Scrapy框架结构及工作原理
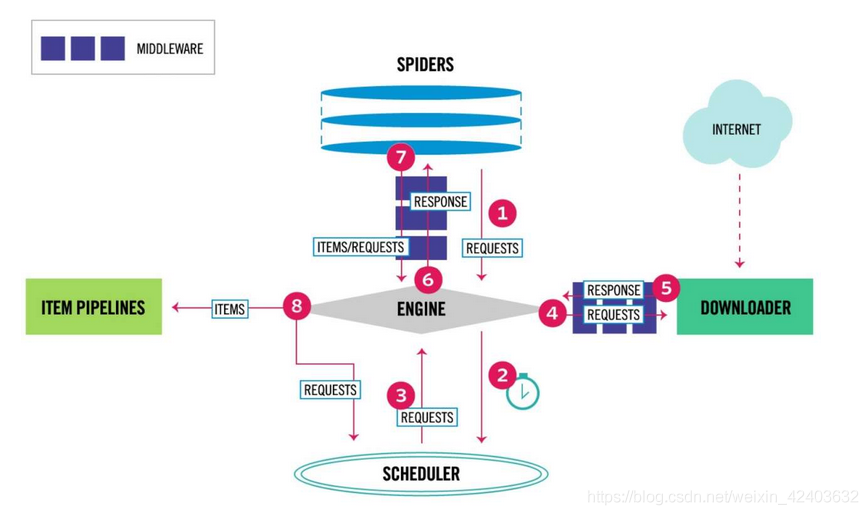
| 组件 | 描述 | 类型 |
|---|
| ENGINE | 引擎,框架的核心,其他所有组件在其控制下协同工作 | 内部组件 |
| SCHEDULER | 调度器,负责对SPIDER提交的下载请求进行调度 | 内部组件 |
| DOWNLOADER | 下载器,负责下载页面(发送HTTP请求/接收HTTP响应) | 内部组件 |
| SPIDER | 爬虫,负责提取页面中的数据,并产生对新页面的下载请求 | 用户实现 |
| MIDDLEWARE | 中间件,负责对Request对象和Response对象进行处理 | 可选组件 |
| ITEM PIPELINE | 数据管道,负责对爬取到的数据进行处理 | 可选组件 |
数据流
| 对象 | 描述 |
|---|
| REQUEST | Scrapy中的HTTP请求对象 |
| RESPONSE | Scrapy中的HTTP响应对象 |
| ITEM | 从页面中爬取的一项数据 |
Request和Response是HTTP协议中的术语,即HTTP请求和HTTP响应,Scrapy框架中定义了相应的Request和Response类,这里的Item代表Spider从页面中爬取的一项数据。最后,我们来说明以上几种对象在框架中的流动过程。
● 当SPIDER要爬取某URL地址的页面时,需使用该URL构造一个Request对象,提交给ENGINE(图中的1)。
● Request对象随后进入SCHEDULER按某种算法进行排队,之后的某个时刻SCHEDULER将其出队,送往DOWNLOADER(图中的2、3、4)。
● DOWNLOADER根据Request对象中的URL地址发送一次HTTP请求到网站服务器,之后用服务器返回的HTTP响应构造出一个Response对象,其中包含页面的HTML文本(图中的5)。
● Response对象最终会被递送给SPIDER的页面解析函数(构造Request对象时指定)进行处理,页面解析函数从页面中提取数据,封装成Item后提交给ENGINE, Item之后被送往ITEM PIPELINES进行处理,最终可能由EXPORTER(图中没有显示)以某种数据格式写入文件(csv, json);另一方面,页面解析函数还从页面中提取链接(URL),构造出新的Request对象提交给ENGINE(图中的6、7、8)。
理解了框架中的数据流,也就理解了Scrapy爬虫的工作原理。如果把框架中的组件比作人体的各个器官,Request和Response对象便是血液,Item则是代谢产物。
Request和Response对象
Request对象
Request对象用来描述一个HTTP请求
Request(url[,callback,method='GET',headers,body,cookies,meta,
encoding='utf-8',priority=0,dont_filter=False,errback])
| 参数 | 描述 |
|---|
| url (必选) | 请求页面的url地址,bytes或str类型,如’http://www.python.org/doc’。 |
| callback | 页面解析函数,Callable类型,Request对象请求的页面下载完成后,由该参数指定的页面解析函数被调用。如果未传递该参数,默认调用Spider的parse方法。 |
| method | HTTP请求的方法,默认为’GET’。 |
| headers | HTTP请求的头部字典,dict类型,例如{‘Accept’:‘text/html’, ‘User-Agent’:Mozilla/5.0’}。如果其中某项的值为None,就表示不发送该项HTTP头部,例如{‘Cookie’: None},禁止发送Cookie。 |
| body | HTTP请求的正文,bytes或str类型。 |
| cookies | Cookie信息字典,dict类型,例如{‘currency’:‘USD’, ‘country’: ‘UY’}。 |
| meta | Request的元数据字典,dict类型,用于给框架中其他组件传递信息,比如中间件ItemPipeline。其他组件可以使用Request对象的meta属性访问该元数据字典(request.meta),也用于给响应处理函数传递信息,详见Response的meta属性。 |
| encoding | url和body参数的编码默认为’utf-8’。如果传入的url或body参数是str类型,就使用该参数进行编码。 |
| priority | 请求的优先级默认值为0,优先级高的请求优先下载。 |
| dont_filter | 默认情况下(dont_filter=False),对同一个url地址多次提交下载请求,后面的请求会被去重过滤器过滤(避免重复下载)。如果将该参数置为True,可以使请求避免被过滤,强制下载。例如,在多次爬取一个内容随时间而变化的页面时(每次使用相同的url),可以将该参数置为True。 |
