吸取我无,分享我有
时至今日,大前端思想已经深入人心,很多知识都要涉及到。所以对于现在的前端儿来说也是来着不拒的,练就吸星大法的时候,尽量多的吸收知识,最后达到物尽其用的效果
最近,我也是一直在学习关于爬虫方面的知识,源于之前项目中需要用到的地铁信息数据并不是用爬虫爬下来的数据,而是直接copy的
尽管这些数据一时半会确实不会有太大的变化,不过总觉得还是有些low的。于是学习了关于爬虫的知识后,打算和大家一起探讨交流一番,下面直接进入正题
首先,先来说一下爬虫和Robots协议是什么
然后再来介绍爬虫的基本流程
最后根据实际栗子爬一个豆瓣最近上映的电影来小试牛刀一把
爬虫及Robots协议
先看定义:爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。
再看下Robots协议的介绍,robots.txt是一个文本文件,robots.txt是一个协议不是一个命令
robots.txt是爬虫要查看的第一个文件,robots.txt告诉爬虫在服务器上什么文件是可以被查看的,爬虫机器人就会按照文件中的内容来确定访问范围
下图是豆瓣电影页面关于robots协议列出来的访问范围
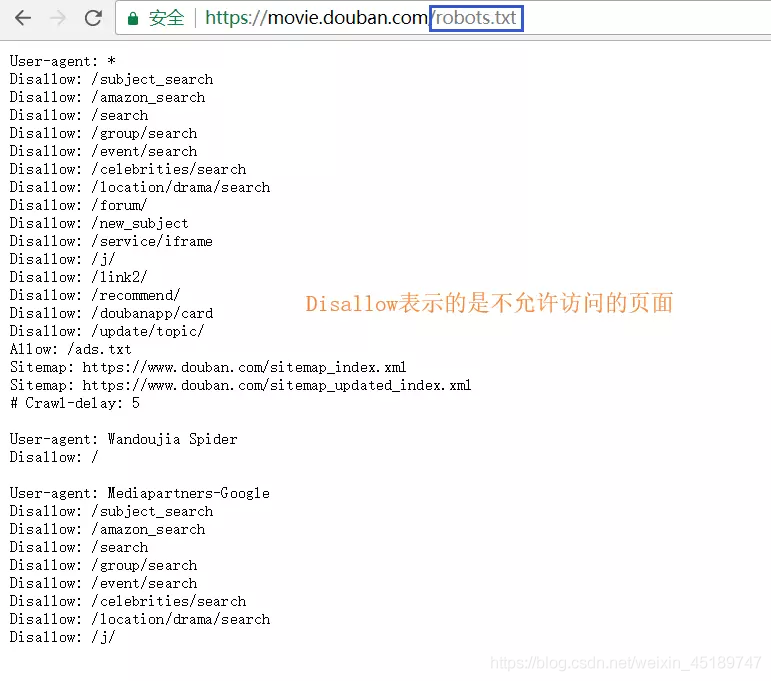
爬虫和Robots协议是紧密相连的,图上看到的不允许爬的页面就不要去爬,万一涉及到一些用户隐私等方面的东西,之后会被发现而走到法律途径的
所以在业内大家也都是认可这个Robots协议的,不让你爬的页面就不要爬,还互联网一片安宁即可了
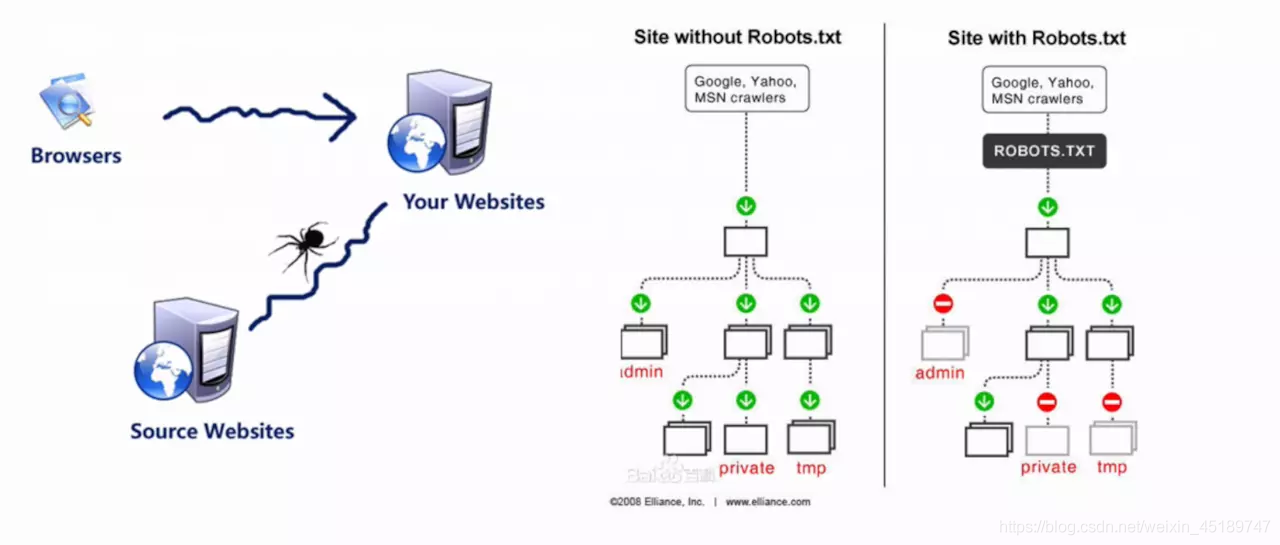
有点跑偏了,下面再看一张图,来简单梳理一下上面说的内容
其实有的人会问,爬虫到底爬的是什么?
