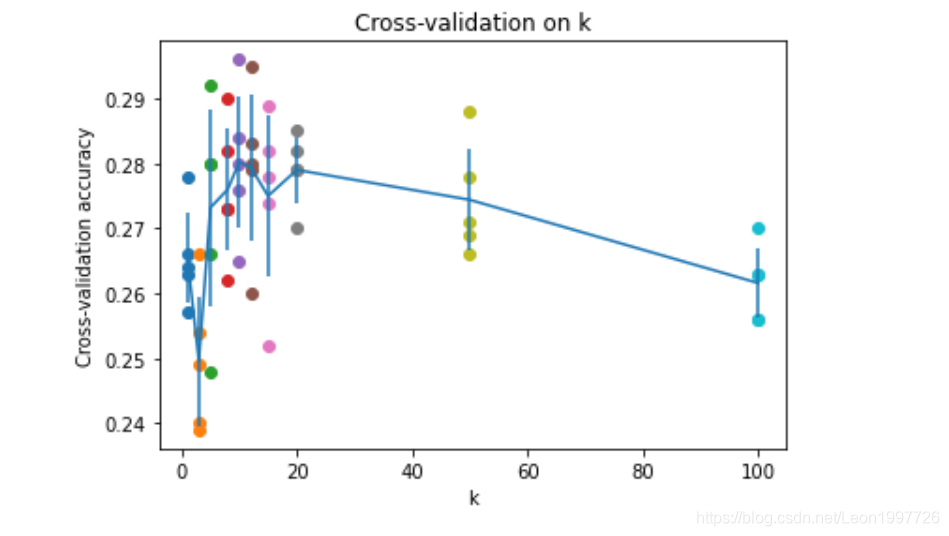
交叉验证结果(对于每个K值跑五次)
k = 1, accuracy = 0.263000
k = 1, accuracy = 0.257000
k = 1, accuracy = 0.264000
k = 1, accuracy = 0.278000
k = 1, accuracy = 0.266000
k = 3, accuracy = 0.239000
k = 3, accuracy = 0.249000
k = 3, accuracy = 0.240000
k = 3, accuracy = 0.266000
k = 3, accuracy = 0.254000
k = 5, accuracy = 0.248000
k = 5, accuracy = 0.266000
k = 5, accuracy = 0.280000
k = 5, accuracy = 0.292000
k = 5, accuracy = 0.280000
k = 8, accuracy = 0.262000
k = 8, accuracy = 0.282000
k = 8, accuracy = 0.273000
k = 8, accuracy = 0.290000
k = 8, accuracy = 0.273000
k = 10, accuracy = 0.265000
k = 10, accuracy = 0.296000
k = 10, accuracy = 0.276000
k = 10, accuracy = 0.284000
k = 10, accuracy = 0.280000
k = 12, accuracy = 0.260000
k = 12, accuracy = 0.295000
k = 12, accuracy = 0.279000
k = 12, accuracy = 0.283000
k = 12, accuracy = 0.280000
k = 15, accuracy = 0.252000
k = 15, accuracy = 0.289000
k = 15, accuracy = 0.278000
k = 15, accuracy = 0.282000
k = 15, accuracy = 0.274000
k = 20, accuracy = 0.270000
k = 20, accuracy = 0.279000
k = 20, accuracy = 0.279000
k = 20, accuracy = 0.282000
k = 20, accuracy = 0.285000
k = 50, accuracy = 0.271000
k = 50, accuracy = 0.288000
k = 50, accuracy = 0.278000
k = 50, accuracy = 0.269000
k = 50, accuracy = 0.266000
k = 100, accuracy = 0.256000
k = 100, accuracy = 0.270000
k = 100, accuracy = 0.263000
k = 100, accuracy = 0.256000
k = 100, accuracy = 0.263000
对交叉验证的结果可视化
Inline Question 3
Which of the following statements about?𝑘k-Nearest Neighbor (𝑘k-NN) are true in a classification setting, and for all?𝑘k? Select all that apply.
- The decision boundary of the k-NN classifier is linear.
- The training error of a 1-NN will always be lower than that of 5-NN.
- The test error of a 1-NN will always be lower than that of a 5-NN.
- The time needed to classify a test example with the k-NN classifier grows with the size of the training set.
- None of the above.
Y𝑜𝑢𝑟𝐴𝑛𝑠𝑤𝑒𝑟:YourAnswer:5
Y𝑜𝑢𝑟𝐸𝑥𝑝𝑙𝑎𝑛𝑎𝑡𝑖𝑜𝑛:YourExplanation:1.K-NN的决策边界不是线性的 2.两者的训练误差没有这种一定的大小关系 3.两者的测试误差没有这种一定的大小关系 4.训练集的大小不影响测试的时间花销,训练集是用来生成模型的
cs