写在前面:
这个专栏主要是分享一些python、Web自动化的相关知识。
需要你具备一定的python基础,参考教程:廖雪峰python教程
掌握红框中的内容即可!
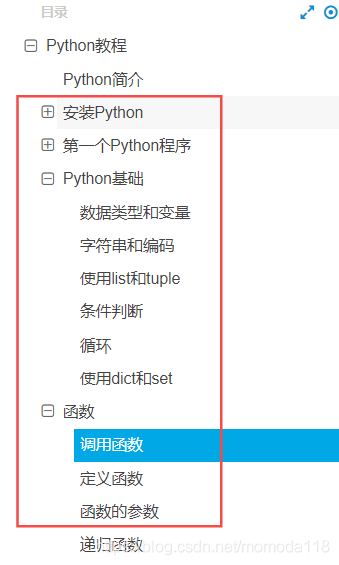
通过实战项目让你学会包括:python、selenium、测试报告、监听、特殊元素的定位方式的处理以及自动化框架的搭建,
最后更高效的企业级自动化测试方法(零代码,图形化Web自动化)的分享。
一、实现效果:
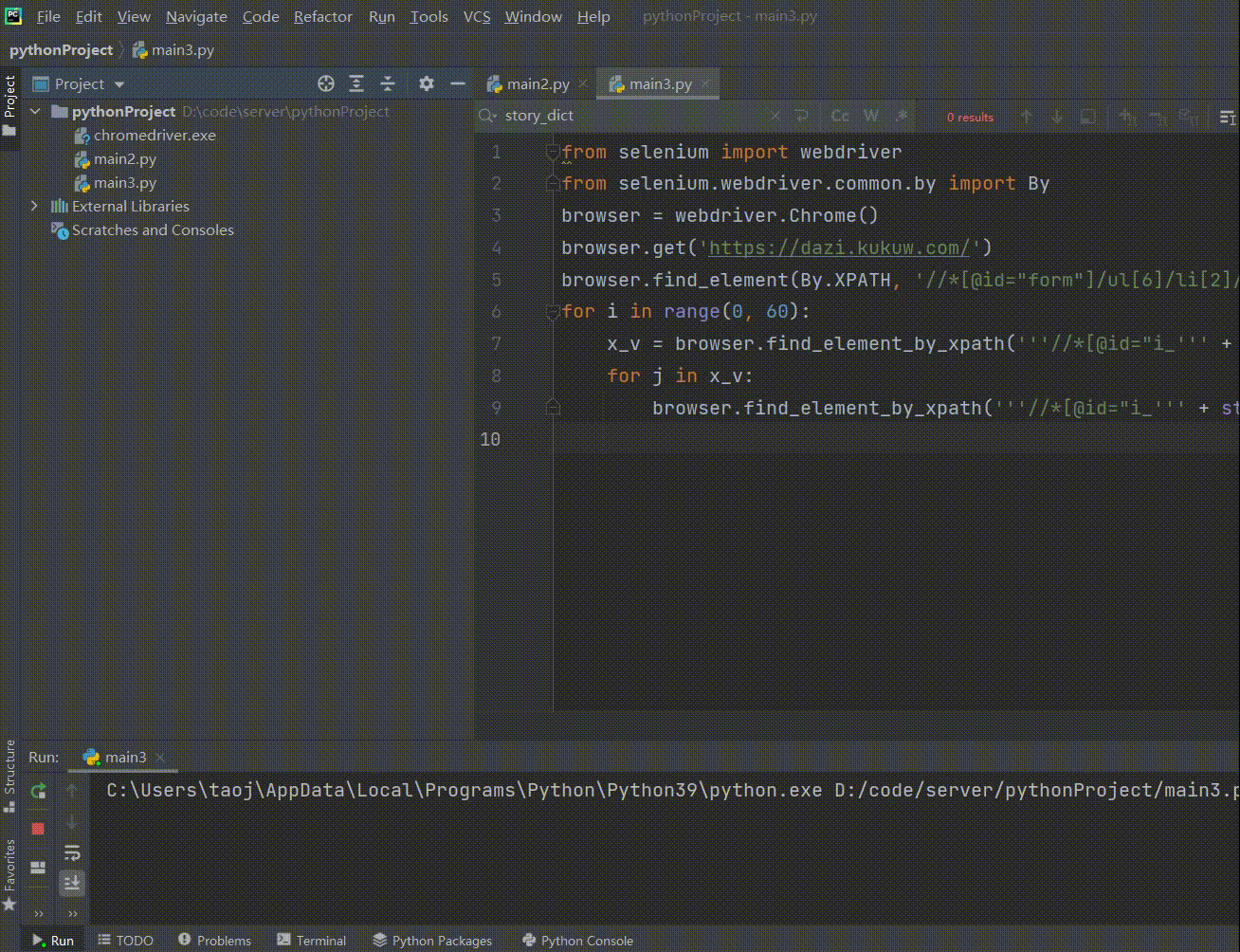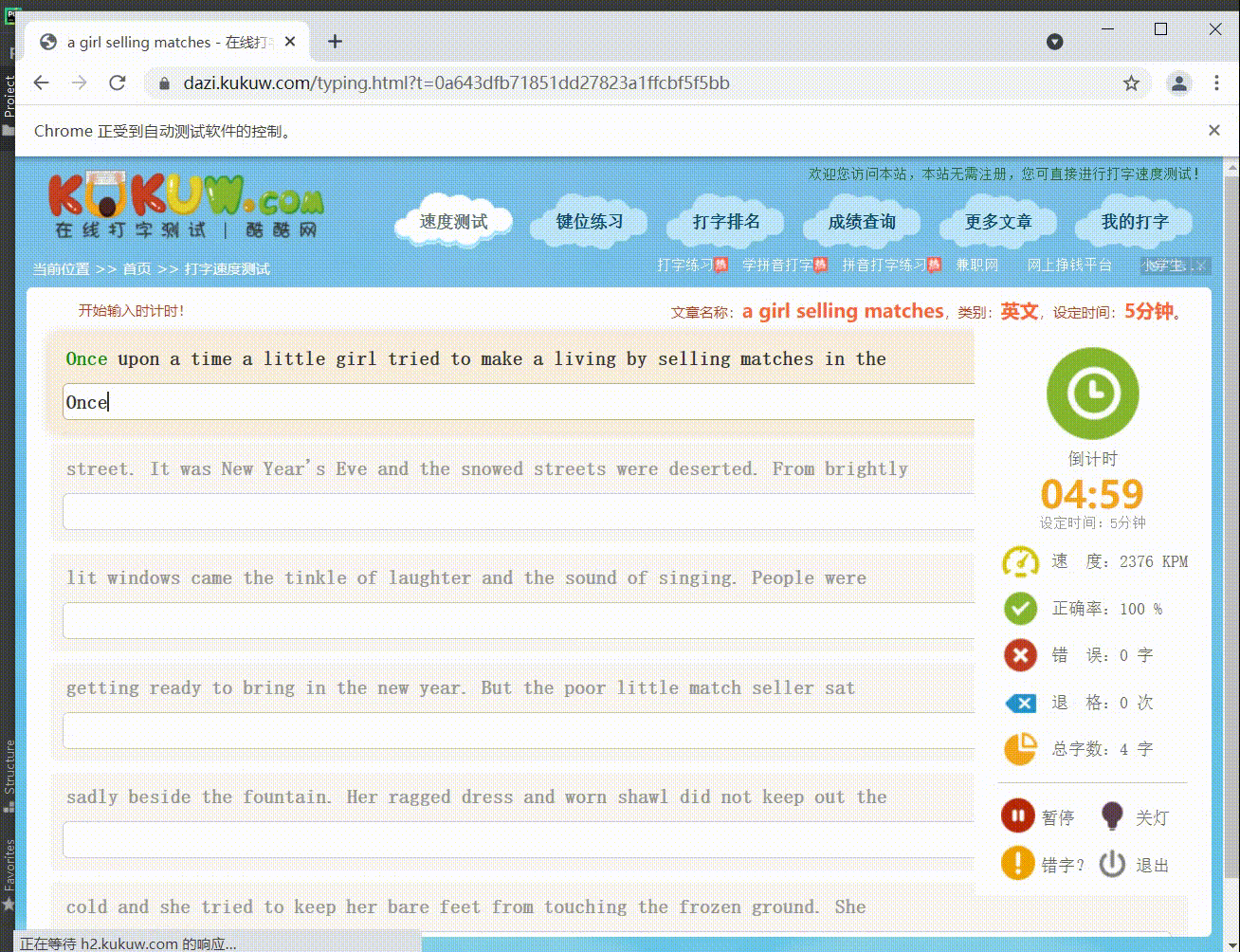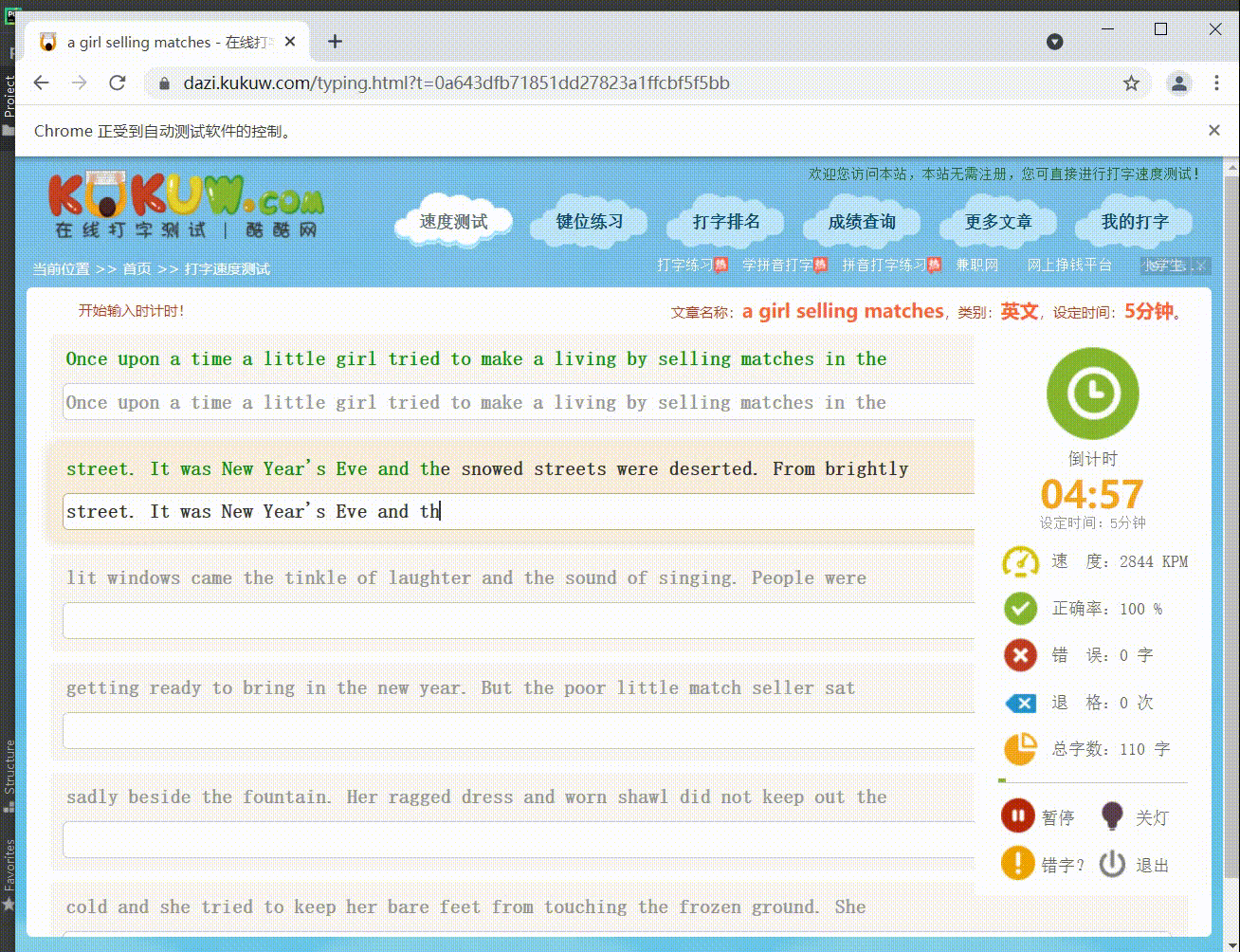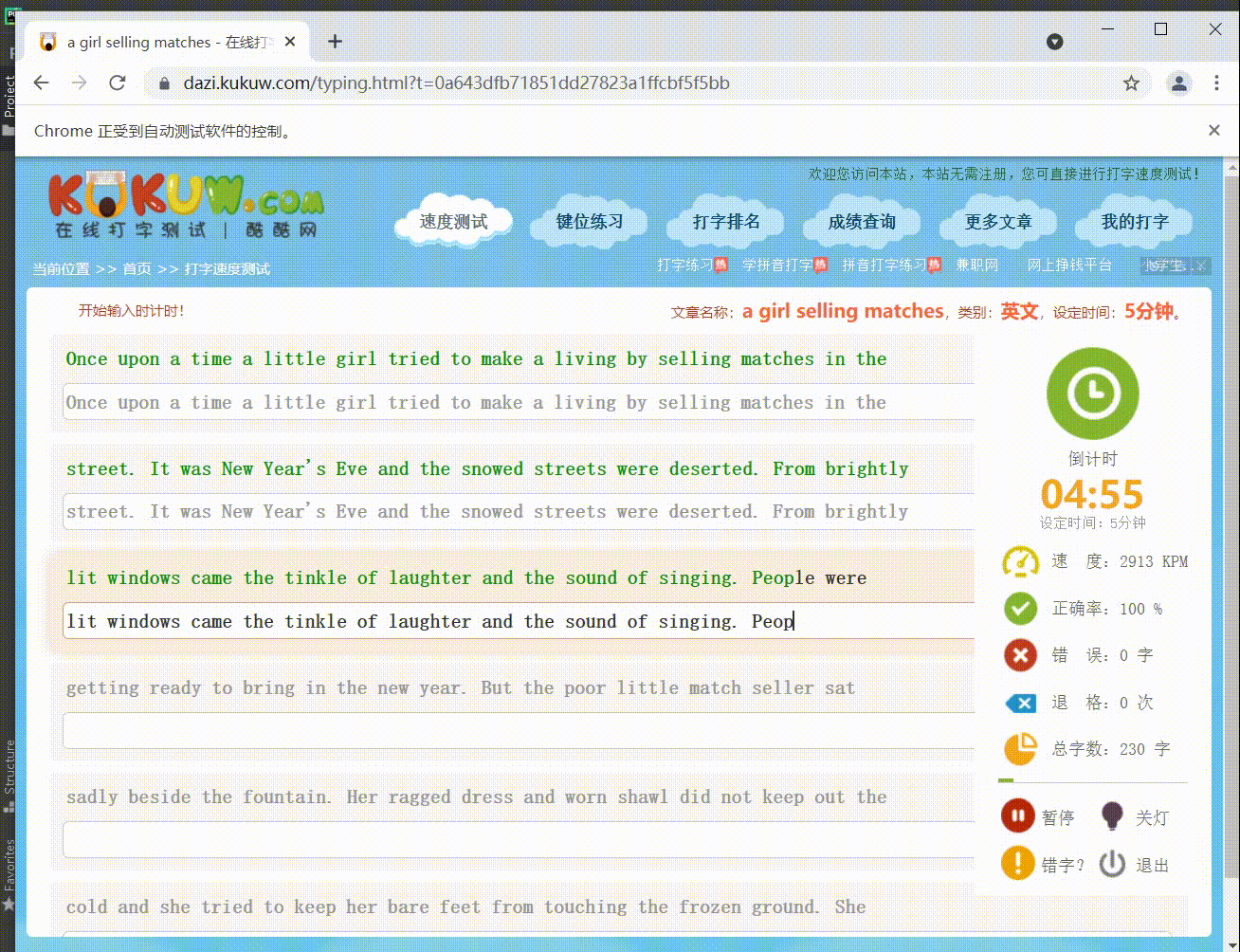