| errback | 请求出现异常或者出现HTTP错误时(如404页面不存在)的回调函数。 |
虽然参数很多,但除了url参数外,其他都带有默认值。在构造Request对象时,通常我们只需传递一个url参数或再加一个callback参数,其他使用默认值即可
常用的属性:url、method、headers、body、meta、
Response对象
Response对象用来描述一个HTTP响应,Response只是一个基类,根据响应内容的不同有如下子类:
● TextResponse
● HtmlResponse
● XmlResponse
| 属性/方法 | 描述 |
|---|
| url | HTTP响应的url地址,str类型。 |
| status | HTTP响应的状态码,int类型,例如200, 404。 |
| headers | HTTP响应的头部,类字典类型,可以调用get或getlist方法对其进行访问 |
| body | HTTP响应正文,bytes类型。 |
| text | 文本形式的HTTP响应正文,str类型,它是由response.body使用response.encoding解码得到的 |
| encoding | HTTP响应正文的编码,它的值可能是从HTTP响应头部或正文中解析出来的。 |
| request | 产生该HTTP响应的Request对象。 |
| meta | 即response.request.meta,在构造Request对象时,可将要传递给响应处理函数的信息通过meta参数传入;响应处理函数处理响应时,通过response.meta将信息取出。 |
| selector | Selector对象用于在Response中提取数据 |
| xpath(query) | 使用XPath选择器在Response中提取数据,实际上它是response.selector.xpath方法的快捷方式 |
| css(query) | 使用CSS选择器在Response中提取数据,实际上它是response.selector.css方法的快捷方式 |
| urljoin(url) | 用于构造绝对url。当传入的url参数是一个相对地址时,根据response.url计算出相应的绝对url |
常用:xpath(query)、css(query)、urljoin(url)
Spider开发流程
import scrapy
class BookSpiderSpider(scrapy.Spider):
name = 'book_spider'
start_urls = ['http://books.toscrape.com//']
def parse(self, response):
for book in response.css('article.product_pod'):
name=book.xpath('./h3/a/@title').extract_first()
price=book.css('p.price_color::text').extract_first()
yield {
'name':name,
'price':price,
}
next_url=response.css('ul.pager li.next a::attr(href)').extract_first()
if next_url:
next_url=response.urljoin(next_url)
yield scrapy.Request(next_url,callback=self.parse)
实现一个Spider只需要完成下面4个步骤:
01 继承scrapy.Spider
02 为Spider取名
03 设定起始爬取点
04 实现页面解析函数
继承scrapy.Spider
import scrapy
class BookSpiderSpider(scrapy.Spider):
为Spider命名
class BookSpiderSpider(scrapy.Spider):
name = 'book_spider'
设定起始爬取点
class BookSpiderSpider(scrapy.Spider):
name = 'book_spider'
start_urls = ['http://books.toscrape.com//']
start_urls通常被实现成一个列表,其中放入所有起始爬取点的url(例子中只有一个起始点)。
实现页面解析函数
页面解析函数也就是构造Request对象时通过callback参数指定的回调函数(或默认的parse方法)。页面解析函数是实现Spider中最核心的部分,它需要完成以下两项工作:
● 使用选择器提取页面中的数据,将数据封装后(Item或字典)提交给Scrapy引擎。
● 使用选择器或LinkExtractor提取页面中的链接,用其构造新的Request对象并提交给Scrapy引擎(下载链接页面)。
一个页面中可能包含多项数据以及多个链接,因此页面解析函数被要求返回一个可迭代对象(通常被实现成一个生成器函数),每次迭代返回一项数据(Item或字典)或一个Request对象。
参考资料:《精通Scrapy网络爬虫》刘硕 清华大学出版社
cs