, borderType) ����,src��ʾ����ͼ��,dst��ʾ����ı�Եͼ,���С��ͨ����������ͼ����ͬ,ddepth��ʾĿ��ͼ����������,��Բ�ͬ������ͼ��,���Ŀ��ͼ���в�ͬ�����,dx��ʾx�����ϵIJ�ֽ���,ȡֵ1�� 0,dy��ʾy�����ϵIJ�ֽ���,ȡֵ1��0,ksize��ʾSobel���ӵĴ�С,��ֵ����������������,scale��ʾ���ŵ����ı�������,Ĭ�������û������ϵ��,delta��ʾ���������Ŀ��ͼ��֮ǰ,���ӵ�����еĿ�ѡ����ֵ,borderType��ʾ�߿�ģʽ��
4��Laplacian����
������˹(Laplacian)������nάŷ����¿ռ��е�һ������������,������ͼ����ǿ����ͱ�Ե��ȡ����ͨ���ҶȲ�ּ��������ڵ�����,����������:�ж�ͼ���������ػҶ�ֵ������Χ�������صĻҶ�ֵ,����������صĻҶȸ���,�������������صĻҶ�;��֮�����������صĻҶ�,�Ӷ�ʵ��ͼ�����������㷨ʵ�ֹ�����,Laplacian����ͨ���������������ص��ķ����˷������ݶ�,�ٽ��ݶ���������ж��������ػҶ����������������ػҶȵĹ�ϵ,���ͨ���ݶ�����Ľ�������ػҶȽ��е�����Laplacian���ӷ�Ϊ������Ͱ�����,�������Ƕ������������ص��ķ������ݶ�,�������Ƕ˷������ݶȡ�
5��Scharr����
Scharr�����ֳ�ΪScharr�˲���,Ҳ�Ǽ���x��y�����ϵ�ͼ���֡�����Sobel�����ڼ�����Խ�С�ĺ˵�ʱ��,����Ƽ��㵼���ľ��ȱȽϵ�,����һ��3*3��Sobel����,���ݶȽǶȽӽ�ˮƽ��ֱ����ʱ,�䲻��ȷ�Ծ�Խ�����ԡ�Scharr����ͬSobel���ӵ��ٶ�һ����,����ȷ�ʸ���,�����Ǽ����С�˵��龰,��������3*3�˲���ʵ��ͼ���Ե��ȡ���Ƽ�ʹ��Scharr���ӡ�
6��Canny��Ե���
Canny�㷨��һ�ֱ��㷺Ӧ���ڱ�Ե���ı��㷨,��Ŀ�����ҵ�һ�����ŵı�Ե�������Ѱһ��ͼ���лҶ�ǿ�ȱ仯��ǿ��λ�á����ű�Ե�����Ҫͨ���ʹ����ʡ��߶�λ�Ժ���С��Ӧ�������������ۡ�
Canny��Ե����ʵ�ֲ�������:
- ʹ�ø�˹�˲���,��ƽ��ͼ��,�˳�������
- ����ͼ����ÿ�����ص���ݶ�ǿ�Ⱥͷ���(�ݶȷ���һ��ȡ0�ȡ�45�ȡ�90�Ⱥ�135���ĸ�����)��
- Ӧ�÷Ǽ���ֵ(Non-Maximum Suppression)����,���˵��DZ�Ե����,��ģ���ı߽����������ù��̱�����ÿ�����ص����ݶ�ǿ�ȵļ���ֵ,���˵�������ֵ��
- Ӧ��˫��ֵ(Double-Threshold)�����ȷ����ʵ�ĺ�DZ�ڵı�Ե(����˫��ֵ������ȷ��DZ�ڵı߽硣�����Ǽ������ƺ�ͼ������Ȼ�кܶ�������,��ʱ��Ҫͨ��˫��ֵ��������,���趨һ����ֵ�Ͻ����ֵ�½硣ͼ���е����ص����������ֵ�Ͻ�����Ϊ��Ȼ�DZ߽�(��Ϊǿ�߽�,strong edge),С����ֵ�½�����Ϊ��Ȼ���DZ߽�,����֮�������Ϊ�Ǻ�ѡ��(��Ϊ���߽�,weak edge))��
- ͨ�����ƹ���������Ե������ɱ�Ե���(�����ͺ��������ٱ߽硣��ijһ����λ�ú�ǿ�߽����������߽���Ϊ�DZ߽�,���������߽���ɾ��)��
