CSDN爬虫(五)――CSDN用户(所有)爬取+常用爬虫正则整理
说明
- 开发环境:jdk1.7+myeclipse10.7+win74bit+mysql5.5+webmagic0.5.2+jsoup1.7.2
- 爬虫框架:webMagic
- 建议:建议首先阅读webMagic的文档,再查看此系列文章,便于理解,快速学习:http://webmagic.io/
- 开发所需jar下载(不包括数据库操作相关jar包):点我下载
- 该系列文章会省略webMagic文档已经讲解过的相关知识。
概述
- 我们会从CSDN个人中心出发,首先爬取一个用户的个人信息。然后根据该用户的好友关系去爬取好友信息。依次类推,爬取所用用户。
- 爬取CSDN所有用户是根据“粉丝、关注”去爬取“粉丝、关注”,必然会涉及到“死循环”。到后期肯定会出现大量“脏数据”(重复数据),就要考虑到过滤脏数据的问题。
- 虽然用webMagic框架爬虫会用到大量的正则表达式,并且爬虫类的正则在网上也很少能找到资料,但是也是比较固定。
CSDN用户(所有)爬取代码预览
package com.wgyscsf.spider;
import java.util.List;
import org.jsoup.select.Elements;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import com.wgyscsf.utils.MyStringUtils;
/**
* @author 高远</n>
* 编写日期 2016-9-24下午7:25:36</n>
* 邮箱 wgyscsf@163.com</n>
* 博客 http://blog.csdn.net/wgyscsf</n>
* TODO</n>
*/
public class CsdnMineSpider implements PageProcessor {
private final String TAG = CsdnMineSpider.class.getSimpleName();
private Site site = Site
.me()
.setDomain("my.csdn.net")
.setSleepTime(1000)
// 便于测试,休眠较长时间。
.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
public void process(Page page) {
// 列表页: 这里进行匹配,匹配出列表页进行相关处理。
if ((page.getUrl()).regex("http://my.csdn.net/\\w+").match()) {
// 获取最外层节点
// TODO:应该是get(1),不知道为什么
Elements mainElements = page.getHtml().getDocument()
.getElementsByTag("div").get(2).children();
// 个人资料
Elements profileElements = mainElements.get(0).getElementsByTag(
"div");
// 个人技能
Elements skillElements = mainElements.get(1)
.getElementsByTag("div");
// 关系模块:关注和被关注
