在阅读本文之前,你应该掌握如何去建立一颗决策树。由于不同的决策树存储结构算法的实现细节上存在一定的差异,因此本文源代码实现对决策树的索引是基于我之前的一篇博文【决策树如何分裂以扩展节点】中所建立的决策树而实现的。
{
'depth': 1,
'the_best_feature': 'blueTowersDestroyed',
'bestfeature_values': [0, 1, 2, 3, 4],
'samples': 7903,
'label': 0,
'branchs': [
{
'branch': 0,
'depth': 2,
'the_best_feature': 'redTowersDestroyed',
'bestfeature_values': [0, 1, 2],
'samples': 7533,
'label': 0,
'branchs': [
{
'branch': 0,
'depth': 3,
'the_best_feature': 'brTotalGold',
'bestfeature_values': [0, 1, 2, 3, 4],
'samples': 7231,
'label': 0
},
{
'branch': 1,
'depth': 3,
'the_best_feature': 'brTotalGold',
'bestfeature_values': [0, 1, 2, 3, 4],
'samples': 279,
'label': 0
},
{
'branch': 2,
'depth': 3,
'the_best_feature': 'brTotalGold',
'brTotalGold',
'bestfeature_values': [0, 1],
'samples': 23,
'label': 0
}
]
},
{
'branch': 1,
'depth': 2,
'the_best_feature': 'redTowersDestroyed',
'bestfeature_values': [0, 1, 2],
'samples': 340,
'label': 1
},
{
'branch': 2,
'depth': 2,
'the_best_feature': 'redHeralds',
'bestfeature_values': [0, 1],
'samples': 23, 'label': 1
},
{
'branch': 3,
'depth': 2,
'the_best_feature': 'blueWardsPlaced',
'bestfeature_values': [0, 1, 4],
'samples': 6,
'label': 1
},
{
'branch': 4,
'depth': 2,
'the_best_feature': 'blueWardsPlaced',
'bestfeature_values': [1],
'samples': 1,
'label': 1
}
]
}
为了帮助读者理解,我绘制了该决策树的图形结构示意:
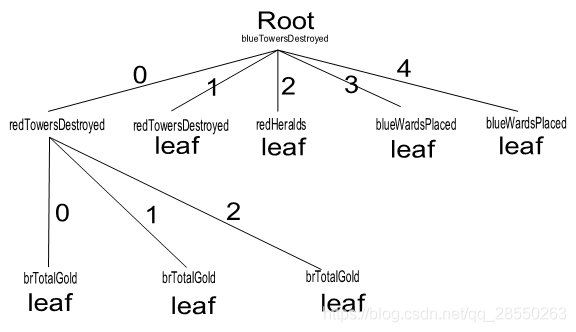
可以看到,在一颗树中节点的本质属性是作为父亲的分支。也就是父节点在依据最佳特征不同的特征值分支后,不同分支再次划分数据集的时候也可以选相同的最佳特征,毕竟同一次分支后的子数据集中拥有的特征类型都是一样的。
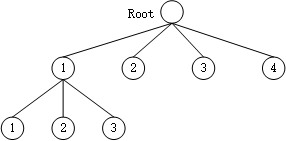
该树最简单的样子是这样(但是我们并没有记录成这样而是保留了更多信息,为以后可能的剪枝策略提供数据支持):
[
[0,1,2],
2,
3,
4
]
即:
2. 实现决策树分类预测的思路
2.1 单条数据的预测
★ 先假设有一种情况:
建立决策树没有进行过任何剪枝,并且在每一次分裂中都训练到节点数据集中的所有标签恰好都能一致(只剩下最后一种标签)时。给定一条"测试集"数据并在再次恰好时在训练集中学到过的数据,分类器该如何给出这条数据的标签?
2.2 在数据集上做预测
在数据集上做预测,这个数据集在我们的实验项目里也就是所谓的“测试集”,在测试集上做预测的目的是评估我们模型性能的好坏。而在实践项目里就是所谓的未知数据,从哲学上看是将我们的模型用于改造世界的过程。
计算机思维,就是所有事情都要一步一步地来实现,正如古语所云:天下大事必作于细。数据的预测也是如此,在某个数据集上进行预测,本质就是对数据集中的每一条数据逐一预测并依次记录下预测结果。
def predict(tree, test_datas):
'''
预测测试集中数据标签
使用它调用predict_one()对训练集中的每一条数据一次预测获取预测结果
Parameters
----------
tree: 基于字典的树形结构的一组数据,是我们训练好的决策树
test_datas: 测试数据集,包含多条待预测分类标签的数据。
'''
test_datas = np.array([test_datas]) if len(test_datas.shape) == 1 else test_datas
predict_list = []
for one_test_data in test_datas:
one_pre_value = predict_one(tree, one_test_data)
predict_list.append(one_pre_value)
return np.array(predict_list)
3. 使用递归查询编程实现分类
class ClassificationTree(object):
...
def predict_one(self, tree, one_test_data):
"""
预测测试集中的一条数据
这个过程实际上就是基于节点的递归查询过程,在某个节点:
是否有分支:
- 有分支:必为非叶子节点:
使用测试集该节点对应的特征名索引出测试特征值,决定接下来查询的分支:
如测试数据的特征值在分支列表中,进入特征值决定的分支,递归以上过程。
如测试数据的特征值不在分支列表中,说明是训练时没有遇到过的新情况:
可以用投票器投出一个标签:即可以按照该节点数据集的标签集各标签占比投票一个,
也可以直接选该节点标签集中出现次数最多的标签作为投票结果。
- 无分支:必为叶子节点:
返回叶子节点处的标签值为预测结果。
Parameters
----------
tree: 递归过程中的树(除了根节点是原决策树,其它的节点都是其子树);
one_test_data: 单条测试数据,本质是单条数据各个特征的取值。
Returns
-------
label, str 或 int、float等,为一条数据的标签
"""
onetestdata_dict = dict(zip(self.features,list(one_test_data)))
the_best_feature = tree.get('the_best_feature')
branchs = tree.get('branchs')
if branchs == None:
return tree.get('label')
else:
node_values = tree['bestfeature_values']
feature_value = onetestdata_dict.get(the_best_feature)
if feature_value not in node_values:
return tree.get('label')
else:
for i in range(len(branchs)):
if branchs[i].get('branch') == feature_value:
subtree = branchs[i]
return self.predict_one(subtree, one_features_data)
def predict(self, test_datas):
assert len(test_datas.shape) == 1 or len(test_datas.shape) == 2
'''
预测测试集中数据标签
使用它调用self.predict_one()对训练集中的每一条数据一次预测获取预测结果
'''
if len(test_datas.shape) == 1:
test_datas= np.array([test_datas])
tree = self.tree
predict_list = []