目录
一、安装准备
1、下载地址
2、参考文档
3、ssh免密配置
4、zookeeper安装
5、集群角色分配
二、解压安装
三、环境变量配置
四、修改配置文件
1、检查磁盘空间
2、修改配置文件
五、初始化集群
1、启动zookeeper
2、在zookeeper中初始化元数据
3、启动zkfc
4、启动JournalNode
5、格式化NameNode
6、启动hdfs
7、同步备份NameNode
8、启动备份NameNode
9、查看集群状态
10、访问集群
六、集群高可用测试
1、停止Active状态的NameNode
2、查看standby状态的NameNode
3、重启启动停止的NameNode
4、查看两个NameNode状态
一、安装准备
1、下载地址
https://www.apache.org/dyn/closer.cgi/hadoop/common
2、参考文档
https://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-common/ClusterSetup.html
3、ssh免密配置
https://blog.csdn.net/qq262593421/article/details/105325593
4、zookeeper安装
https://blog.csdn.net/qq262593421/article/details/106955485
5、集群角色分配
| hadoop集群角色 | 集群节点 |
| NameNode | hadoop001、hadoop002 |
| DataNode | hadoop003、hadoop004、hadoop005 |
| JournalNode | hadoop003、hadoop004、hadoop005 |
| ResourceManager | hadoop001、hadoop002 |
| NodeManager | hadoop003、hadoop004、hadoop005 |
| DFSZKFailoverController | hadoop001、hadoop002 |
二、解压安装
解压文件
cd /usr/local/hadoop
tar zxpf hadoop-3.0.0.tar.gz
创建软链接
ln -s hadoop-3.0.0 hadoop
三、环境变量配置
编辑 /etc/profile?文件
vim /etc/profile
添加以下内容
export HADOOP_HOME=/usr/local/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
四、修改配置文件
1、检查磁盘空间
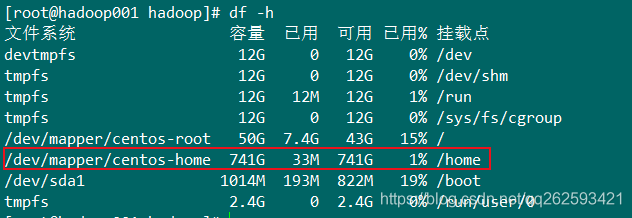
首先查看磁盘挂载空间,避免hadoop的数据放在挂载空间小的目录
df -h
磁盘一共800G,home目录占了741G,故以下配置目录都会以 /home开头?
2、修改配置文件
worker
hadoop003
hadoop004
hadoop005
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/cluster/hadoop/data/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>Size of read/write buffer used in SequenceFiles</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
<description>DFSZKFailoverController</description>
</property>
</configuration>
hadoop-env.sh
export HDFS_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx4g"
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/usr/java/jdk1.8
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/cluster/hadoop/data/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/cluster/hadoop/data/dn</value>
</property>
<!--
<property>
<name>dfs.data.dir</name>
<value>/home/cluster/hadoop/data/hdfs/data</value>
</property>
-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/cluster/hadoop/data/jn</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>hadoop001,hadoop002</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.hadoop001</name>
<value>hadoop001:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.hadoop001</name>
<value>hadoop001:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.hadoop002</name>
<value>hadoop002:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.hadoop002</name>
<value>hadoop002:50070</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.ns1</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>64M</value>
<!-- <value>128M</value> -->
<description>HDFS blocksize of 128MB for large file-systems</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
<description>More NameNode server threads to handle RPCs from large number of DataNodes.</description>
</property>
<!--这是配置提供共享编辑存储的journalnode地址的地方,这些地址由活动nameNode写入,由备用nameNode读取,以便与活动nameNode所做的所有文件系统更改保持最新。虽然必须指定几个JournalNode地址,但是应该只配置其中一个uri。URI的形式应该是:qjournal://*host1:port1*;*host2:port2*;*host3:port3*/*journalId*。日志ID是这个名称服务的惟一标识符,它允许一组日志节点为多个联合名称系统提供存储 /usr/shell/scp.sh hdfs-site.xml /usr/local/hadoop/hadoop/etc/hadoop
rm -rf /home/cluster/* rm -rf /usr/local/hadoop/hadoop/logs/* -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/ns1</value>
</property>
<!-- 隔离方法;确保当前时间点只有一个namenode处于active状态,jurnalnode只允许1个namenode来读写数据,但是也会出现意外的情况,因此需要控制对方机器,进行将自我提升[active],将对方降级[standby] -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Configurations for MapReduce Applications -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Execution framework set to Hadoop YARN.</description>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
<!-- <value>1536</value> -->
<description>Larger resource limit for maps.</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx4096M</value>
<!-- <value>-Xmx2048M</value> -->
<description>Larger heap-size for child jvms of maps.</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
<!-- <value>3072</value> -->
<description>Larger resource limit for reduces.</description>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx4096M</value>
