ԭ�ĵ�ַ:ʮ���㷨�ܽ�
�ڴ�ͳ�ļ�����㷨�����ݽṹ����,�����רҵ�̲ĺ��鼮��Ĭ�����Զ���C/C+ +,���ǽ������ǻ�����JavaScript��������!
�㷨������:9���Ͳ�˹��ѧ�������:��al-Khowarizmi��������ͼ���(�о���Ҫ��ѧԪ�������ò�ƶ����˶���ñ��),������Ц,�������˶�����ѧʷ�Ĺ�����ֵ���˾���ġ�?

����
�����㷨˵��
(1)����Ķ���:��һ���ж������ij���ؼ��ֽ�������;
����:n����:a1,a2,a3,...,an ���:n����������:a1',a2',a3',...,an',ʹ��a1'<=a2'<=a3'<=...<=an'��
�ٽ�����������������,����λ,�ߵ�վ�ں���,����վ��ǰ�濩��
(3)���������㷨���������˵��
�ȶ�:���aԭ����bǰ��,��a=b,����֮��a��Ȼ��b��ǰ��;?���ȶ�:���aԭ����b��ǰ��,��a=b,����֮��a���ܻ������b�ĺ���;
������:����������������ڴ������;?������:��������̫��,��˰����ݷ��ڴ�����,������ͨ�����̺��ڴ�����ݴ�����ܽ���;
ʱ�临�Ӷ�: һ���㷨ִ�����ķѵ�ʱ�䡣?�ռ临�Ӷ�: ������һ�����������ڴ�Ĵ�С��
����ʱ��ռ临�Ӷȵĸ����˽��������,���ǿ���ܴ̽���д�ġ������ݽṹ�����Ǻ���,ͨ������
(4)�����㷨ͼƬ�ܽ�(ͼƬ��Դ������):
����Ա�:
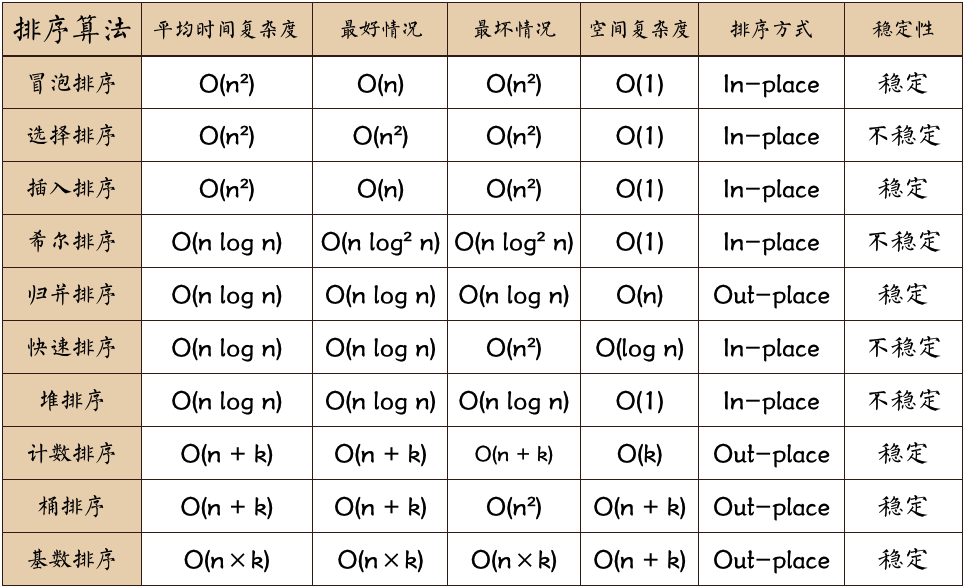
ͼƬ���ʽ���:?n: ���ݹ�ģ k:��Ͱ���ĸ��� In-place: ռ�ó����ڴ�,��ռ�ö����ڴ� Out-place: ռ�ö����ڴ�
�������:
1.����(Bubble Sort)
�õ�,��ʼ�ܽ��һ�������㷨,ð���������������ÿ��ѧ��C���ԵĶ����˽�İ�,������Ǻܶ��˽Ӵ��ĵ�һ�������㷨��
(1)�㷨����
ð��������һ�ּ������㷨�����ظ����߷ù�Ҫ���������,һ�αȽ�����Ԫ��,������ǵ�˳�����Ͱ����ǽ����������߷����еĹ������ظ��ؽ���ֱ��û������Ҫ����,Ҳ����˵�������Ѿ�������ɡ�����㷨��������������ΪԽС��Ԫ�ػᾭ�ɽ������������������еĶ��ˡ�
(2)�㷨������ʵ��
�����㷨��������:
<1>.�Ƚ����ڵ�Ԫ�ء������һ���ȵڶ�����,�ͽ�����������;
<2>.��ÿһ������Ԫ����ͬ���Ĺ���,�ӿ�ʼ��һ�Ե���β�����һ��,����������Ԫ��Ӧ�û���������;
<3>.������е�Ԫ���ظ����ϵIJ���,�������һ��;
<4>.�ظ�����1~3,ֱ��������ɡ�
JavaScript����ʵ��:

