��Ŀ����(Middle):

�ٷ����:https://leetcode.com/problems/longest-substring-without-repeating-characters/description/
����һ:�����ⷨ
һ��һ���ؼ���Ӵ����Ƿ����ظ��ַ�
�㷨����:
������һ������? boolean allUnique(String substring)? ,���Ӵ����ַ����ظ�ʱ����true,����false�����ǿ���ͨ���Ը����ַ���? s? �����п����Ӵ������ø�? allUnique? �������������Ϊtrue(˵�����ظ�),��������ظ�����Ӵ��ij��ȡ�
��������:
- �����Ӵ��Ŀ�ͷ��ʶΪ i ,��β��ʶΪ j ,�� 0 �� i < j �� n ����ʹ������Ƕ��ѭ�����ɱ���? s? �������Ӵ�(i ��0~n-1,j ��i + 1�� n)
- Ϊ�˼���ַ������Ƿ�����ظ��ַ�,����ʹ�ü�����װ�ء��ڷ���һ���ַ�ǰ�����ַ��Ƿ��Ѵ����ڼ��� set �С����������false��ѭ��������true��
��������:
public class Solution{
public int lengthOfLongestSubString(String s){
int n = s.length(), ans = 0;
for(int i = 0; i < n; i++){ //ѭ�������Ӵ����Ӵ��е��ַ��Ƿ��ظ�
for(int j = i + 1; j <= n; j++){
if(allUnique(s, i, j))
ans = Math.max(ans, j - i) //�����ظ�����²��ظ���Ӵ��ij���
}
}
return ans
}
//�ж��ַ����Ƿ�ȫ�ǵ�һ�ĺ���,�Ƿ���True,����False
public boolean allUnique(String s, int start, int end){
Set<Character> set = new HashSet<>(); //����set�洢�ַ�
for(int i = start; i < end; i++){ //�ӿ�ͷλ�ñ�������βλ��
Character ch = s.charAt(i); //��ȡiλ�õ��ַ�
if(set.contains(ch)) //�ж��ַ��Ƿ��ڼ���set��
return false; //���ڼ���set�б�ʾ���ظ�,�ǵ�һ
set.add(ch); //�ڼ������������ַ�
}
return true;
}
}
?������:��������
�㷨����:
����һ������,����һֱ�ظ��ؼ��һ���Ӵ�,�����Ƿ����ظ��ַ�,��ʵ������û�б�Ҫ�ġ����һ�������� i �� j - 1���Ӵ�??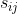 �Ѿ���鵽û���ظ��ַ���,�����Ǿ�ֻ��Ҫ���?
�Ѿ���鵽û���ظ��ַ���,�����Ǿ�ֻ��Ҫ���?![s\left [ j \right ]](http://style.iis7.com/uploads/2021/09/17464668295.gif) �Ƿ���??�о����ˡ�
�Ƿ���??�о����ˡ�
Ϊ�˼��һ���ַ��Ƿ��Ѿ�������Ӵ���,���ǿ���ѭ��ɨ������Ӵ������Ǹ��Ӷ�Ϊ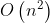 �����ǿ����û������ڷ��������Ż�,��HashSet��Ϊһ���������ڡ�
�����ǿ����û������ڷ��������Ż�,��HashSet��Ϊһ���������ڡ�
��������ָ������������ַ�����ijһ��Χ��Ԫ��,����:[i, j) �±귶Χ�ڵ�Ԫ�ء�������ǽ� [i, j) �����ƶ�һ��Ԫ�������� [i+1, j+1)��
������HashSet�洢���д��� [i, j) ���ַ�(��ʼʱ i = j)��Ȼ�����ǽ����� j ���һ���, ���(ָ����µ��ַ�)����HashSet����������һ���,ֱ�� s[j] �Ѿ���HashSet��Ϊֹ����Ȼ,���ظ��ַ�����Ӵ��Ǵ����� i ��ʼ�ġ������е� i ���д˲����Ϳ��Եõ��𰸡�
��������:
public class Solution{
public int lengthOfLongestSubString(String s){
int n = s.length(), ans = 0;
Set<Character> set = new HashSet<>();
int i = 0, j = 0;
while(i < n && j < n){
if(!set.contains(s.charAt(j))){ //������set�в���������j���ַ�
set.add(s.charAt(j++)); //�����ַ����뼯��set��,j++��������
and = Math.max(ans, j - i); //���½��
}
else{ //������set�а�������j���ַ�
set.remove(s.charAt(i++)); //������i���ַ��Ƴ�����set,i++����ѭ���ж�
}
}
return ans;
}
}
������:�����ƶ����Ż�?
�ڷ������п��Ժ����Կ�����,���������� j ָ����ַ����ڼ�����ʱ��Ҫһ��һ���ƶ� i ��ʵ���ϼ��� s[j] �� [i, j) ���ڷ�Χ�����ظ����ַ���������Ϊ j' ,���ǿ������� [i, j'] ��Χ�ڵ�����Ԫ��,ֱ���� i Ϊ j' + 1 ��
��˿�����HashMap��ÿ���ַ���������λ��һһ��Ӧ������
��������:
class Solution {
public int lengthOfLongestSubstring(String s) {
int ans = 0, n = s.length();
Map<Character, Integer> map = new HashMap<>(); //HashMap�洢(���ظ���)�ַ����ַ��±ꌝ
for(int i = 0, j = 0; j < n; j ++){
if(map.containsKey(s.charAt(j))){ //���µ��ַ��Ѿ���HashMap��
i = Math.max(map.get(s.charAt(j)), i); //�����ڵ����i�ƶ������ַ������ֵ�±�
}
ans = Math.max(ans, j - i + 1); //���㴰�ڴ�С
map.put(s.charAt(j), j + 1); //���µ��ַ�����HashMap��
}
return ans;
}
}
�����㷨��û�ж��ַ���? s? ʹ�õ��ַ������� ���衣����֪���ַ����Ǻ�С��,���ǿ��Խ� Map ��Ϊ����������ֱ�ӷ��ʡ�
�� index[65] ��ʾ�ַ� 'A' ������ֵ��(ע:��ASCII����� 'A' �� 65)
���ñ�ʾ����:
- int[26]? ? �����ַ� 'a' - 'z' ���� 'A' - 'Z'
- int[128]? �������е�ASCII��(ASCII�����ֻ��128���ַ�)
- int[256]? ������չ��ASCII��
���Ĵ�������:
public class Solution{
public int lengthOfLongestSubstring(String s){
int n = s.length(), ans = 0;
int[] index = new index[128]; //��ǰ�ַ�����������
for(int i = 0, j = 0; j < n; j++){
i = Math.max(index[s.charAt(j)], i); //�ҵ�j���ַ�������i�����ֵ,��������ظ�ȡi�����Ǹ�
ans = Math.max(ans, j - i + 1);
index[s.charAt(j)] = j + 1; //�洢j���ַ�������Ϊj+1
}
return ans;
}
}
?
cs