��OpenCV��,Canny()����ԭ��Ϊ:edges = cv2.Canny(image, threshold1, threshold2, apertureSize, L2gradient)����,image��ʾ����ͼ��,edges��ʾ����ı�Եͼ,���С������������ͼ����ͬ,threshold1��ʾ��һ���ͺ�����ֵ,threshold2��ʾ�ڶ����ͺ�����ֵ,apertureSize��ʾӦ��Sobel���ӵĿ���С,��Ĭ��ֵΪ3,L2gradient��ʾһ������ͼ���ݶȷ�ֵ�ı�ʶ,Ĭ��ֵΪfalse��
7��LOG��Ե���
LOG(Laplacian of Gaussian)��Ե���������Ҳ��ΪMarr & Hildreth����,������ͼ���������������Ե�������˲��������㷨���ȶ�ͼ������˹�˲�,Ȼ��������������˹(Laplacian)������,���ݶ������Ĺ���������ͼ��ı߽�,��ͨ������˲�������㽻��(Zero crossings)�����ͼ�������ı�Ե��
LOG���Ӹ��ۺϿ����˶����������ƺͶԱ�Ե�ļ����������,���Ұ�Gaussƽ���˲�����Laplacian���˲������������,��ƽ��������,�ٽ��б�Ե���,����Ч������á� ���������Ӿ������е���ѧģ������,�����ͼ���������еõ��˹㷺��Ӧ�á������п���������ǿ,�߽綨λ���ȸ�,��Ե�����Ժ�,����Ч��ȡ�Աȶ����ı߽���ص㡣
����ʵ������:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import matplotlib.pyplot as plt
#��ȡͼ��
img = cv2.imread('img/cute.png')
cute_img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#�ҶȻ�����ͼ��
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#��˹�˲�
gaussianBlur = cv2.GaussianBlur(grayImage, (3,3), 0)
#��ֵ����
ret, binary = cv2.threshold(gaussianBlur, 127, 255, cv2.THRESH_BINARY)
#Roberts����
kernelx = np.array([[-1,0],[0,1]], dtype=int)
kernely = np.array([[0,-1],[1,0]], dtype=int)
x = cv2.filter2D(binary, cv2.CV_16S, kernelx)
y = cv2.filter2D(binary, cv2.CV_16S, kernely)
absX = cv2.convertScaleAbs(x) #�������ֵ,����ͼ��ת��Ϊ8λͼ������ʾ
absY = cv2.convertScaleAbs(y)
Roberts = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#Prewitt����
kernelx = np.array([[1,1,1],[0,0,0],[-1,-1,-1]], dtype=int)
kernely = np.array([[-1,0,1],[-1,0,1],[-1,0,1]], dtype=int)
x = cv2.filter2D(binary, cv2.CV_16S, kernelx)
y = cv2.filter2D(binary, cv2.CV_16S, kernely)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Prewitt = cv2.addWeighted(absX,0.5,absY,0.5,0)
#Sobel����
x = cv2.Sobel(binary, cv2.CV_16S, 1, 0,ksize=3)
y = cv2.Sobel(binary, cv2.CV_16S, 0, 1,ksize=3)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Sobel = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#������˹�㷨
dst = cv2.Laplacian(binary, cv2.CV_16S, ksize = 3)