这是有一个很有见地的问题,说白了爬虫拿到的一段是html代码,所以说这个对于我们来说并不陌生了,只要我们把它转换成DOM树就可以了
那么,现在再看上图的右半部份,这是一个对比图
左边的是没有限定Robots协议的,按道理来说admin/private和tmp这三个文件夹是不能抓的,但是由于没有Robots协议,人家就可以肆无忌惮的爬
再看右边的是限定了Robots协议的,与之相反,像Google这样的搜索引擎也是通过Robots.txt文件去看一下哪些是不能抓的,然后到admin或private这里的时候就直接跳过,不去抓取了
好了,介绍的内容就说到这里吧,不来点真刀真枪的东西全都是纸上谈兵了
爬虫的基本流程
其实对于使用爬虫来说,流程无外乎这四步
- 抓取数据
- 数据入库
- 启动服务
- 渲染数据
抓取数据
下面就进入激动人心的环节了,大家不要停,跟着我一起手敲出一个爬取豆瓣电影的页面出来供自己欣赏欣赏
先来看一下整体目录结构
既然是抓取数据,我们就得使用业界较为出名的神器------request
request神器
那么request到底如何用之,且听风吟一起看代码
// 使用起来超简单
let request = require('request');
request('http://www.baidu.com', function (error, response, body) {
console.log('error:', error); // 当有错误发生时打印错误日志
console.log('statusCode:', response && response.statusCode); // 打印响应状态码
console.log('body:', body); // 打印百度页面的html代码
});
复制代码
看完上面的代码,难道你还觉得不明显嘛。朋友,html代码已经出现在眼前了,那么就别矜持了,只要转成熟悉的DOM就可以为所欲为了
于是乎,cheerio登场了,大家都称它是Node版的jq。你就完全按照jq的习惯来操作DOM就可以了
下面也不再绕弯子了,赶紧一起写爬虫吧!