看着很厉害的样子,实际实现起来非常简单!!!
二、源码
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://dazi.kukuw.com/')
browser.find_element(By.XPATH, '//*[@id="form"]/ul[6]/li[2]/input').click()
for i in range(0, 60):
x_v = browser.find_element(By.XPATH, '''//*[@id="i_''' + str(i) + '''"]/div/span''').text + ' '
for j in x_v:
browser.find_element(By.XPATH, '''//*[@id="i_''' + str(i) + '''"]/input[2]''').send_keys(j)
三、具体分析
browser = webdriver.Chrome()
1.第一行代码用于启动chrome浏览器,它可以携带很多参数,但我们常用的就两种:
一种是chromedriver的路径:
browser = webdriver.Chrome("E:\ChromDriver\chromedriver.exe")
第二种是携带一些启动设置,比如:隐藏浏览器界面启动chrome
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
当然,如果你想启动其他浏览器的话,例如:火狐,代码就需要这样写:
browser = webdriver.Firefox()
2.第二行代码的意思就是访问一个网址:
browser.get('https://dazi.kukuw.com/')
3.第三行代码:通过xpath定位方式定位一个元素,对它执行点击操作:
browser.find_element(By.XPATH, '//*[@id="form"]/ul[6]/li[2]/input').click()
定位方式除了Xpath还有其他的,比如:id、css选择器、name等。
但我们不需要过于的花时间去学习它们,了解就够了,因为在工作中没谁会关心你用什么定位。
那如何进行快捷简便的定位呢?
