import scrapy
from scrapy.linkextractors import LinkExtractor
from ..items import ExampleItem
class ExamplesSpider(scrapy.Spider):
name = 'examples'
allowed_domains = ['matplotlib.org']
start_urls = ['https://matplotlib.org/2.0.2/examples/index.html']
def parse(self, response):
le = LinkExtractor(restrict_css='div.toctree-wrapper.compound', deny='/index.html$')
print(len(le.extract_links(response)))
for link in le.extract_links(response):
yield scrapy.Request(link.url, callback=self.parse_example)
def parse_example(self, response):
href = response.css('a.reference.external::attr(href)').extract_first()
url = response.urljoin(href)
example = ExampleItem()
example['file_urls'] = [url]
return example
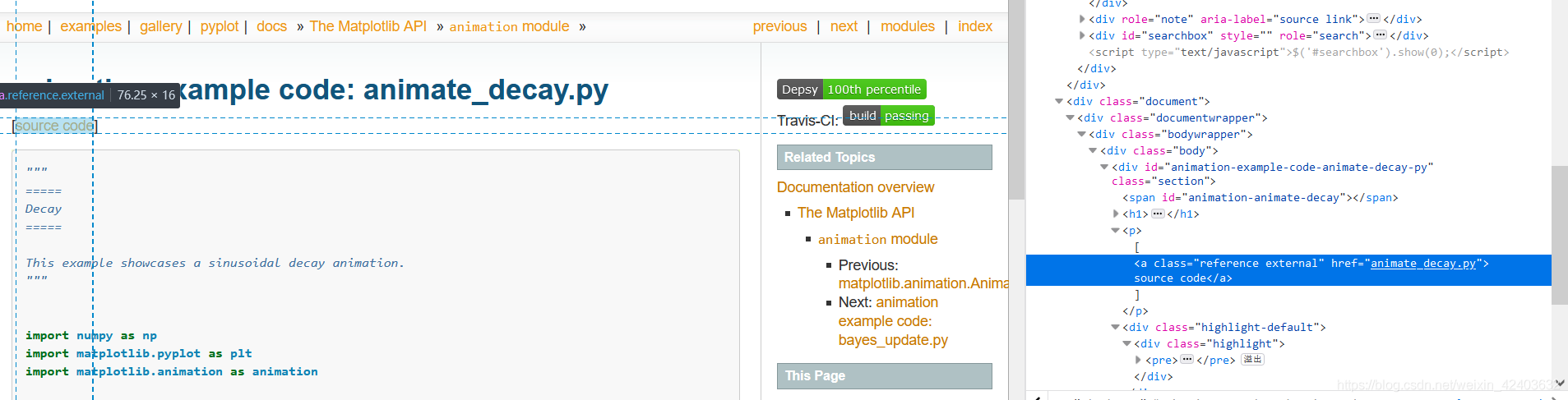
parse方法是例子列表页面的解析函数,在该方法中提取每个例子页面的链接,用其构造Request对象并提交
parse_example方法为例子页面的解析函数
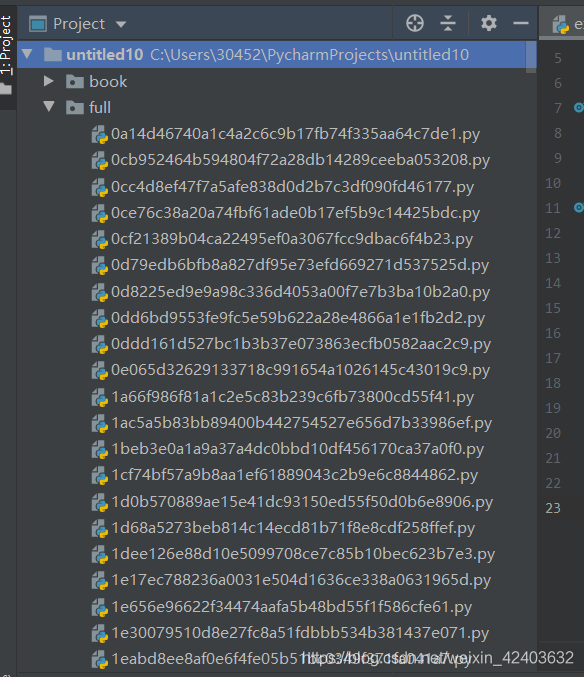
运行爬虫
查看目录
修改FilesPipeline为文件命名的规则
在pipelines.py
实现一个FilesPipeline的子类,覆写file_path方法来实现所期望的文件命名规则
from scrapy.pipelines.files import FilesPipeline
from urllib.parse import urlparse
from os.path import basename,dirname,join
class MyFilesPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None):
path=urlparse(request.url).path
return join(basename(dirname(path)),basename(path))
修改配置文件,使用MyFilesPipeline替代FilesPipeline:
ITEM_PIPELINES = {
'matplotlib_examples.pipelines.files.MyFilesPipeline': 1,
}
重新运行爬虫
cs
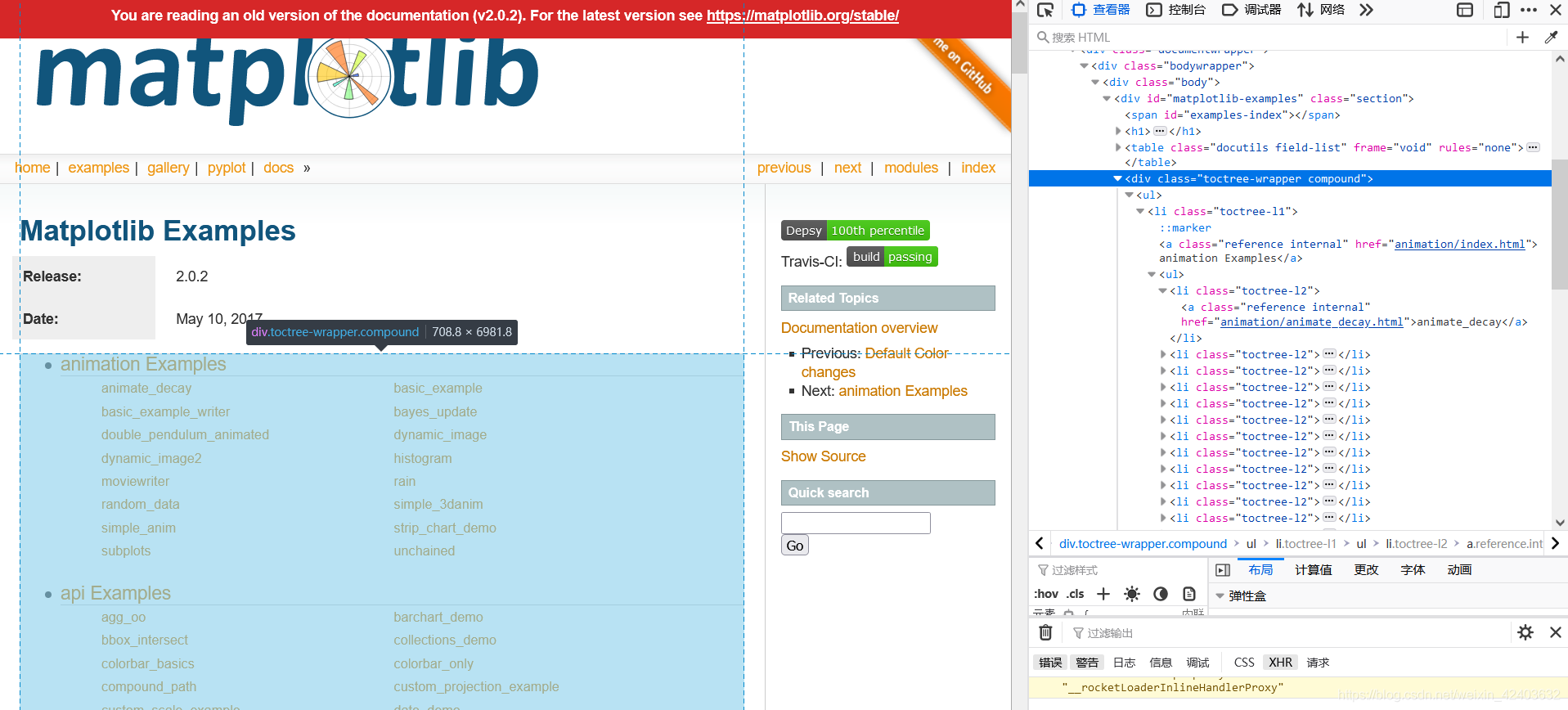 所有例子页面的链接都在
所有例子页面的链接都在