读取内容
首页要先根据豆瓣电影的页面来分析一下,哪些是正在热映的电影,先来看看DOM结构
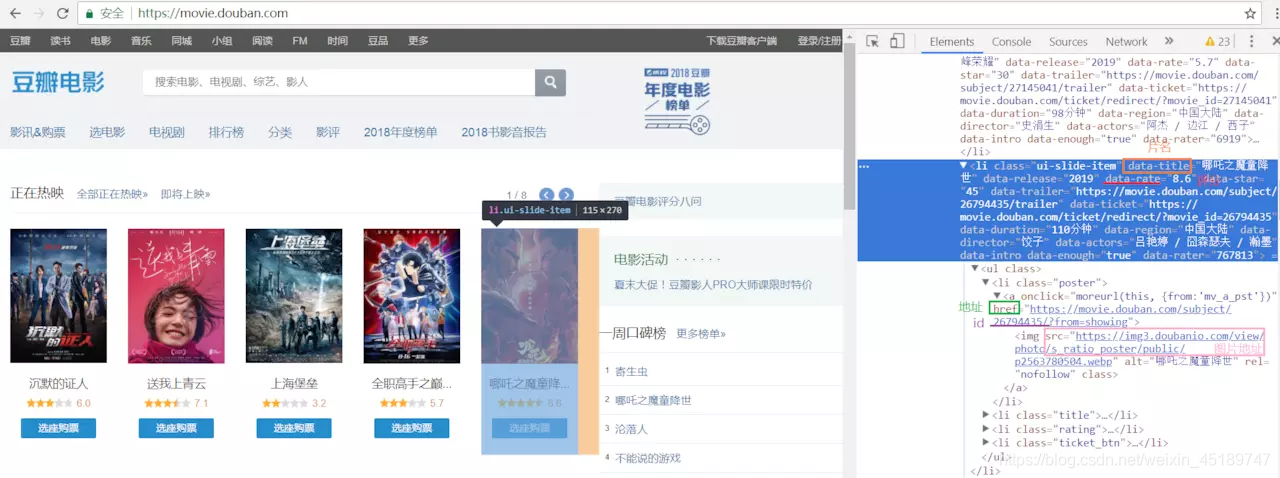
好了,看完了噻,我们需要的内容也都标注出来了,那么进入read.js文件中,一步到位开始撸了
// read.js文件
// request-promise是让request支持了promise的语法,可以说是request的小弟
const rp = require('request-promise');
// 将抓取页面的html代码转为DOM,可以称之为是node版的jq
const cheerio = require('cheerio');
// 这个是为了在调试时查看日志
const debug = require('debug')('movie:read');
// 读取页面的方法,重点来了
const read = async (url) => {
debug('开始读取最近上映的电影');
const opts = {
url, // 目标页面
transform: body => {
// body为目标页面抓取到的html代码
// 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构
return cheerio.load(body);
}
};
return rp(opts).then($ => {
let result = []; // 结果数组
// 遍历这些热映电影的li
$('#screening li.ui-slide-item').each((index, item) => {
let ele = $(item);
let name = ele.data('title');
let score = ele.data('rate') || '暂无评分';
let href = ele.find('.poster a').attr('href');
let image = ele.find('img').attr('src');