Laplacian = cv2.convertScaleAbs(dst)
# Scharr����
x = cv2.Scharr(binary, cv2.CV_32F, 1, 0) #X����
y = cv2.Scharr(binary, cv2.CV_32F, 0, 1) #Y����
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Scharr = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#Canny����
gaussian = cv2.GaussianBlur(grayImage, (3,3), 0) #��˹�˲�����
Canny = cv2.Canny(gaussian, 50, 150)
#LOG����
gaussian = cv2.GaussianBlur(grayImage, (3,3), 0) #��ͨ����˹�˲�����
dst = cv2.Laplacian(gaussian, cv2.CV_16S, ksize = 3) #��ͨ��������˹��������Ե���
LOG = cv2.convertScaleAbs(dst)
#����������ʾ���ı�ǩ
plt.rcParams['font.sans-serif']=['SimHei']
#Ч��ͼ
titles = ['Source Image', 'Binary Image', 'Roberts Image',
'Prewitt Image','Sobel Image', 'Laplacian Image',
'Scharr Image','Canny Image','LOG����']
images = [cute_img, binary, Roberts, Prewitt, Sobel, Laplacian, Scharr,Canny,LOG]
for i in np.arange(9):
plt.subplot(3,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
�������:

����ͼ�������
ͼ���������ָ��һ��ͼ���Ҳ�ͬ�ֱ��ʵ���ͼ����,����ͼ���߶ȱ����һ��,�Զ�ֱ���������ͼ��Ľṹ,��Ҫ����ͼ��ķָ��ѹ����һ��ͼ��Ľ�������һϵ���Խ�������״���еķֱ�������,����Դ��ͬһ��ԭʼͼ��ͼ�ϡ�
��˹������:���²���(��С),������ͼ����и�˹�˾���,��ɾ��ԭͼ�����е�ż���к���,������Сͼ������ÿ������ȡ����ɾ��ż���к���,�������ͣ�ض�ʧͼ�����Ϣ�������²�����,�㼶Խ��,��ͼ��ԽС,�ֱ���Խ�͡���OpenCV��,����ȡ��ʹ�õĺ���Ϊcv2.pyrDown()��
��˹������:���ϲ���(�Ŵ�),��ͼ������ȡ������Сͼ�Ϸ�ͼ��Ĺ��̡�����ͼ����ÿ������������Ϊԭͼ���2��,�������к��о���0�����,��ʹ���롰����ȡ������ͬ�ľ����˳���4,����Ŵ���ͼ����о�������,�Ի�á��������ء�����ֵ����OpenCV��,����ȡ��ʹ�õĺ���Ϊcv2.pyrUp()��
������˹������:��ͼ���Ƚ������²���,Ȼ�������ϲ����õ����,���ʹ��ԭͼ���ȥ�ý����img-pyrdown(pyrup)
# -*- coding: utf-8 -*-
import cv2
import matplotlib.pyplot as plt
#��ȡԭʼͼ��
img = cv2.imread('img/cute.png')
img_cute=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#ͼ��������ȡ��������ȡ��
down=cv2.pyrDown(img)
down_up=cv2.pyrUp(down)
img_new=img-down_up
#��ʾͼ��
images=[img_cute,img_new]
for i in range(2):
plt.subplot(1,2,i+1)
