1、简单案例
1.1、简介
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装,pip install jieba
- jieba库提供三种分词模式,最简单只需掌握一个函数
实现原理:依靠中文词库
- 利用一个中文词库,确定中文字符之间的关联概率
- 中文字符间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
分词的三种模式
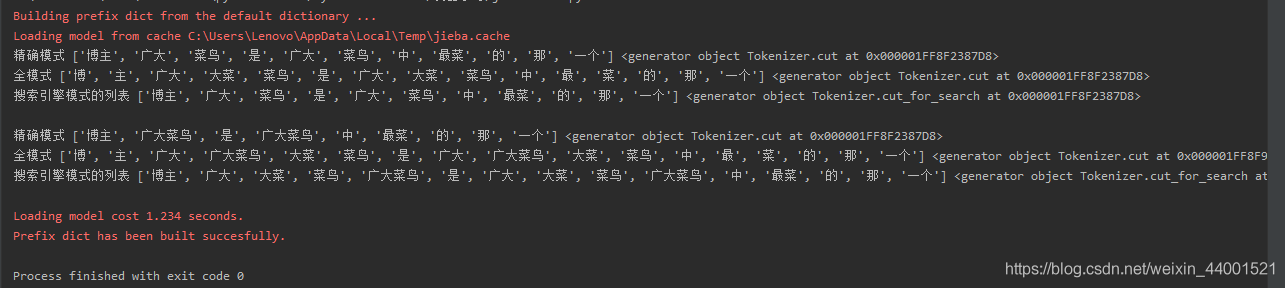
- 精确模式:把文本精确的切分开,不存在冗余单词 cut(s) 可迭代的数据类型<class ‘generator’>
- 全模式:把文本中所有可能的词语都扫描出来,有冗余 cut(s,cut_all=True) 所有可能的单词<class ‘generator’>
- 搜索引擎模式:在精确模式基础上,对长词再次切分 cut_for_search(s) 适合搜索引擎建立索引的分词<class ‘generator’>
import jieba
def test_jieba(s):
print("精确模式", jieba.lcut(s), jieba.cut(s))
print("全模式", jieba.lcut(s, cut_all=True), jieba.cut(s, cut_all=True))
print("搜索引擎模式的列表", jieba.lcut_for_search(s), jieba.cut_for_search(s))
print()
s = '博主广大菜鸟是广大菜鸟中最菜的那一个'
test_jieba(s)
jieba.add_word('广大菜鸟')
test_jieba(s)
2、实例:分析词频
2.1、英文文本:Hamet 分析词频
https://python123.io/resources/pye/hamlet.txt
import urllib.request
def geTxt():
txt = urllib.request.urlopen("https://python123.io/resources/pye/hamlet.txt").read().decode()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ")
return txt
if __name__ == '__main__':
hamletTxt = geTxt()
words = hamletTxt.split()
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
items_list = list(counts.items())
items_list.sort(key=lambda x: x[1], reverse=True)
for i in range(len(items_list)):
(word, count) = items_list[i]
print('{0:<10}{1:>5}'.format(word, count))
2.2、中文文本:《三国演义》 分析人物
https://python123.io/resources/pye/threekingdoms.txt
import urllib.request
import jieba
def geTxt():
txt = urllib.request.urlopen("https://python123.io/resources/pye/threekingdoms.txt").read().decode()
words = jieba.lcut(txt)
return words
if __name__ == '__main__':
words = geTxt()
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items_list = list(counts.items())
items_list.sort(key=lambda x: x[1], reverse=True)
for i in range(len(items_list)):
(word, count) = items_list[i]
print('{0:<10}{1:>5}'.format(word, count))
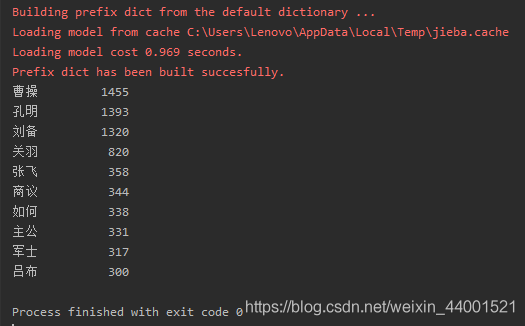
统计出场最频繁前10名
import jieba
txt = open("C:\\Users\\Lenovo\\Desktop\\threekingdoms.txt", "r", encoding="utf-8").read()
excludes = {"将军", "却说", "荆州", "二人", "不可", "不能", "如此"}
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰" or word == '诸葛孔明':
rword = "孔明"
elif word == "关公" or word == "云长" or word == '关云长':
rword = "关羽"
elif word == "玄德" or word == "玄德曰" or word == '刘玄德':
rword = "刘备"
elif word == "孟德" or word == "丞相" or word == '曹阿瞒':
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
cs