// 影片id可以从影片href中获取到
let id = href && href.match(/(\d+)/)[1];
// 为了防止豆瓣防盗链导致裂图,换成webp格式加载图片
image = image && image.replace(/jpg$/, 'webp');
if (!name || !image || !href) {
return;
}
result.push({
name,
score,
href,
image,
id
});
debug(`正在读取电影:${name}`);
});
// 返回结果数组
return result;
});
};
// 导出方法
module.exports = read;
复制代码
代码写完了,回味一下都做了什么事情吧
- 通过request抓取了html代码
- cheerio将html转成了dom
- 将需要的内容存在数组(名称|评分|地址|图片|id)
- 返回结果数组并导出read方法
数据入库
这里我们通过mysql来建立数据库存储数据,不太了解的也没有关系,先跟我一步一步做下去。我们先安装XAMPP和Navicat可视化数据库管理工具,安装完毕后按照我下面的来操作即可
XAMPP启动mysql
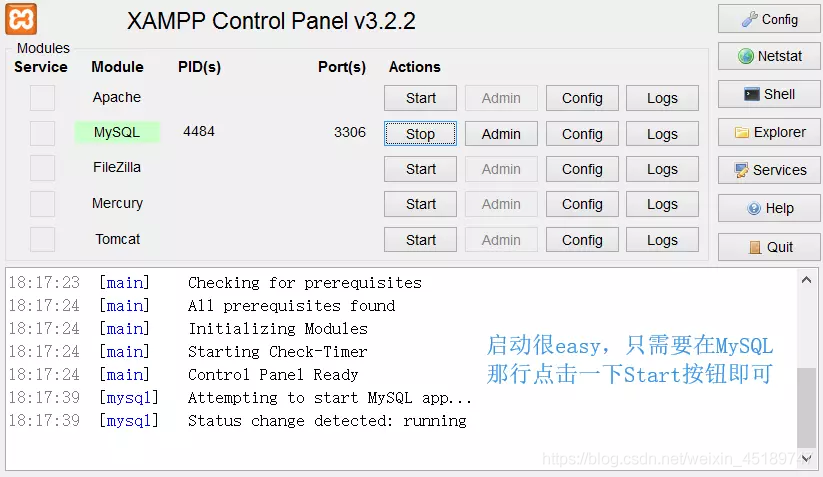
Navicat连接数据库及建表
只言片语可能都不及有图有真相的实际,这块就先看看图吧
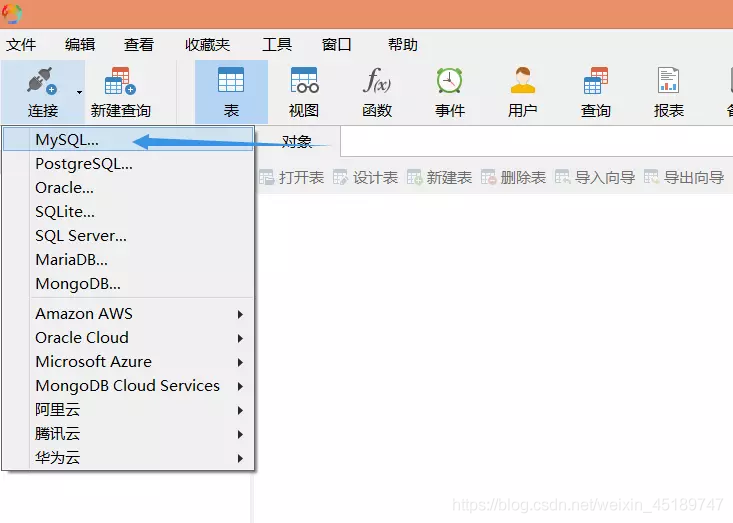
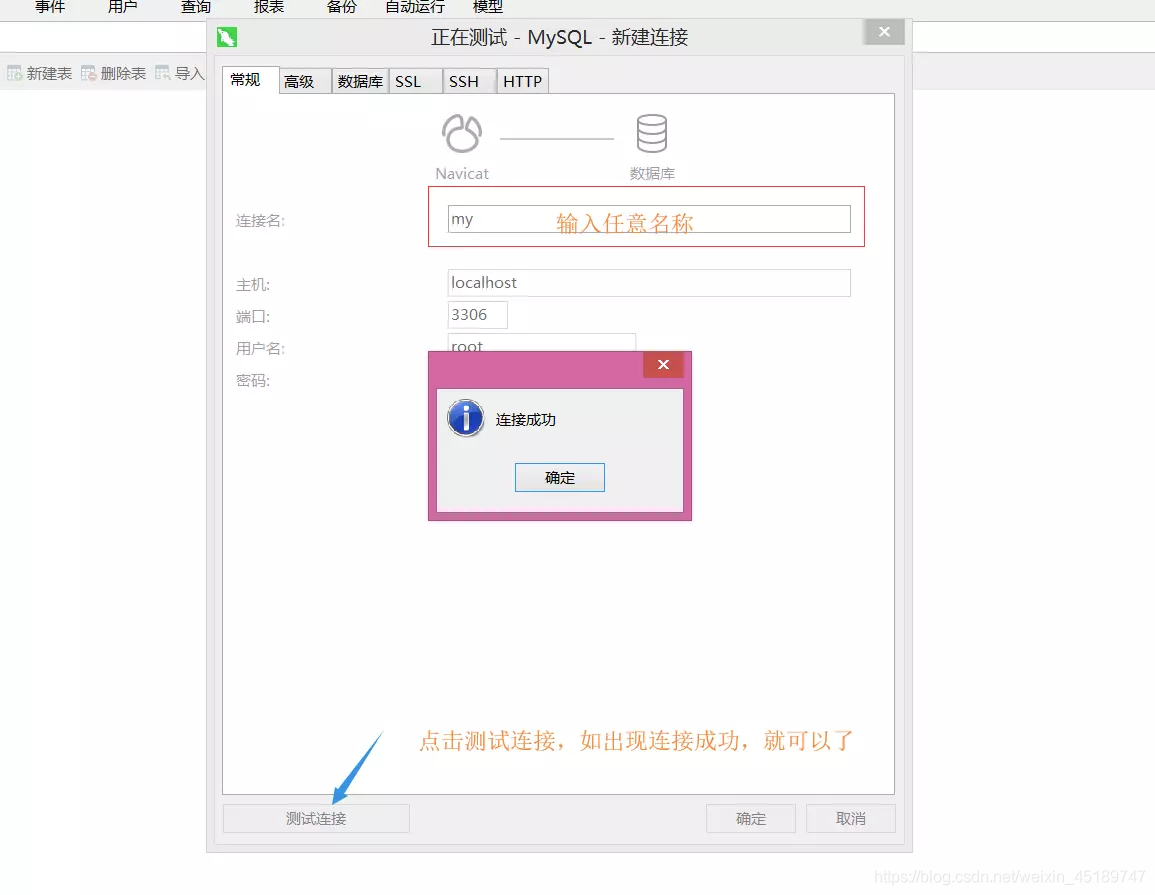
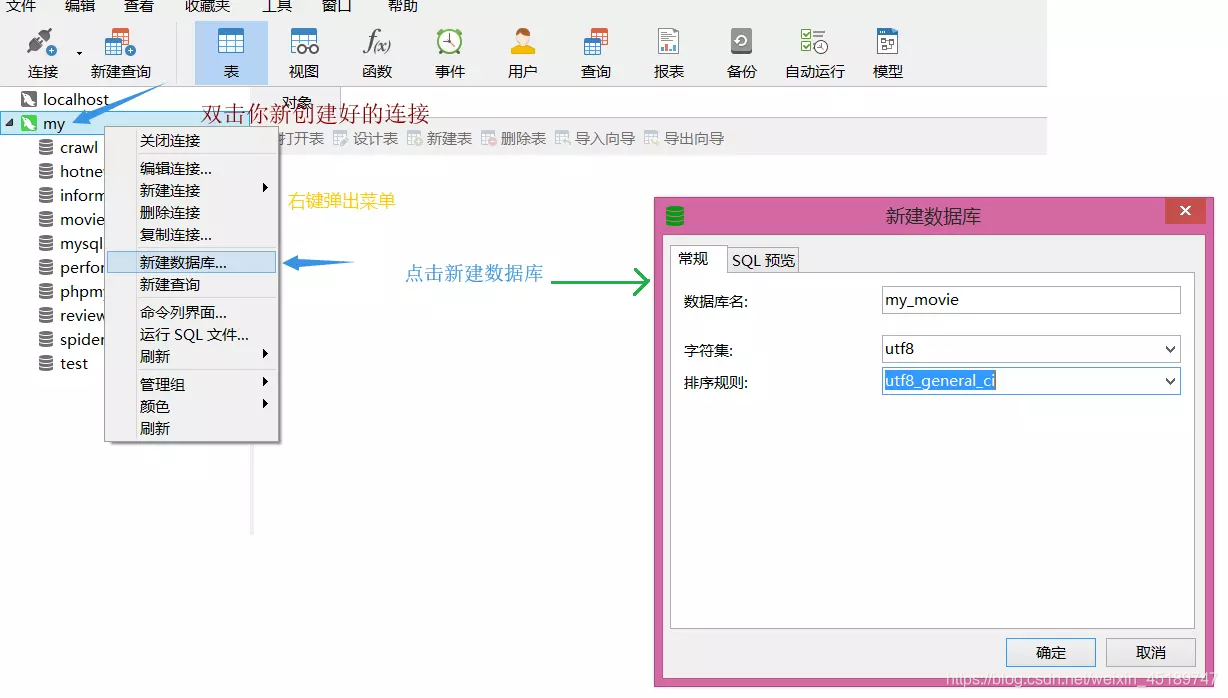
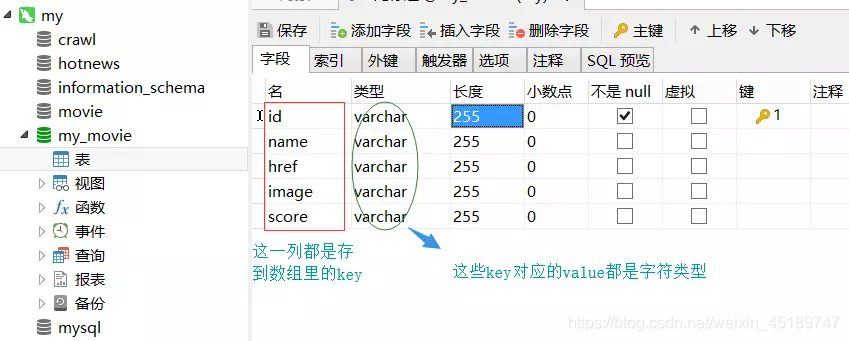
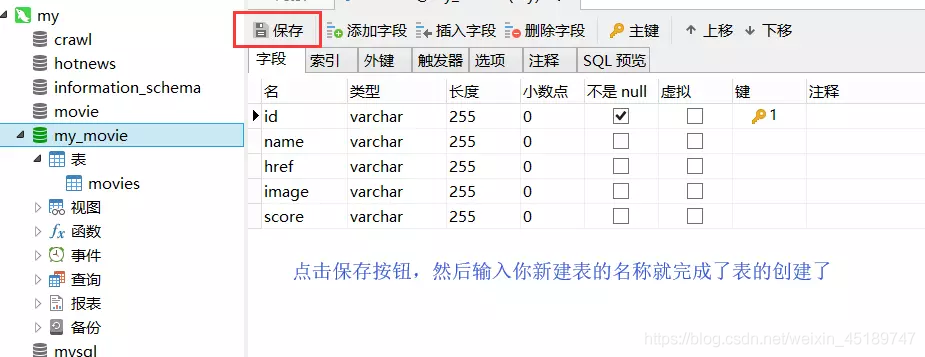
好了读图的时代,到这里就暂告一段落了。消耗了大家不少流量,实在有愧。下面让我们回到撸代码的阶段吧
连接数据库