�Ľ�ð������:?����һ��־�Ա���pos,���ڼ�¼ÿ�����������һ�ν��н�����λ�á�����posλ��֮��ļ�¼���ѽ�����λ,���ڽ�����һ������ʱֻҪɨ�赽posλ�ü��ɡ�
�Ľ����㷨����:

��ͳð��������ÿһ���������ֻ���ҵ�һ�����ֵ����Сֵ,���ǿ���������ÿ�������н�������ͷ�������ð�ݵķ���һ�ο��Եõ���������ֵ(����ߺ���С��) , �Ӷ�ʹ������������������һ�롣
�Ľ�����㷨ʵ��Ϊ:

���ַ�����ʱ�Ա�:
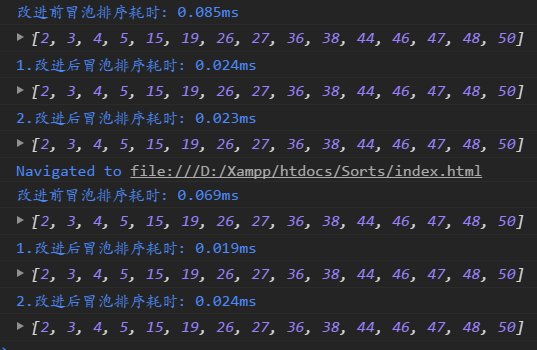
��ͼ���Կ����Ľ����ð���������Ե�ʱ�临�Ӷȸ���,��ʱ�����ˡ��������г��Կ��Դ���,������github���˸���,���߿���Clone�������س��ԡ��˲������Դ���������Ŷ~~~
ð������ͼ��ʾ:
(3)�㷨����
������:T(n) = O(n)
������������Ѿ�������ʱ(���Ѿ���������,Ϊë�αػ�������....)
������:T(n) = O(n2)
������������Ƿ���ʱ(�Բ�,��ֱ�ӷ�������....)
ƽ�����:T(n) = O(n2)
2.ѡ������(Selection Sort)
�������ȶ��������㷨֮һ(����ȶ�����ָ�㷨�����ϵ��ȶ���,���Ŵ���������������˵����˼2333),��Ϊ����ʲô���ݽ�ȥ����O(n2)��ʱ �临�Ӷ�.....�����õ�����ʱ��,���ݹ�ģԽСԽ�á�Ψһ�ĺô����ܾ��Dz�ռ�ö�����ڴ�ռ��˰ɡ������Ͻ�,ѡ���������Ҳ��ƽʱ����һ�����뵽�� ���������˰ɡ�
(1)�㷨���
ѡ������(Selection-sort)��һ�ּ�ֱ�۵������㷨�����Ĺ���ԭ��:������δ�����������ҵ���С(��)Ԫ��,��ŵ��������е���ʼλ��,Ȼ��,�ٴ�ʣ��δ����Ԫ���м���Ѱ����С(��)Ԫ��,Ȼ��ŵ����������е�ĩβ���Դ�����,ֱ������Ԫ�ؾ�������ϡ�
(2)�㷨������ʵ��
n����¼��ֱ��ѡ������ɾ���n-1��ֱ��ѡ������õ��������������㷨��������:
<1>.��ʼ״̬:������ΪR[1..n],������Ϊ��;
<2>.��i������(i=1,2,3...n-1)��ʼʱ,��ǰ���������������ֱ�ΪR[1..i-1]��R(i..n)���������� �ӵ�ǰ��������-ѡ���ؼ�����С�ļ�¼ R[k],�������������ĵ�1����¼R����,ʹR[1..i]��R[i+1..n)�ֱ��Ϊ��¼��������1�������������ͼ�¼��������1������������;
<3>.n-1�˽���,���������ˡ�
Javascript����ʵ��:

ѡ������ͼ��ʾ:
(3)�㷨����
������:T(n) = O(n2)
������:T(n) = O(n2)
ƽ�����:T(n) = O(n2)
3.��������(Insertion Sort)
��������Ĵ���ʵ����Ȼû��ð�������ѡ��������ô�ֱ�,������ԭ��Ӧ�����������������,��ΪֻҪ����˿��Ƶ��˶�Ӧ���ܹ��붮����Ȼ,�����˵����˿������Ƶ�ʱ����������ƵĴ�С������,�ǹ����Ⱳ����Բ���������㷨����������κ���Ȥ��.....
(1)�㷨���
��������(Insertion-Sort)���㷨������һ�ּ�ֱ�۵������㷨�����Ĺ���ԭ����ͨ��������������,����δ��������,�������������дӺ��� ǰɨ��,�ҵ���Ӧλ�ò����롣����������ʵ����,ͨ������in-place����(��ֻ���õ�O(1)�Ķ���ռ������),����ڴӺ���ǰɨ�������,��Ҫ ������������Ԫ�������Ųλ,Ϊ����Ԫ���ṩ����ռ䡣
(2)�㷨������ʵ��
һ����˵,����������in-place��������ʵ�֡������㷨��������:
<1>.�ӵ�һ��Ԫ�ؿ�ʼ,��Ԫ�ؿ�����Ϊ�Ѿ�������;
<2>.ȡ����һ��Ԫ��,���Ѿ������Ԫ�������дӺ���ǰɨ��;
<3>.�����Ԫ��(������)������Ԫ��,����Ԫ���Ƶ���һλ��;
<4>.�ظ�����3,ֱ���ҵ��������Ԫ��С�ڻ��ߵ�����Ԫ�ص�λ��;
<5>.����Ԫ�ز��뵽��λ�ú�;
<6>.�ظ�����2~5��
Javascript����ʵ��:

�Ľ���������:?���Ҳ���λ��ʱʹ�ö��ֲ��ҵķ�ʽ

�Ľ�ǰ��Ա�:
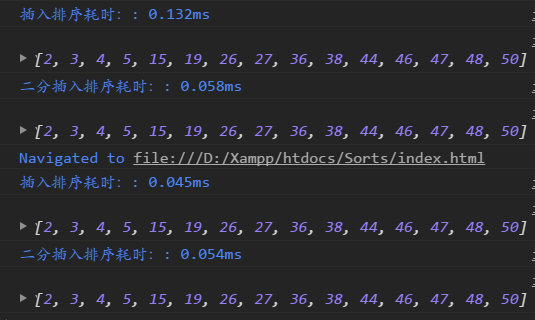
��������ͼ��ʾ:
(3)�㷨����
������:�������鰴�������С�T(n) = O(n)
����:�������鰴�������С�T(n) = O(n2)
ƽ�����:T(n) = O(n2)
4.ϣ������(Shell Sort)
1959��Shell����; ��һ��ͻ��O(n^2)�������㷨;�Ǽ�������ĸĽ���;�����������IJ�֮ͬ������,�������ȱȽϾ����Զ��Ԫ�ء�ϣ�������ֽ���С��������
(1)�㷨���
ϣ������ĺ������ڼ�����е��趨���ȿ�����ǰ�趨�ü������,Ҳ���Զ�̬�Ķ��������С���̬���������е��㷨�ǡ��㷨(��4�桷�ĺ�����Robert Sedgewick����ġ�
(2)�㷨������ʵ��
�Ƚ�����������ļ�¼���зָ��Ϊ���������зֱ����ֱ�Ӳ�������,�����㷨����:
<1>. ѡ��һ����������t1,t2,��,tk,����ti>tj,tk=1;
<2>.�����������k,�������k ������;
<3>.ÿ������,���ݶ�Ӧ������ti,���������зָ�����ɳ���Ϊm ��������,�ֱ�Ը��ӱ�����ֱ�Ӳ���������������Ϊ1 ʱ,����������Ϊһ����������,�����ȼ�Ϊ�������еij��ȡ�
Javascript����ʵ��:

ϣ������ͼʾ(ͼƬ��Դ����):
(3)�㷨����
������:T(n) = O(nlog2 n)
����:T(n) = O(nlog2 n)
ƽ�����:T(n) =O(nlog n)
5.�鲢����(Merge Sort)
��ѡ������һ��,�鲢��������ܲ����������ݵ�Ӱ��,�����ֱ�ѡ������õĶ�,��Ϊʼ�ն���O(n log n)��ʱ�临�Ӷȡ���������Ҫ������ڴ�ռ䡣
(1)�㷨���
���鲢�����ǽ����ڹ鲢�����ϵ�һ����Ч�������㷨�����㷨�Dz��÷��η�(Divide and Conquer)��һ���dz����͵�Ӧ�á��鲢������һ���ȶ�����������������������кϲ�,�õ���ȫ���������;����ʹÿ������������,��ʹ�����ж� ��������������������ϲ���һ�������,��Ϊ2-·�鲢��
(2)�㷨������ʵ��
�����㷨��������:
<1>.�ѳ���Ϊn���������зֳ���������Ϊn/2��������;
<2>.�������������зֱ���ù鲢����;
<3>.����������õ������кϲ���һ�����յ��������С�
Javscript����ʵ��:

�鲢����ͼ��ʾ:
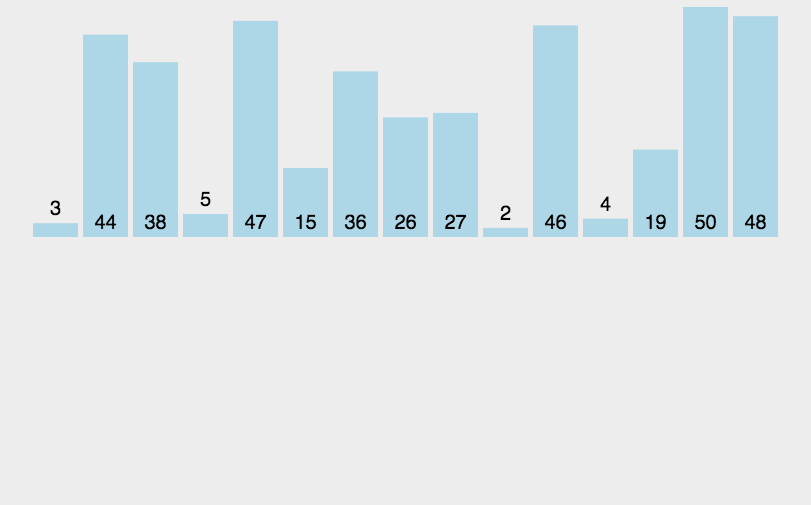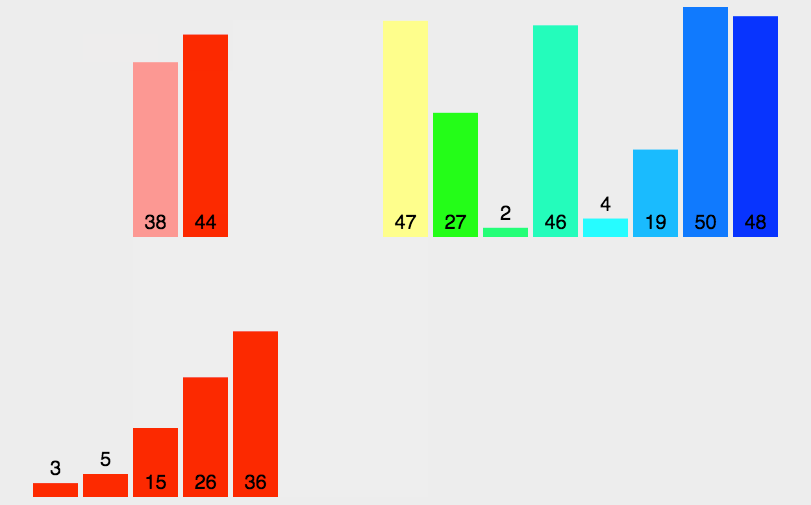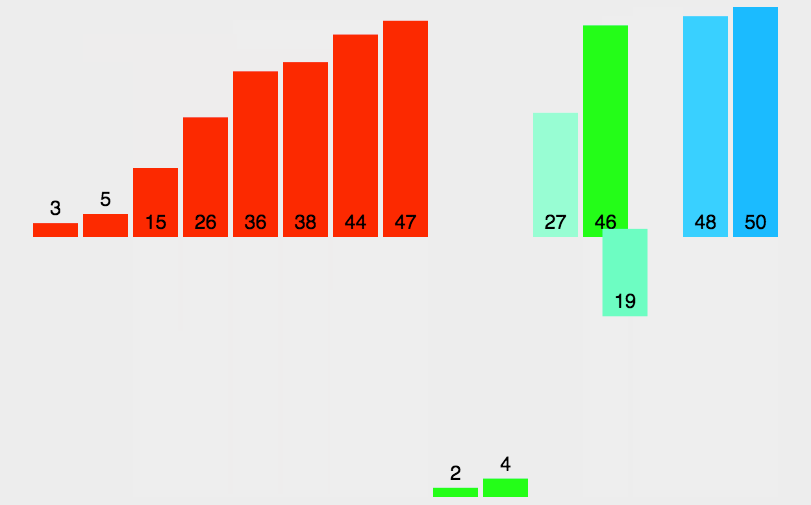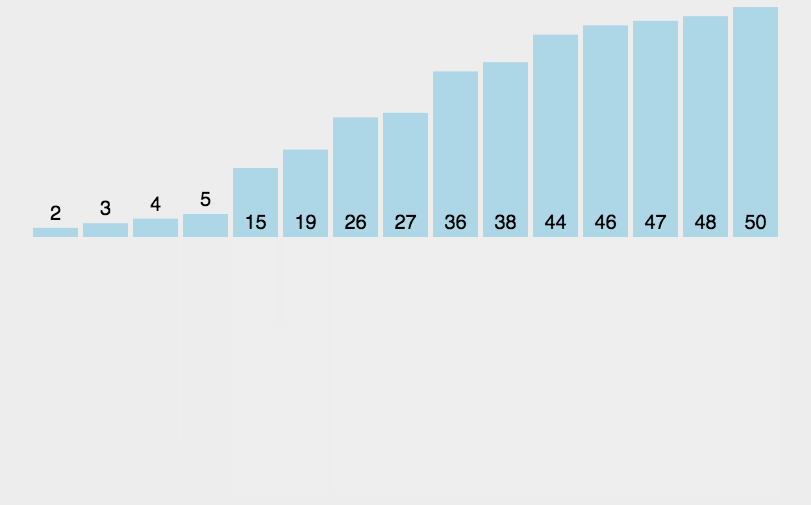
(3)�㷨����
������:T(n) = O(n)
������:T(n) = O(nlogn)
ƽ�����:T(n) = O(nlogn)
6.��������(Quick Sort)
�����������������Ǽֱ�,��Ϊһ��������������֪�������ڵ�����,���ǿ�,����Ч�ʸ�! ���Ǵ������������������㷨֮һ�ˡ�
(1)�㷨���
��������Ļ���˼��:ͨ��һ�������ż�¼�ָ��ɶ�����������,����һ���ּ�¼�Ĺؼ��־�����һ���ֵĹؼ���С,��ɷֱ���������ּ�¼������������,�Դﵽ������������
(2)�㷨������ʵ��
��������ʹ�÷��η�����һ����(list)��Ϊ�����Ӵ�(sub-lists)�������㷨��������:
<1>.������������һ��Ԫ��,��Ϊ "��"(pivot);
<2>.������������,����Ԫ�رȻ�ֵС�İڷ��ڻ�ǰ��,����Ԫ�رȻ�ֵ��İ��ڻ��ĺ���(��ͬ�������Ե���һ��)������������˳�֮��,�û��ʹ������е��м�λ�á������Ϊ����(partition)����;
<3>.�ݹ��(recursive)��С�ڻ�ֵԪ�ص������кʹ��ڻ�ֵԪ�ص�����������
Javascript����ʵ��:

��������ͼ��ʾ:
(3)�㷨����
������:T(n) = O(nlogn)
������:T(n) = O(n2)
ƽ�����:T(n) = O(nlogn)
7.������(Heap Sort)
���������˵��һ�����öѵĸ����������ѡ������
(1)�㷨���
������(Heapsort)��ָ���ö��������ݽṹ����Ƶ�һ�������㷨���ѻ���һ��������ȫ�������Ľṹ,��ͬʱ����ѻ�������:���ӽ��ļ�ֵ����������С��(���ߴ���)���ĸ��ڵ㡣
(2)�㷨������ʵ��
�����㷨��������:
<1>.����ʼ������ؼ�������(R1,R2....Rn)�����ɴ�,�˶�Ϊ��ʼ��������;
<2>.���Ѷ�Ԫ��R[1]�����һ��Ԫ��R[n]����,��ʱ�õ��µ�������(R1,R2,......Rn-1)���µ�������(Rn),������R[1,2...n-1]<=R[n];
<3>.���ڽ������µĶѶ�R[1]����Υ���ѵ�����,�����Ҫ�Ե�ǰ������(R1,R2,......Rn-1)����Ϊ�¶�,Ȼ�� �ٴν�R[1]�����������һ��Ԫ�ؽ���,�õ��µ�������(R1,R2....Rn-2)���µ�������(Rn-1,Rn)�������ظ��˹���ֱ����������Ԫ �ظ���Ϊn-1,���������������ɡ�
Javascript����ʵ��:


������ͼ��ʾ:

(3)�㷨����
������:T(n) = O(nlogn)
������:T(n) = O(nlogn)
ƽ�����:T(n) = O(nlogn)
8.��������(Counting Sort)
��������ĺ������ڽ����������ֵת��Ϊ���洢�ڶ���ٵ�����ռ��С� ��Ϊһ������ʱ�临�Ӷȵ�����,��������Ҫ����������ݱ�������ȷ����Χ��������
(1)�㷨���
��������(Counting sort)��һ���ȶ��������㷨����������ʹ��һ�����������C,���е�i��Ԫ���Ǵ���������A��ֵ����i��Ԫ�صĸ�����Ȼ���������C����A�е�Ԫ���ŵ���ȷ��λ�á���ֻ�ܶ�������������
(2)�㷨������ʵ��
�����㷨��������:
<1>. �ҳ��������������������С��Ԫ��;
<2>. ͳ��������ÿ��ֵΪi��Ԫ�س��ֵĴ���,��������C�ĵ�i��;
<3>. �����еļ����ۼ�(��C�еĵ�һ��Ԫ�ؿ�ʼ,ÿһ���ǰһ�����);
<4>. �������Ŀ������:��ÿ��Ԫ��i����������ĵ�C(i)��,ÿ��һ��Ԫ�ؾͽ�C(i)��ȥ1��
Javascript����ʵ��:

��ͼ��ʾ:��

(3)�㷨����
�������Ԫ����n ��0��k֮�������ʱ,��������ʱ���� O(n + k)�����������DZȽ�����,������ٶȿ����καȽ������㷨��������������������C�ij���ȡ���ڴ��������������ݵķ�Χ(���ڴ�������������ֵ����С ֵ�IJ����1),��ʹ�ü�������������ݷ�Χ�ܴ������,��Ҫ����ʱ����ڴ档
������:T(n) = O(n+k)
������:T(n) = O(n+k)
ƽ�����:T(n) = O(n+k)
9.Ͱ����(Bucket Sort)
Ͱ�����Ǽ�������������档�������˺�����ӳ���ϵ,��Ч���Ĺؼ����������ӳ�亯����ȷ����
(1)�㷨���
Ͱ���� (Bucket sort)�Ĺ�����ԭ��:�����������ݷ��Ӿ��ȷֲ�,�����ݷֵ�����������Ͱ��,ÿ��Ͱ�ٷֱ�����(�п�����ʹ�ñ�������㷨�����Եݹ鷽ʽ����ʹ��Ͱ���������
(2)�㷨������ʵ��
�����㷨��������:
<1>.����һ�����������鵱����Ͱ;
<2>.������������,���Ұ�����һ��һ���ŵ���Ӧ��Ͱ��ȥ;
<3>.��ÿ�����ǿյ�Ͱ��������;
<4>.�Ӳ��ǿյ�Ͱ����ź��������ƴ��������
Javascript����ʵ��:

Ͱ����ͼʾ:
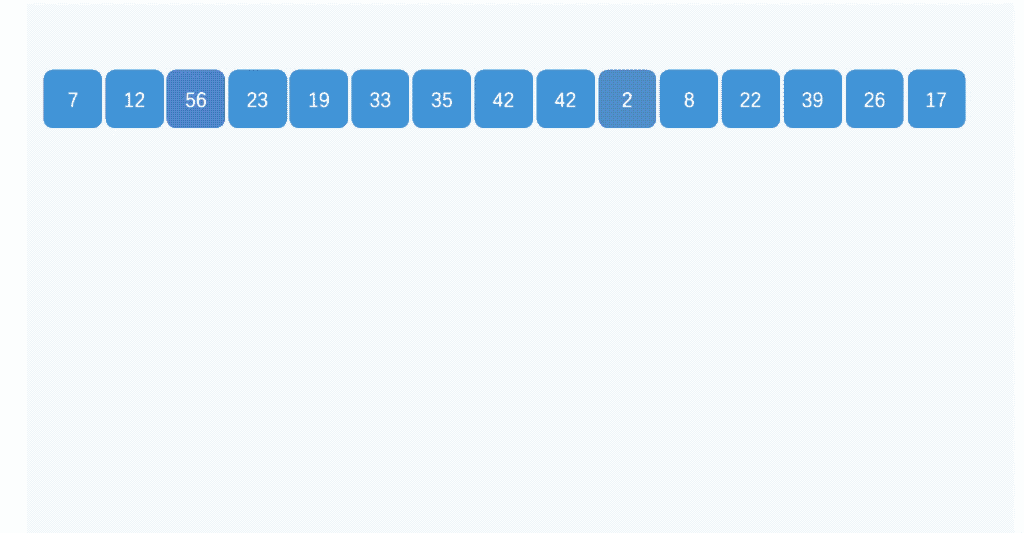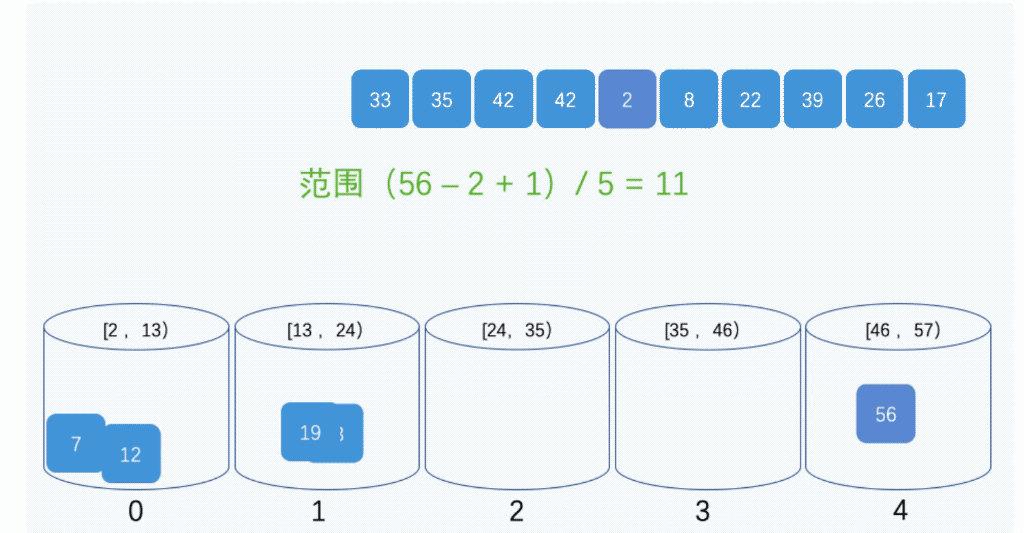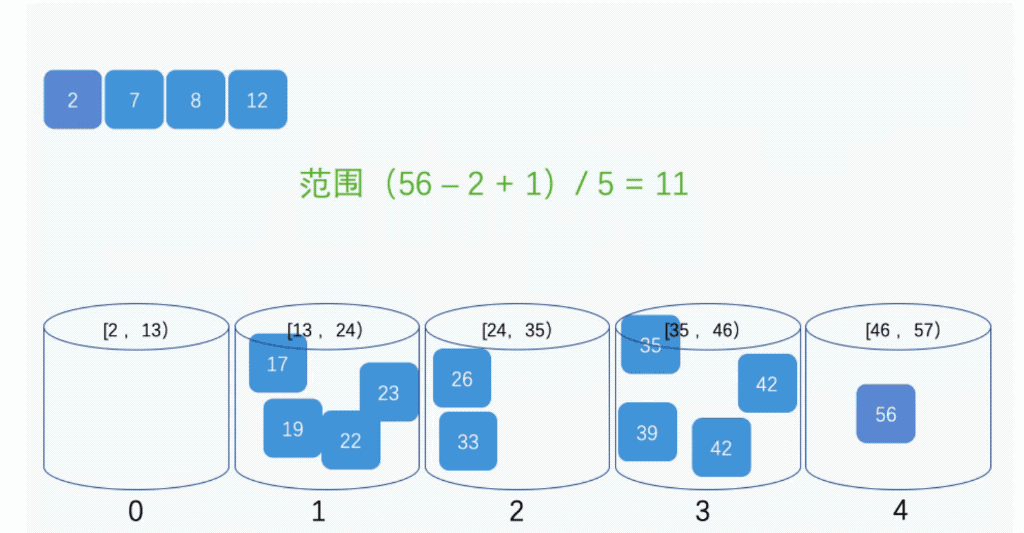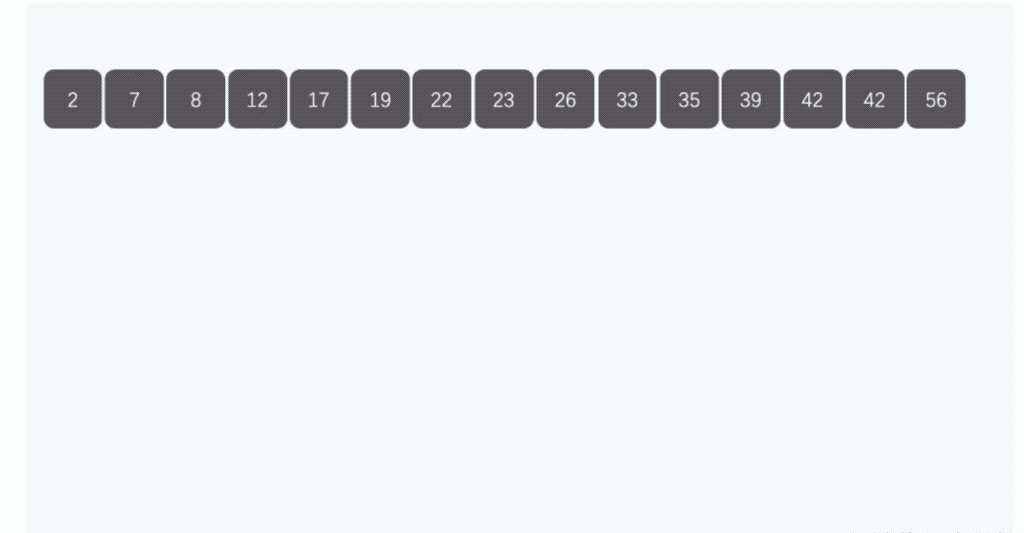
(3)�㷨����
��Ͱ������������ʹ������ʱ��O(n),Ͱ�����ʱ�临�Ӷ�,ȡ����Ը���Ͱ֮�����ݽ��������ʱ�临�Ӷ�,��Ϊ�������ֵ�ʱ�临�Ӷȶ�ΪO(n)������Ȼ,Ͱ���ֵ�ԽС,����Ͱ֮�������Խ��,�������õ�ʱ��Ҳ��Խ�١�����Ӧ�Ŀռ����ľͻ�����
������:T(n) = O(n+k)
������:T(n) = O(n+k)
ƽ�����:T(n) = O(n2)
10.��������(Radix Sort)
��������Ҳ�ǷDZȽϵ������㷨,��ÿһλ��������,�����λ��ʼ����,���Ӷ�ΪO(kn),Ϊ���鳤��,kΪ�����е���������λ��;
(1)�㷨���
���������ǰ��յ�λ������,Ȼ���ռ�;�ٰ��ո�λ����,Ȼ�����ռ�;��������,ֱ�����λ����ʱ����Щ�����������ȼ�˳���,�Ȱ������ȼ�����,�� �������ȼ��������Ĵ�����Ǹ����ȼ��ߵ���ǰ,�����ȼ���ͬ�ĵ����ȼ��ߵ���ǰ������������ڷֱ�����,�ֱ��ռ�,�������ȶ��ġ�
(2)�㷨������ʵ��
�����㷨��������:
<1>.ȡ�������е������,��ȡ��λ��;
<2>.arrΪԭʼ����,�����λ��ʼȡÿ��λ���radix����;
<3>.��radix���м�������(���ü�������������С��Χ�����ص�);
Javascript����ʵ��:

��������LSD��ͼ��ʾ:

(3)�㷨����
������:T(n) = O(n * k)
������:T(n) = O(n * k)
ƽ�����:T(n) = O(n * k)
�������������ַ���:
MSD �Ӹ�λ��ʼ��������
LSD �ӵ�λ��ʼ��������
�������� vs �������� vs Ͱ����
�����������㷨��������Ͱ�ĸ���,����Ͱ��ʹ�÷����������Բ���:
��������:���ݼ�ֵ��ÿλ����������Ͱ
��������:ÿ��Ͱֻ�洢��һ��ֵ
Ͱ����:ÿ��Ͱ�洢һ����Χ����ֵ
���˵һ��:
��һ�������˵ĽǶ���˵,����ѧ��̷�����ĺ���Ҫ,��Ȼ�ͻ���ɸ�����,��Ч�ܵ���������������õ�������ı�̺�������(�ڹ�),������������Ҳ����ȥ����,�Ի�������ͦ�а����ġ�
C����C++���ѧϰ����Ȧ��,QQȺ:614504899������������Ź��ں�:C���Ա��ѧϰ����
��������(����ѧϰ��Դ�롢��Ŀʵս��Ƶ����Ŀ�ʼ�,�������Ž̳�)
��ӭת�к�ѧϰ��̵Ļ��,���ø��������ѧϰ�ɳ����Լ���ĥ����Ŷ!
���ѧϰ��Ƶ����:
cs