plt.imshow(images[i])
plt.show()
����ͼ���������
ͼ��������⺯��:cv2.findContours(img,mode,method)
mode:��������ģʽ
- RETR_EXTERNAL :ֻ���������������;
- RETR_LIST:�������е�����,�����䱣�浽һ����������;
- RETR_CCOMP:�������е�����,����������֯Ϊ����:�����Ǹ����ֵ��ⲿ�߽�,�ڶ����ǿն��ı߽�;
- RETR_TREE:�������е�����,���ع�Ƕ���������������;
method:�����ƽ�����
- CHAIN_APPROX_NONE:��Freeman����ķ�ʽ�������,��������������������(���������)��
- CHAIN_APPROX_SIMPLE:ѹ��ˮƽ�ġ���ֱ�ĺ�б�IJ���,Ҳ����,����ֻ�������ǵ��յ㲿�֡�
1������ͼ������
# -*- coding: utf-8 -*-
import cv2
import numpy as np
#��ʾͼ��
def cv_show(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img = cv2.imread('data/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
#ͼ������
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt=contours[0] #��ȡͼ�������еĵ�һ��
area=cv2.contourArea(cnt) #����ij�����������
print(area) #8500.5
arclen=cv2.arcLength(cnt,True) #����ij���������ܳ�,True��ʾ�պϵ�
print(arclen) #437.9482651948929
#����ͼ������,�������ͼ��,����,��������,��ɫģʽ,�������
# ע����Ҫcopy,Ҫ��ԭͼ��䡣
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 1) #����ͼ���е���������
#res = cv2.drawContours(draw_img, [cnt], -1, (0, 0, 255), 2) #����ͼ���е�һ������
cv_show('thresh',res)

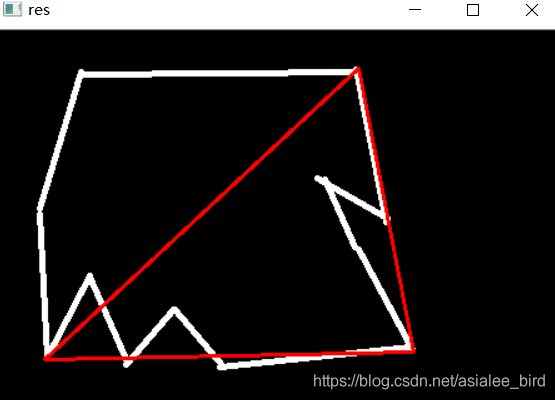
2���������ƻ���
# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('data/contours2.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
epsilon = 0.15*cv2.arcLength(cnt,True)
approx = cv2.approxPolyDP(cnt,epsilon,True) #����αƽ�����,��������
draw_img = img.copy()
res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
cv_show('res',res)
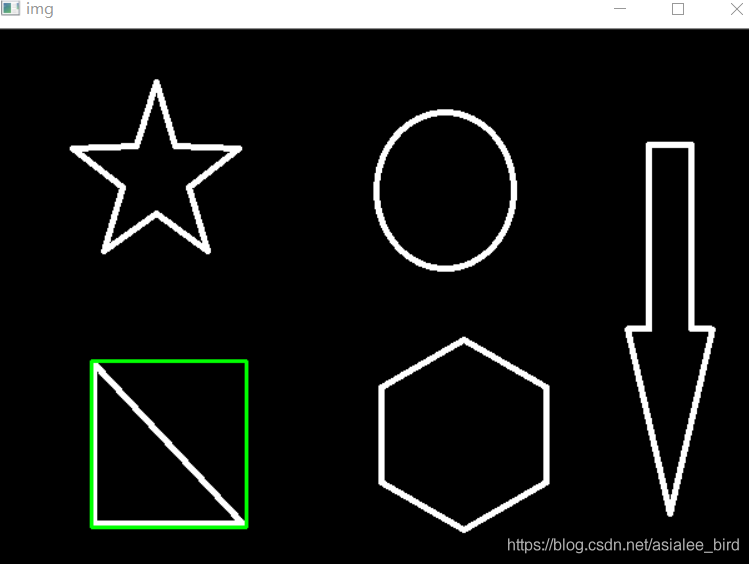
3���������߽���ο�
# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('data/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv_show('img',img)
#�����������߽���α�
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area
print ('���������߽���α�',extent) #���������߽���α� 0.5154317244724715
- cv2.boundingRect(img)����:img��һ����ֵͼ,���������ĸ�ֵ,�ֱ���x,y,w,h;x,y�Ǿ������ϵ������,w,h�Ǿ���Ŀ��ߡ�
- cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2)��������:img��ԭͼ,(x,y)�Ǿ�������ϵ�����,(x+w,y+h)�Ǿ�������µ�����,(0,255,0)�ǻ��߶�Ӧ��rgb��ɫ,2���������ߵĿ��ȡ�
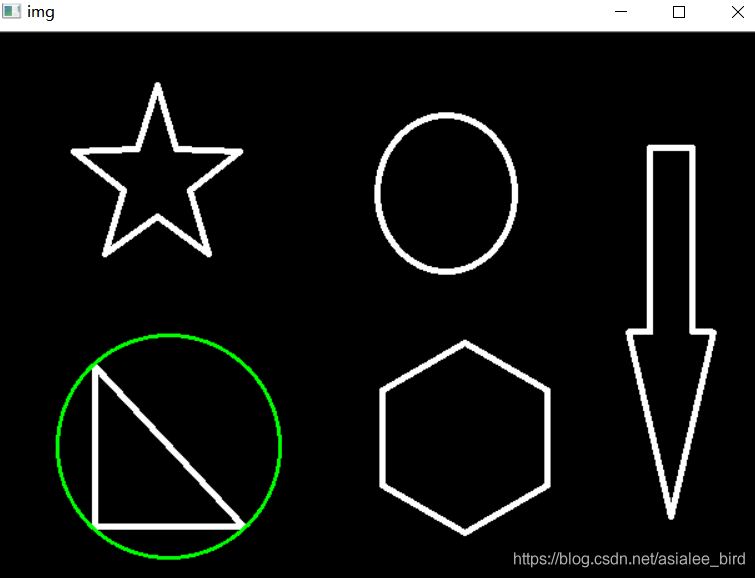
4�����������Բ
# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('data/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
cv_show('img',img)
�ġ�������ģ
1��֡�
���ڳ����е�Ŀ�����˶�,Ŀ���Ӱ���ڲ�ͬͼ��֡�е�λ�ò�ͬ�������㷨��ʱ������������֡ͼ����в������,��ͬ֡��Ӧ�����ص����,�жϻҶȲ�ľ���ֵ,������ֵ����һ����ֵʱ,�����ж�Ϊ�˶�Ŀ��,�Ӷ�ʵ��Ŀ��ļ��ܡ�֡��dz���,���ǻ����������Ϳն����⡣
2����ϸ�˹ģ��
�ڽ���ǰ�����ǰ,�ȶԱ�������ѵ��,��ͼ����ÿ����������һ����ϸ�˹ģ�ͽ���ģ��,ÿ�������Ļ�ϸ�˹�ĸ�����������Ӧ��Ȼ���ڲ��Խ�,�����������ؽ���GMMƥ��,���������ֵ�ܹ�ƥ������һ����˹,����Ϊ�DZ���,������Ϊ��ǰ����������������GMMģ���ڲ��ϸ���ѧϰ��,���ԶԶ�̬������һ����³���ԡ����ͨ����һ������֦ҡ�ڵĶ�̬��������ǰ�����,ȡ���˽Ϻõ�Ч����
����Ƶ�ж������ص�ı仯���Ӧ���Ƿ��ϸ�˹�ֲ�,������ʵ�ʷֲ�Ӧ���Ƕ����˹�ֲ������һ��,ÿ����˹ģ��Ҳ���Դ���Ȩ�ء�
��ϸ�˹ģ��ѧϰ����:(1)���ȳ�ʼ��ÿ����˹ģ�;������;(2)ȡ��Ƶ��T֡����ͼ������ѵ����˹���ģ�͡����˵�һ������֮��������������һ����˹�ֲ�;(3)��������������ֵʱ,��ǰ�����еĸ�˹�ľ�ֵ�Ƚ�,��������ص��ֵ����ģ�;�ֵ����3���ķ�����,�����ڸ÷ֲ�,��������в�������;(4)�����һ���������ز����㵱ǰ��˹�ֲ�,����������һ���µĸ�˹�ֲ���
��ϸ�˹ģ�Ͳ��Է���:�ڲ��Խ�,���������ص��ֵ���ϸ�˹ģ���е�ÿһ����ֵ���бȽ�,������ֵ��2���ķ���֮��Ļ�,����Ϊ�DZ���,������Ϊ��ǰ������ǰ����ֵΪ255,������ֵΪ0���������γ���һ��ǰ����ֵͼ��
3��������ģʵս
import numpy as np
import cv2
#������Ƶ
cap = cv2.VideoCapture('data/test.avi')
#��̬ѧ������Ҫʹ��
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))
#������ϸ�˹ģ�����ڱ�����ģ
fgbg = cv2.createBackgroundSubtractorMOG2()
while(True):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)#ǰ����ֵΪ255,������ֵΪ0
#��̬ѧ������ȥ���
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
#Ѱ����Ƶ�е�����
contours,hierarchy = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
#������������ܳ�
perimeter = cv2.arcLength(c,True)
if perimeter > 188:
#�ҵ�һ��ֱ����(������ת)