首先,我们需要在src目录下创建一个sql文件,这里要和刚才创建的数据库同名,就叫它my_movie.sql了(当然目录结构已经创建过了)
然后,再回到db.js文件里,写入连接数据库的代码
// db.js
const mysql = require('mysql');
const bluebird = require('bluebird');
// 创建连接
const connection = mysql.createConnection({
host: 'localhost', // host
port: 3306, // 端口号默认3306
database: 'my_movie', // 对应的数据库
user: 'root',
password: ''
});
connection.connect(); // 连接数据库
// bluebird是为了方便支持promise语法化
// 然后直接把数据库的query查询语句导出方便之后调用
module.exports = bluebird.promisify(connection.query).bind(connection);
复制代码
上面代码就已经创建了连接Mysql数据库的操作了,接下来,不放缓脚步,直接把内容写进数据库吧
写入数据库
这时我们来看一下write.js这个文件,没错顾名思义就是用来写入数据库的,直接上代码
// write.js文件
// 从db.js那里导入query方法
const query = require('./db');
const debug = require('debug')('movie:write');
// 写入数据库的方法
const write = async (movies) => {
debug('开始写入电影');
// movies即为read.js读取出来的结果数组
for (let movie of movies) {
// 通过query方法去查询一下是不是已经在数据库里存过了
