���� :�˹������Ǽ������ѧ��һ����֧,����ͼ�˽����ܵ�ʵ��,��������һ���µ����������������Ƶķ�ʽ������Ӧ�����ܻ�����
����966367816��ɨ����ĩ�Ķ�ά�������ȡAI��Ƶ����
1��������
����һЩfeature(����)���з���,ÿ���ڵ���һ������,ͨ���ж�,�����ݷ�Ϊ����,�ټ������ʡ���Щ�����Ǹ�����������ѧϰ������,��Ͷ�������ݵ�ʱ��,�Ϳ��Ը���������ϵ�����,�����ݻ��ֵ����ʵ�Ҷ���ϡ�
?2�����ɭ��
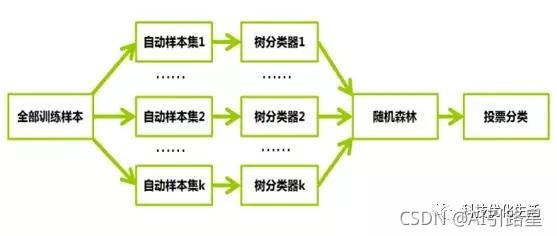
���ɭ���Ǽ���ѧϰ��һ������,�������ھ�������ͶƱѡ�����������ķ�����������ѧϰͨ����������ģ����ϵ��������һԤ�����⡣����ѧϰ�ļ�ԭ�������ɶ��������/ģ��,���Զ�����ѧϰ������Ԥ�⡣��ЩԤ������ϳɵ�Ԥ��,��������κ�һ�������������Ԥ�⡣
���ɭ�ֵĹ�������:
����N��ʾѵ������(����)����,M��ʾ������Ŀ,���ɭ�ֵĹ�����������:
- ?����������Ŀm,����ȷ����������һ���ڵ�ľ��߽��;����mӦԶС��M��
- ��N��ѵ������(����)�����зŻس����ķ�ʽ,ȡ��N��,�γ�һ��ѵ����,����δ�鵽������(����)��Ԥ��,��������
- ??����ÿһ���ڵ�,���ѡ��m������,��������ÿ���ڵ�ľ������ǻ�����Щ����ȷ���ġ�����m������,��������ѵķ��ѷ�ʽ��
- ÿ�������������ɳ��������֦,���п����ڽ���һ��������״��������ᱻ���á�
- ?�ظ���������,��������һ�ÿþ�����,ֱ���ﵽԤ����Ŀ��һȺ������Ϊֹ,�������������ɭ�֡�����,Ԥѡ��������(m)�����ɭ�������ĸ�������Ҫ����,��ϵͳ�ĵ��ŷdz��ؼ�����Щ�����ڵ������ɭ��ģ�͵�ȷ�Է���Ҳ����������Ҫ�����á���ѧ��ʹ����Щָ��,����������������ɭ��ģ����Ч�ʡ�
?3��?���ع�
������,���ع�ģ���Ǽල�����������ij�Ա֮һ�� Logistic �ع�ͨ��ʹ�����������Ƹ�����������������Ա���֮��Ĺ�ϵ��
���ع������Իع�����,�����ع�Ľ��ֻ����������ֵ�����˵���Իع�����Ԥ��һ�����ŵ���ֵ,�����ع��������һ���ǻ��ǵ��ж��⡣