Elements relationElements = mainElements.get(2).getElementsByTag(
"div");
// 获取用户id
String id_mine = MyStringUtils.getLastSlantContent(skillElements
.get(0).getElementsByTag("a").get(0).attr("href"));
// 开始获取个人资料
String headImg = profileElements.get(0)
.getElementsByClass("person-photo").get(0)
.getElementsByTag("img").attr("src");
String fansNums = profileElements.get(0)
.getElementsByClass("fans_num").get(0)
.getElementsByTag("b").get(0).text();
String nickname = profileElements.get(0)
.getElementsByClass("person-nick-name").get(0)
.getElementsByTag("span").get(0).text();
// 这里只能精确到个人资料,没法继续分,因为好多用户该栏目只填写部分内容
String personDetail = profileElements.get(0)
.getElementsByClass("person-detail").get(0).text();
// 开始组织个人资料,保存数据操作
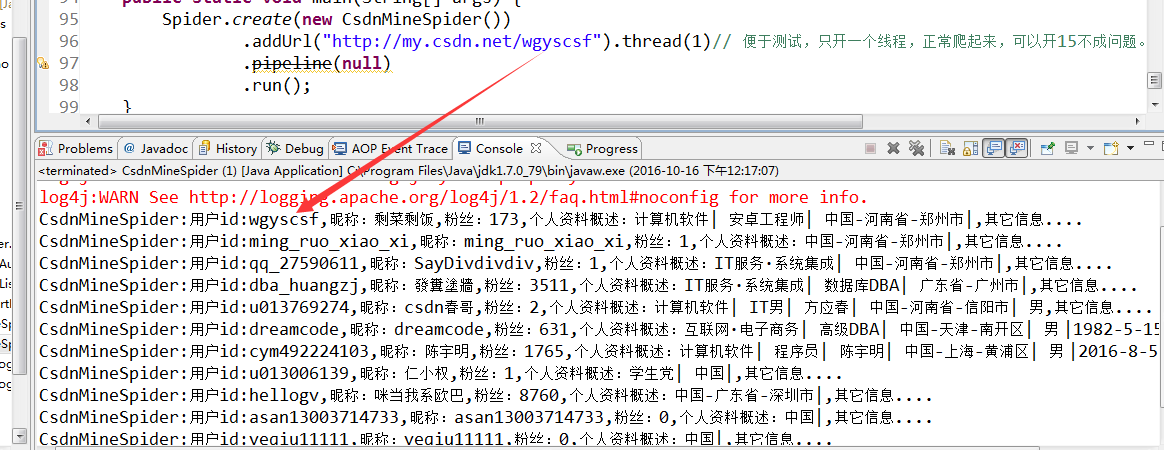
System.out.println(TAG + ":用户id:" + id_mine + ",昵称:" + nickname
+ ",粉丝:" + fansNums + ",个人资料概述:"
+ personDetail + ",其它信息....");
// 当前爬取页面信息爬取结束,将当前页面设置为“跳过”,下次再加入爬虫队列,直接过滤,提高爬取效率。
page.setSkip(true);
// 测试,看是否再被爬取。
page.addTargetRequest("http://my.csdn.net/wgyscsf");
/*
* 核心部分,从关系模块出发,去遍历所有相关用户!
*/
// 开始获取关注与被关注以及访客的个人中心。同时加入爬虫队列。
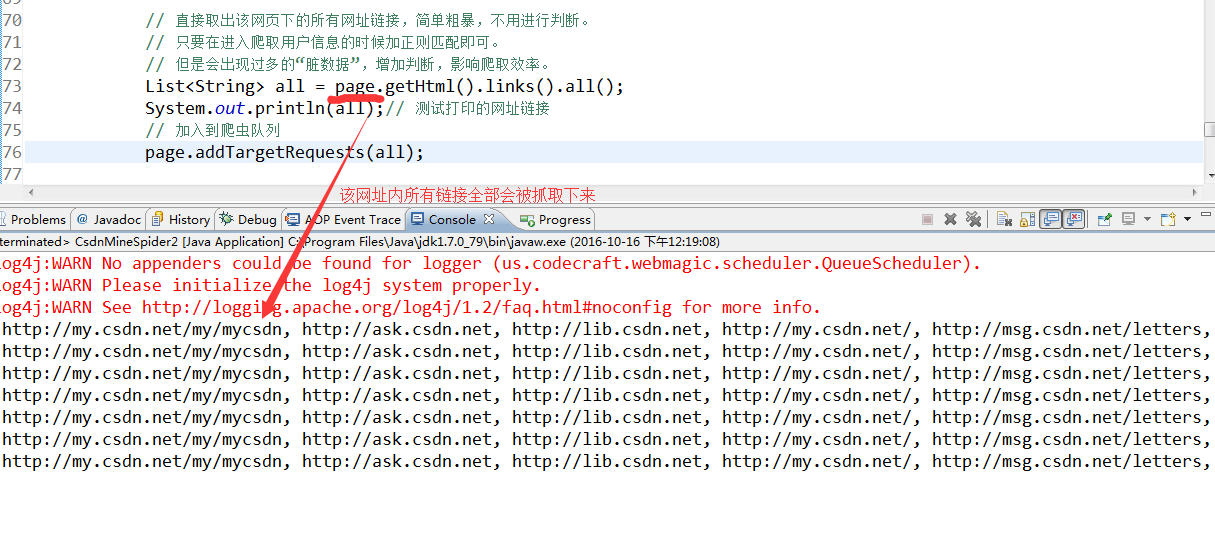
String html = relationElements.get(0).html();
List<String> all = new Html(html)
.xpath("//div[@class=\"mod_relations\"]").links().all();
// 加入到爬虫队列
page.addTargetRequests(all);
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new CsdnMineSpider())
.addUrl("http://my.csdn.net/wgyscsf").thread(1)// 便于测试,只开一个线程,正常爬起来,可以开15不成问题。
.pipeline(null)
.run();
}
}
关键代码解释