let oldMovie = await query('SELECT * FROM movies WHERE id=? LIMIT 1', [movie.id]);
// sql查询语句返回的是一个数组,如果不为空数组的话就表示有数据存过
// 直接就进行更新操作了
if (Array.isArray(oldMovie) && oldMovie.length) {
// 更新movies表里的数据
let old = oldMovie[0];
await query('UPDATE movies SET name=?,href=?,image=?,score=? WHERE id=?', [movie.name, movie.href, movie.image, movie.score, old.id]);
} else {
// 插入内容到movies表
await query('INSERT INTO movies(id,name,href,image,score) VALUES(?,?,?,?,?)', [movie.id, movie.name, movie.href, movie.image, movie.score]);
}
debug(`正在写入电影:${movie.name}`);
}
};
module.exports = write;
复制代码
上面写完可能会有点蒙圈,毕竟纯前端还是很少去写SQL语句的。不过不要方,待我先把上面的代码梳理之后再简单介绍一下SQL语句部分啊
write.js里到底写了哪些?
- 引入query方法用来书写SQL语句
- 遍历读取到的结果数组
- 查询是否有数据存过
好了,上面也实现了写入数据库的方法,接下来趁热打铁,稍微讲一下SQL语句吧
SQL语句学习
?表示占位符 这里顺便简单的说一下SQL语句里会用到的语法,无处不在的增删改查
- 插入数据
语法:
INSERT INTO 表名(列名) VALUES(列名值)
栗子:
INSERT INTO tags(name,id,url) VALUES('爬虫',10,'https://news.so.com/hotnews')