��������Yֵ�ķ�Χ�� 0 �� 1,��һ������ֵ��������ͨ����S ��,���߰�ͼ���ֳ���������,����ʺ����ڷ�������
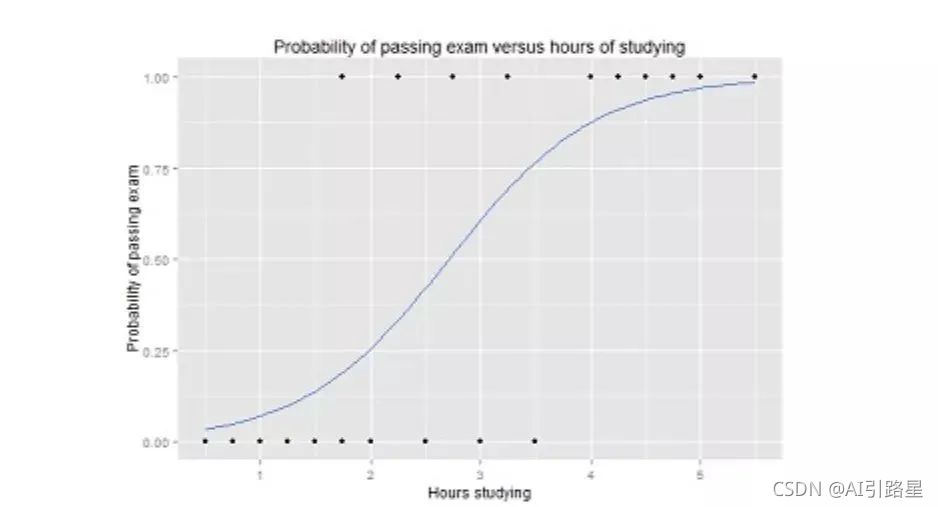
?������������ع�����ͼ,��ʾ��ͨ�����Եĸ�����ѧϰʱ��Ĺ�ϵ,��������Ԥ���Ƿ����ͨ�����ԡ�
4�����Իع�
��ν���Իع�,������������ͳ���еĻع����,��ȷ�����ֻ��������ϱ�����,������Ķ�����ϵ��һ��ͳ�Ʒ���������
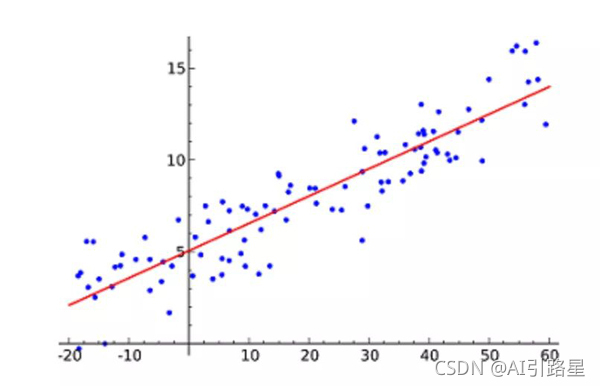
���Իع�(Linear Regression)�����������еĻ���ѧϰ�㷨������ͼͨ����ֱ�߷�����������������ʾ�Ա���(x ֵ)����ֵ���(y ֵ)��Ȼ��Ϳ�������������Ԥ��δ����ֵ!
�����㷨��õļ�������С���˷�(Least of squares)����������������������,��ʹ����ֱ����ÿ�����ݵ�Ĵ�ֱ������С���ܾ������������ݵ�Ĵ�ֱ����(����)��ƽ���͡���˼����ͨ����С�����ƽ��������������ģ�͡�
5�����ر�Ҷ˹
���ر�Ҷ˹(Naive Bayes)�ǻ��ڱ�Ҷ˹����,������������ϵ֮�䡣������ÿ����ĸ���,ÿ������������ʸ��� x ��ֵ������㷨���ڷ�������,�õ�һ�������ơ��� / �ǡ��Ľ����
���ر�Ҷ˹��������һ�����е�ͳ�Ƽ���,����Ӧ���ǹ��������ʼ���
6��������
Neural Networks�ʺ�һ��input���������������������:NN�����ɲ���Ԫ,������֮�����ϵ��ɡ���һ����input��,���һ����output�㡣��hidden���output�㶼���Լ���classifier��
input���뵽������,������,����ķ��������ݵ���һ��,����������,���output��Ľڵ��ϵķ����������ڸ���ķ���,��ͼ���ӵõ�������Ϊclass 1;ͬ����input�����䵽��ͬ�Ľڵ���,֮���Ի�õ���ͬ�Ľ������Ϊ���Խڵ��в�ͬ��weights��bias,��Ҳ����forward propagation��
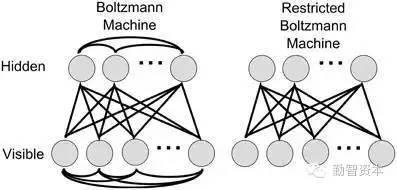
7��K- ��ֵ