我们可以利用工具:
chrome浏览器自带了定位方式的获取工具,按下F12(右键鼠标,点击"检查")也可以,按图中的步骤操作就可以获取到需要操作的元素地址
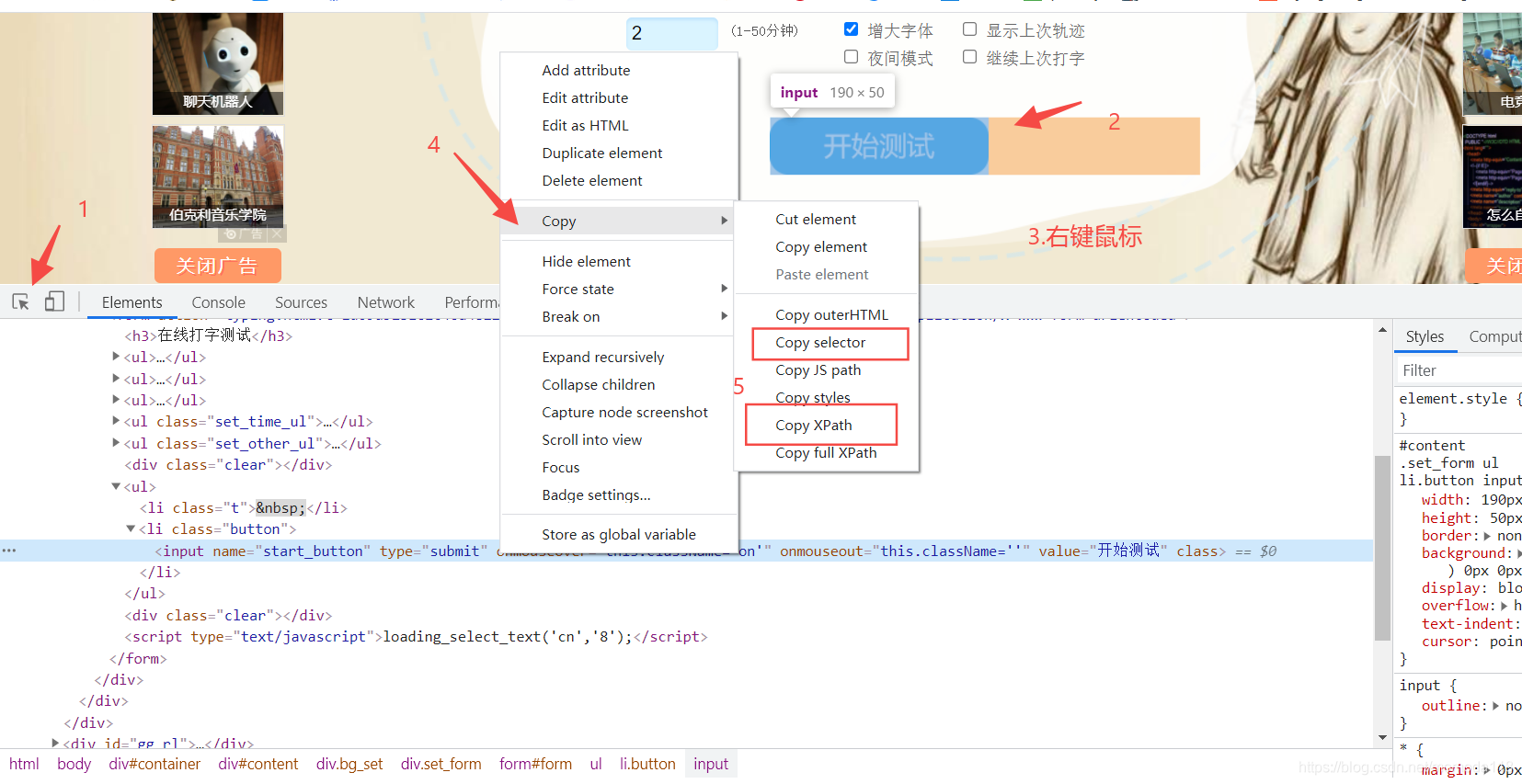
当然会出现工具获取的定位地址,代码跑起来还是定位的不到的情况,
这个就需要自己根据实际情况切换定位方式或者自写xpath代码才能解决这个问题了,庆幸的是,这类的元素比较少。我在工作中遇到的就是页面搜索栏的下拉菜单有多个,但它们是继承的同一个组件,导致xpath定位只能定位到第一个被打开的下拉菜单,这个时候就需要自己写xpath定位元素来解决这个问题。
当时写的代码:xpath('//div[contains(@class,"a") and contains(@class,"b")]') //它会取class同时有a和b的元素
selenium对元素的操作有很多种:包括图中使用的click(点击)、send_keys()输入内容、clear(清空内容)等。
这些也不需要刻意的去记,写多了自然就熟悉了
4.下面代码块的意思:循环遍历,获取第1行需要打字的内容,然后再循环遍历需要打字的内容,一个个的打出来
for i in range(0, 60):
x_v = browser.find_element(By.XPATH, '''//*[@id="i_''' + str(i) + '''"]/div/span''').text + ' '
for j in x_v:
browser.find_element(By.XPATH, '''//*[@id="i_''' + str(i) + '''"]/input[2]''').send_keys(j)
通过chrome的定位工具可以获取到要输入元素的地址
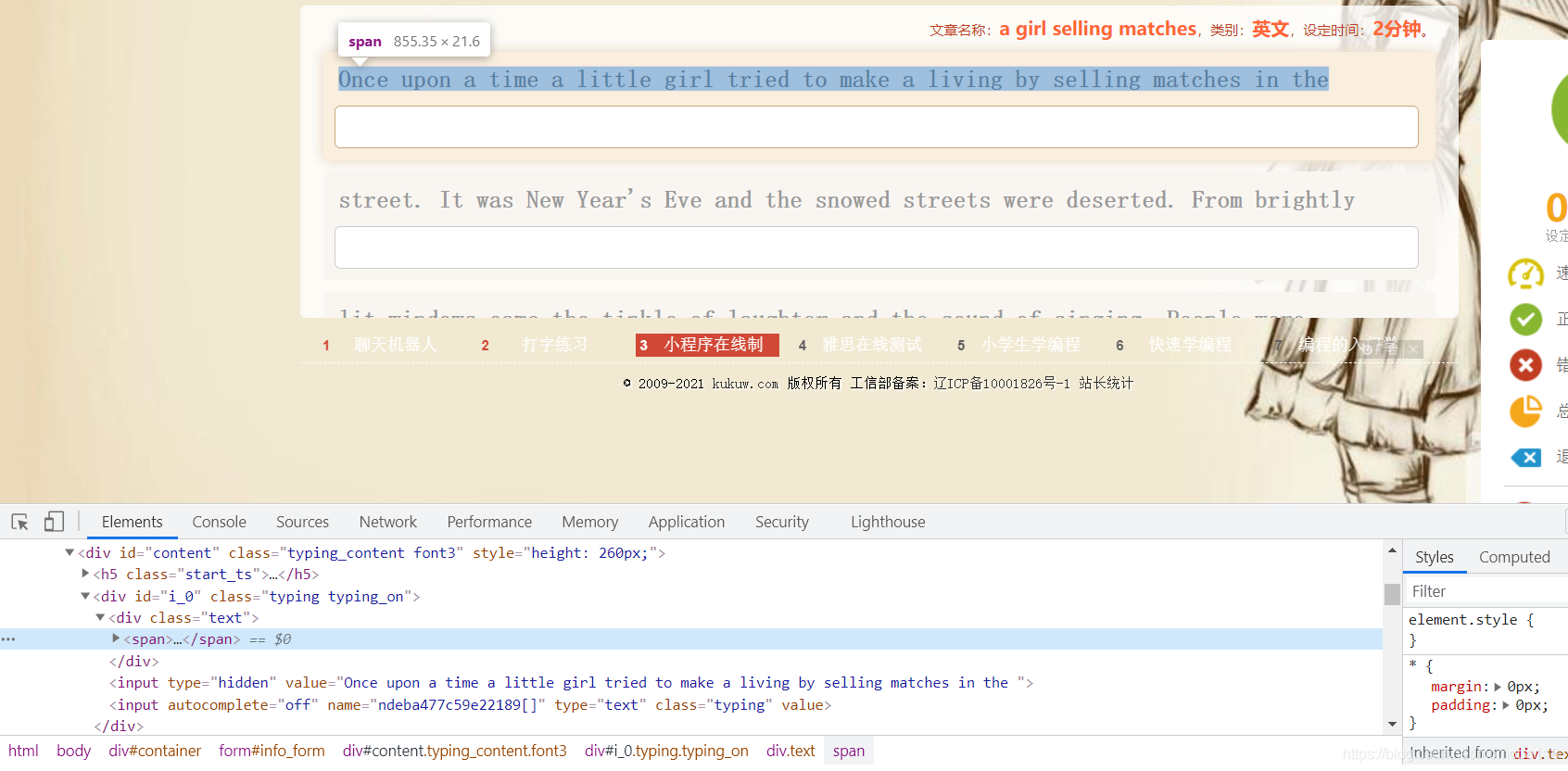
第一行元素地址:
//*[@id="i_0"]/div/span
第二行元素地址:
//*[@id="i_1"]/div/span
第三行元素地址:
//*[@id="i_2"]/div/span
发现了每增加一行,数字会+1,这就找到规律了!
所以就可以写一个循环来获取每行的需打字内容的数据
for i in range(0, 60):
x_v = browser.find_element(By.XPATH, '''//*[@id="i_''' + str(i) + '''"]/div/span''').text + ' '
print('第%d行数据:' % i, x_v)
-------------------------输出信息------------------------------
第0行数据: Once upon a time a little girl tried to make a living by selling matches in the
第1行数据: street. It was New Year's Eve and the snowed streets were deserted. From brightly
