使用Item Pipeline处理数据
在Scrapy中,Item Pipeline是处理数据的组件,一个Item Pipeline就是一个包含特定接口的类,通常只负责一种功能的数据处理,在一个项目中可以同时启用多个ItemPipeline,它们按指定次序级联起来,形成一条数据处理流水线。
在创建一个Scrapy项目时,会自动生成一个pipelines.py文件,它用来放置用户自定义的Item Pipeline,在example项目的pipelines.py中实现PriceConverterPipeline,代码如下
功能:将爬取到的价格转换成人民币
class PriceConverterPipeline(object):
exchange_rate=8.5309
def process_item(self,item,spider):
price=float(item['price'][1:])*self.exchange_rate
item['price']='¥%.2f'%price
return item
一个Item Pipeline不需要继承特定基类,只需要实现某些特定方法,例如process_item、open_spider、close_spider。
一个Item Pipeline必须实现一个process_item(item, spider)方法,该方法用来处理每一项由Spider爬取到的数据,其中的两个参数:
** Item**爬取到的一项数据(Item或字典)。
Spider爬取此项数据的Spider对象。
除了必须实现的process_item方法外,还有3个比较常用的方法,可根据需求选择实现:
open_spider(self, spider)
Spider打开时(处理数据前)回调该方法,通常该方法用于在开始处理数据之前完成某些初始化工作,如连接数据库。
close_spider(self, spider)
Spider关闭时(处理数据后)回调该方法,通常该方法用于在处理完所有数据之后完成某些清理工作,如关闭数据库。
from_crawler(cls, crawler)
创建Item Pipeline对象时回调该类方法。通常,在该方法中通过crawler.settings读取配置,根据配置创建Item Pipeline对象。
启用Item Pipeline
在Scrapy中,Item Pipeline是可选的组件,想要启用某个(或某些)ItemPipeline,需要在配置文件settings.py中进行配置:
ITEM_PIPELINES={
'book.pipelines.PriceConverterPipeline':300,
}
注意book改为自己的项目名称
ITEM_PIPELINES是一个字典,我们把想要启用的Item Pipeline添加到这个字典中,其中每一项的键是每一个Item Pipeline类的导入路径,值是一个0~1000的数字,同时启用多个Item Pipeline时,Scrapy根据这些数值决定各Item Pipeline处理数据的先后次序,数值小的在前。
启用PriceConverterPipeline后,重新运行爬虫,并观察结果:
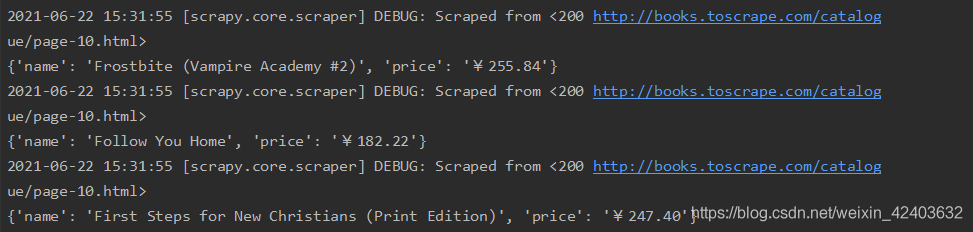 书价转换成了人民币价格。
书价转换成了人民币价格。
过滤重复数据
class DuplicatesPipeline(object):
def __init__(self):
self.book_set = set()
def process_item(self, item, spider):
name = item['name']
if name in self.book_set:
raise DropItem("Duplicate book found:%s" % item)
self.book_set.add(name)
return item
增加构造器方法,在其中初始化用于对书名去重的集合。
在process_item方法中,先取出item的name字段,检查书名是否已在集合book_set中,如果存在,就是重复数据,抛出DropItem异常,将item抛弃;否则,将item的name字段存入集合,返回item。
接下来测试DuplicatesPipeline。首先在不启用DuplicatesPipeline的情况下,运行爬虫,
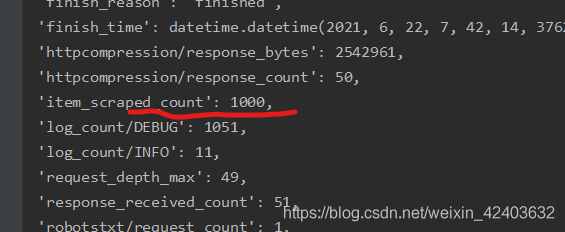
此时有1000本书。
然后在配置文件settings.py中启用DuplicatesPipeline:
ITEM_PIPELINES={
'book.pipelines.PriceConverterPipeline':300,
'book.pipelines.DuplicatesPipeline':350,
}
运行:
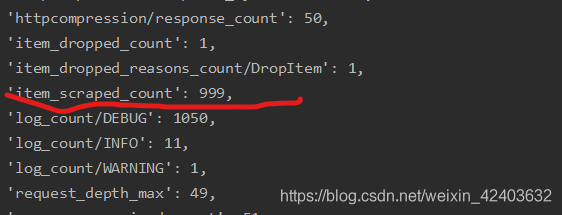
只有999本了,比之前少了1本,说明有两本书是同名的
参考资料:《精通Scrapy网络爬虫》刘硕 清华大学出版社
cs