K- ��ֵ(K-means)��ͨ�������ݼ����з���������ġ�����,����㷨�����ڸ��ݹ�����ʷ���û����顣�������ݼ����ҵ� K �����ࡣK- ��ֵ�����ලѧϰ,���,����ֻ��ʹ��ѵ������ X,�Լ�������Ҫʶ��ľ������� K��
��Ҫ��һ������,��Ϊ����,��ɫ��ֵ��,��ɫ��ֵС���ʼ�ȳ�ʼ��,������ѡ�����3,2,1��Ϊ����ij�ʼֵ��ʣ�µ�������,ÿ������������ʼֵ�������,Ȼ����ൽ��������ij�ʼֵ�������
��թ�����Ӧ�ù㷺,����ҽ�Ʊ��պͱ�����թ�������
8��֧��������
Ҫ������ֿ�,��Ҫ�õ�һ����ƽ��,���ŵij�ƽ���ǵ������ margin�ﵽ���,margin���dz�ƽ�����������һ��ľ��롣
��һ�����ڷ�������ļල�㷨��֧����������ͼ�����ݵ�֮�����������,����֮��ı߾����Ϊ��,���ǽ����������Ϊ n ά�ռ��еĵ�,����,n �������������������ڴ˻�����,֧���������ҵ�һ�����ű߽�,��Ϊ��ƽ��(Hyperplane),��ͨ�����ǩ�����ܵ����������ѷ��롣
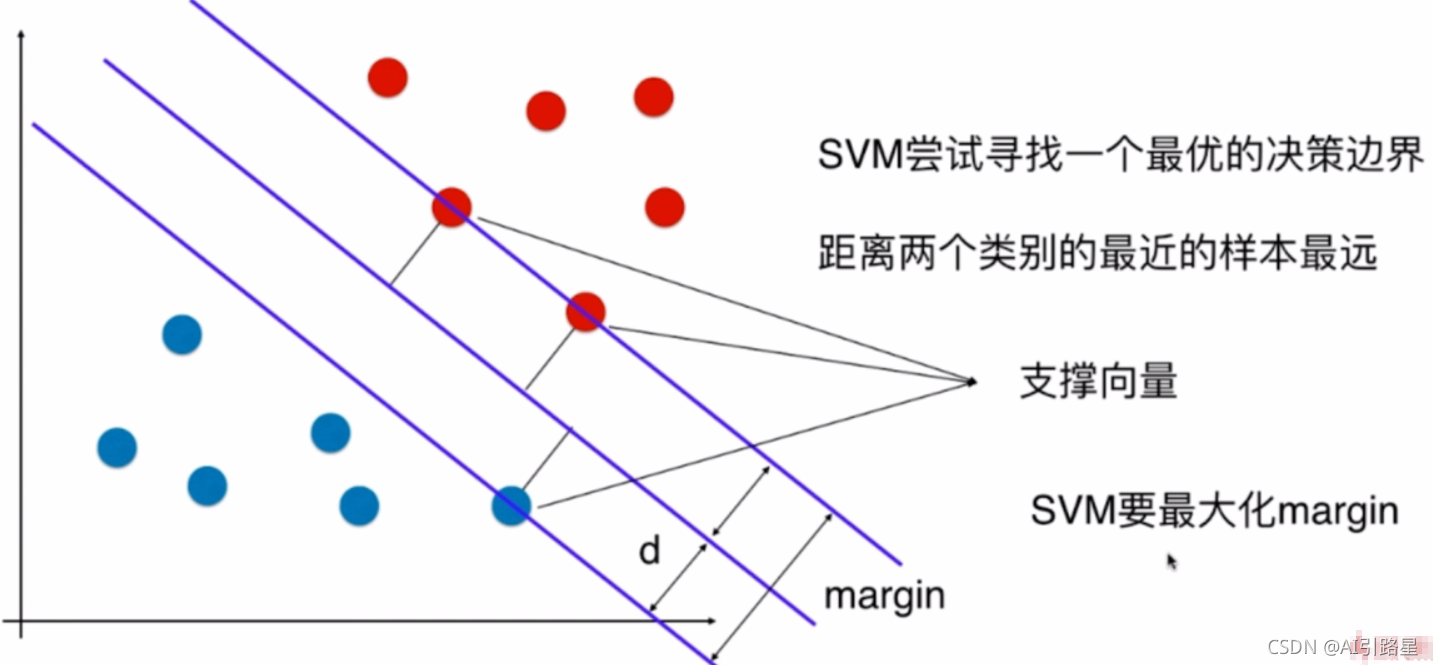
?Ӧ�����沿ʶ���ı������
9��K- ������㷨
��һ���µ�����ʱ,���������k������,�ĸ�����,������ݾ�������һ�ࡣ
���ӡ�Ҫ���֡�è���͡�����,ͨ����claws���͡�sound������feature���жϵĻ�,Բ�κ�����������֪�������,��ô�����star������������һ����?
?
?10����ά
��ά(Dimensionality reduction)��ͼ�ڲ���ʧ����Ҫ��Ϣ�������,ͨ�����ض���������ϳɸ��߲�ε����������������⡣���ɷַ���(Principal Component Analysis,PCA)�������еĽ�ά������
���ɷַ���ͨ�������ݼ�ѹ������ά��ƽ�� / �ӿռ����������ݼ���ά�����⾡���ܵر�����ԭʼ���ݵ�����������
�����ѧϰ�˹����ܵ�·������ʲô���ⶼ���Լ�V����ѽ~ ����ѧ·���и��˸�����ȷ��ѧϰ������ĺ�����,��������Ҫ���������Լ�V,���Ż��������ܶ�ġ�
������Ҫ�����˹�����ѧϰ���ϵ�С���ɼ���,qqѧϰ��������Ⱥ:966367816,����Ĵ����⡢������Դ��������С��Ŀ����˽����ȡѧϰ��!
��ӭ���ɨ��?��ȡAI�����Ƶ����

cs