解释:
向标签表(tags)里插入一条,姓名,id和访问地址分别为VALUES内对应的值
复制代码
- 更新数据
语法:
UPDATE 表名 SET 列名=更新值 WHERE 更新条件
栗子:
UPDATE articles SET title='你好,世界',content='世界没你想的那么糟!' WHERE id=1
解释:
更新id为1的文章,标题和内容都进行了修改
复制代码
- 删除数据
语法:
DELETE FROM 表名 WHERE 删除条件
栗子:
DELETE FROM tags WHERE id=11
解释:
从标签表(tags)里删除id为11的数据
复制代码
- 查询
语法:
SELECT 列名 FROM 表名 WHERE 查询条件 ORDER BY 排序列名
栗子:
SELECT name,title,content FROM tags WHERE id=8
解释:
查询id为8的标签表里对应信息
复制代码
到这里已经把读写的方法全写完了,想必大家看的也有些疲惫了。也是时候该检验一下成果了,不然都是在扯淡的状态
执行读写操作
现在就来到index.js中,开始检验一番吧
// index.js文件
const read = require('./read');
const write = require('./write');
const url = 'https://movie.douban.com'; // 目标页面
(async () => {
// 异步抓取目标页面
const movies = await read(url);
// 写入数据到数据库
await write(movies);
// 完毕后退出程序
process.exit();
})();
复制代码
完毕,执行一下看看是什么效果,直接上图
代码已经执行完了,接下来再回到Navicat那里,看看数据到底有没有写进去呢,还是用图说话吧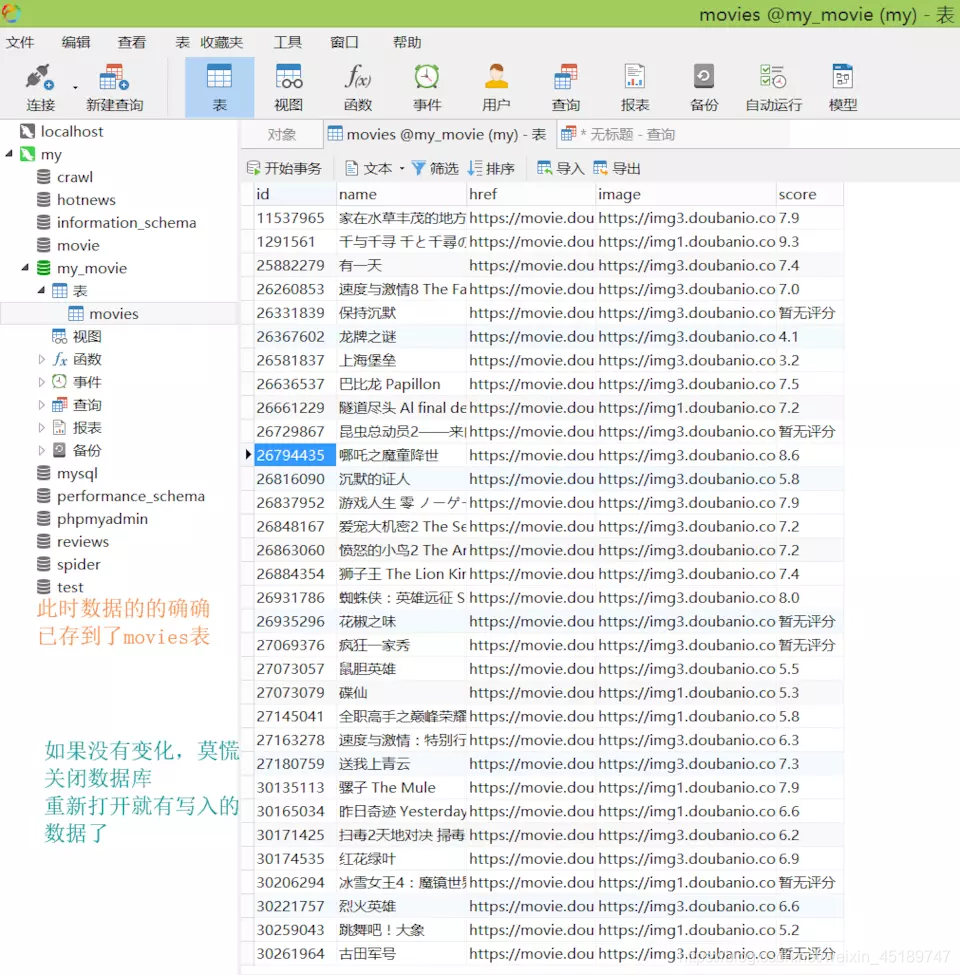
至此数据抓取及入库操作我们都搞定了,不过似乎还差点什么?