x,y,w,h = cv2.boundingRect(c)
#�����������
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('frame',frame)
cv2.imshow('fgmask', fgmask)
k = cv2.waitKey(150) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
�塢��������
�����ǿռ��˶������ڹ۲����ƽ���ϵ������˶��ġ�˲ʱ�ٶȡ�,���ݸ������ص���ٶ�ʸ������,���Զ�ͼ����ж�̬����,����Ŀ����١�
��������ǰ������:
- ���Ⱥ㶨:ͬһ������ʱ��ı仯,�����Ȳ��ᷢ���ı䡣
- С�˶�:����ʱ��ı仯��������λ�õľ��ұ仯,ֻ��С�˶�����²�����ǰ��֮֡�䵥λλ�ñ仯����ĻҶȱ仯ȥ���ƻҶȶ�λ�õ�ƫ������
- �ռ�һ��:һ���������ڽ��ĵ�ͶӰ��ͼ����Ҳ���ڽ���,���ڽ����ٶ�һ�¡���Ϊ��������������Լ��ֻ��һ��,��Ҫ��x,y������ٶ�,������δ֪������������Ҫ����n���������⡣
import numpy as np
import cv2
cap = cv2.VideoCapture('test.avi')
# �ǵ����������
feature_params = dict( maxCorners = 100, qualityLevel = 0.3, minDistance = 7)
# lucas kanade����
lk_params = dict( winSize = (15,15),maxLevel = 2)
# �����ɫ��
color = np.random.randint(0,255,(100,3))
# �õ���һ֡ͼ��
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# �������м��������,��Ҫ����ͼ��,�ǵ��������(Ч��),Ʒ������(����ֵԽ���Խ��,��ɸѡ)
# �����൱���������б�����ǵ�ǿ��,�Ͳ�Ҫ���������
p0 = cv2.goodFeaturesToTrack(old_gray, mask = None, **feature_params)
# ����һ��mask
mask = np.zeros_like(old_frame)
while(True):
ret,frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# ��Ҫ����ǰһ֡�͵�ǰͼ���Լ�ǰһ֡���Ľǵ�
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# st=1��ʾ
good_new = p1[st==1]
good_old = p0[st==1]
# ���ƹ켣
for i,(new,old) in enumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
mask = cv2.line(mask, (a,b),(c,d), color[i].tolist(), 2)
frame = cv2.circle(frame,(a,b),5,color[i].tolist(),-1)
img = cv2.add(frame,mask)
cv2.imshow('frame',img)
k = cv2.waitKey(150) & 0xff
if k == 27:
break
# ����
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
cv2.destroyAllWindows()
cap.release()
- cv2.calcOpticalFlowPyrLK():����:prevImage ǰһ֡ͼ��,nextImage ��ǰ֡ͼ��,prevPts �����ٵ�����������,winSize �������ڵĴ�С,maxLevel ���Ľ���������;����:nextPts �����������������,status �������Ƿ��ҵ�,�ҵ���״̬Ϊ1,δ�ҵ���״̬Ϊ0
?
cs