第2行数据: lit windows came the tinkle of laughter and the sound of singing. People were
第3行数据: getting ready to bring in the new year. But the poor little match seller sat
第4行数据: sadly beside the fountain. Her ragged dress and worn shawl did not keep out the
第5行数据: cold and she tried to keep her bare feet from touching the frozen ground. She
这样的话,我们只需要在获取到每行数据的时候,进行send_keys就行了
for j in x_v:
browser.find_element(By.XPATH, '''//*[@id="i_''' + str(i) + '''"]/input[2]''').send_keys(j)
这样就实现了自动打字的功能!
四、被检测到作弊了
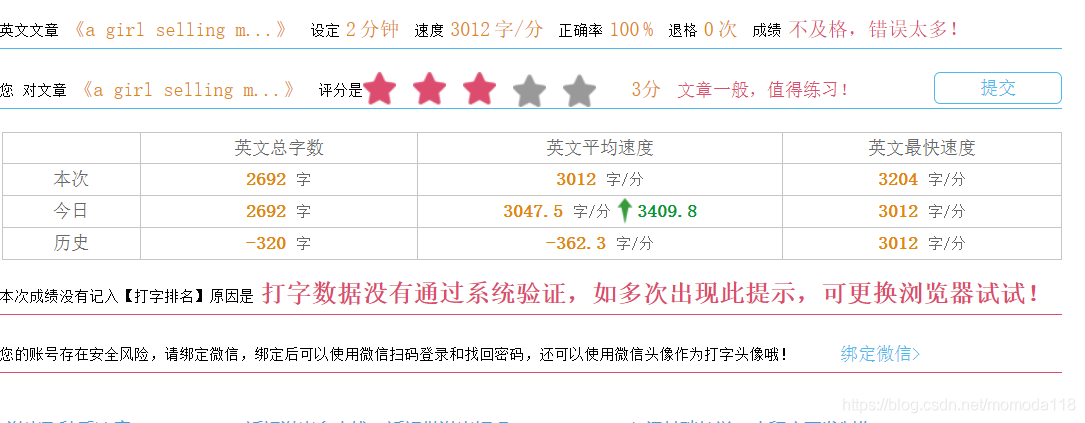
下一遍文章会讲解如何过检测以及python方法的的封装,让你的代码更可读
测试学习交流Q群:814078962
cs