那就是我们需要写个页面来给展示出来了,由于抓取和写入数据都是在node环境下才允许。所以我们还要创建一个web服务用来展示页面的,坚持一下马上就OK了,加油
启动服务
由于要创建web服务了,所以开始写server.js的内容吧
server服务
// server.js文件
const express = require('express');
const path = require('path');
const query = require('../src/db');
const app = express();
// 设置模板引擎
app.set('view engine', 'html');
app.set('views', path.join(__dirname, 'views'));
app.engine('html', require('ejs').__express);
// 首页路由
app.get('/', async (req, res) => {
// 通过SQL查询语句拿到库里的movies表数据
const movies = await query('SELECT * FROM movies');
// 渲染首页模板并把movies数据传过去
res.render('index', { movies });
});
// 监听localhost:9000端口
app.listen(9000);
复制代码
写完了server服务了,最后再到index.html模板里看看吧,这可是最后的东西了,写完就全部大功告成了
渲染数据
// index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>热映的电影</title>
</head>
<body>
<div class="container">
<h2 class="caption">正在热映的电影</h2>
<ul class="list">
<% for(let i=0;i<movies.length;i++){
let movie = movies[i];
%>
<li>
<a href="<%=movie.href%>" target="_blank">
<img src="<%=movie.image%>" />
<p class="title"><%=movie.name%></p>
<p class="score">评分:<%=movie.score%></p>
</a>
</li>
<% } %>
</ul>
</div>
</body>
</html>
复制代码
通过模板引擎遍历movies数组,然后进行渲染就可以了
Now,看下最终的效果
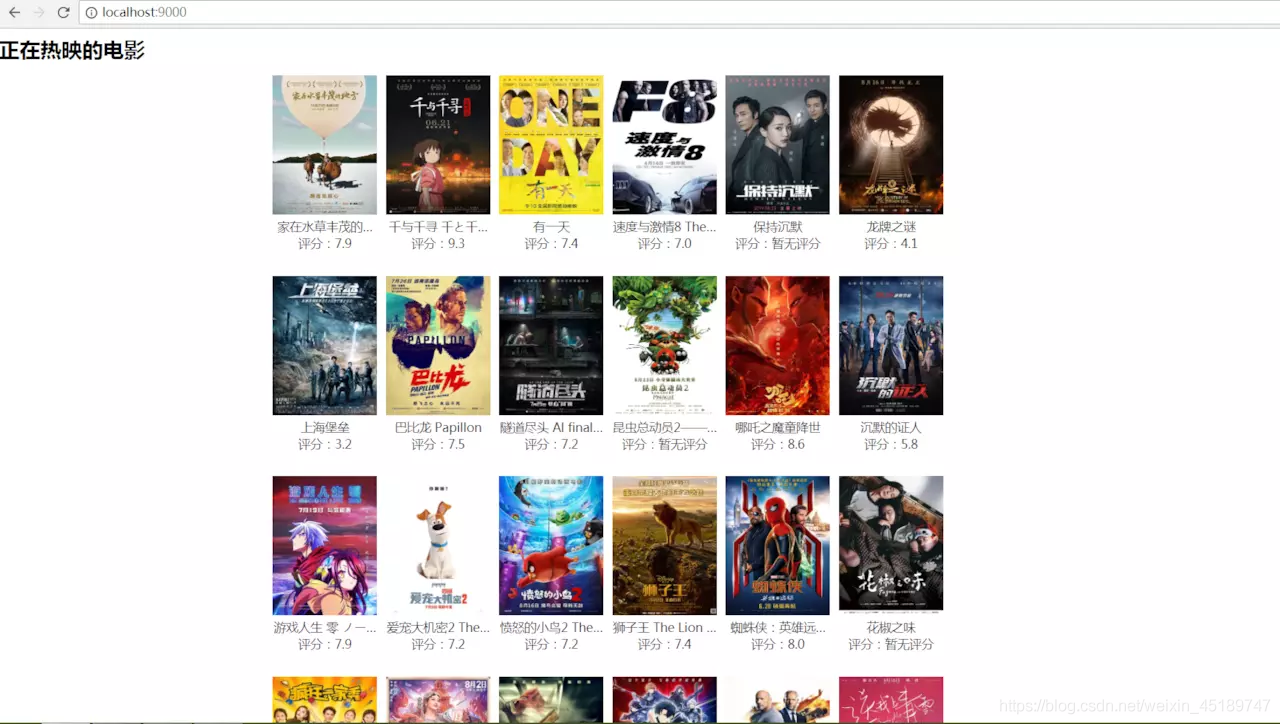
跟着一起走到了这里,就是缘分,很高兴经历了这么长的文章学习,大家应该会对爬虫的知识有了很好的认识了
这里顺便发一下代码,以方便大家参考敲敲敲
感谢大家的观看,886
服务推荐
- 蜻蜓代理
- 代理ip
- 微信域名检测
- 微信域名拦截检测
- 微信域名在线拦截检测工具
- 微信域名在线批量拦截检测工具
cs