<description>Larger heap-size for child jvms of reduces.</description>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>4096</value>
<!-- <value>1024</value> -->
<description>Higher memory-limit while sorting data for efficiency.</description>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>400</value>
<!-- <value>200</value> -->
<description>More streams merged at once while sorting files.</description>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>200</value>
<!-- <value>100</value> -->
<description>Higher number of parallel copies run by reduces to fetch outputs from very large number of maps.</description>
</property>
<!-- Configurations for MapReduce JobHistory Server -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop001:10020</value>
<description>MapReduce JobHistory Server host:port.Default port is 10020</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop001:19888</value>
<description>MapReduce JobHistory Server Web UI host:port.Default port is 19888.</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/tmp/mr-history/tmp</value>
<description>Directory where history files are written by MapReduce jobs.</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/tmp/mr-history/done</value>
<description>Directory where history files are managed by the MR JobHistory Server.</description>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--是否启用自动故障转移。默认情况下,在启用 HA 时,启用自动故障转移。-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--启用内置的自动故障转移。默认情况下,在启用 HA 时,启用内置的自动故障转移。-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop001</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop002</value>
</property>
<!--启用 resourcemanager 自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--配置 Zookeeper 地址-->
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop001:8032</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop002:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop001:8034</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop001:8088</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop002:8034</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop002:8088</value>
</property>
<!-- Configurations for ResourceManager and NodeManager -->
<property>
<name>yarn.acl.enable</name>
<value>true</value>
<description>Enable ACLs? Defaults to false.</description>
</property>
<property>
<name>yarn.admin.acl</name>
<value>*</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>false</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<!-- Configurations for ResourceManager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
<description>host Single hostname that can be set in place of setting all yarn.resourcemanager*address resources. Results in default ports for ResourceManager components.</description>
</property>
<!-- spark on yarn -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>28672</value>
</property>
<!-- Configurations for NodeManager -->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/cluster/yarn/log/1,/home/cluster/yarn/log/2,/home/cluster/yarn/log/3</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>
<!--
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>Environment properties to be inherited by containers from NodeManagers</value>
<description>For mapreduce application in addition to the default values HADOOP_MAPRED_HOME should to be added. Property value should JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</description>
</property>
-->
<!-- Configurations for History Server (Needs to be moved elsewhere) -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>-1</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>-1</value>
</property>
</configuration>
五、初始化集群
1、启动zookeeper
由于hadoop的HA机制依赖于zookeeper,因此先启动zookeeper集群
如果zookeeper集群没有搭建参考:https://blog.csdn.net/qq262593421/article/details/106955485
zkServer.sh start
zkServer.sh status
2、在zookeeper中初始化元数据
hdfs zkfc -formatZK
3、启动zkfc
hdfs --daemon start zkfc
4、启动JournalNode
格式化NameNode前必须先格式化JournalNode,否则格式化失败
这里配置了3个JournalNode节点,hadoop001、hadoop002、hadoop003
hdfs --daemon start journalnode
5、格式化NameNode
在第一台NameNode节点上执行
hdfs namenode -format
6、启动hdfs
start-all.sh
7、同步备份NameNode
等hdfs初始化完成之后(20秒),在另一台NameNode上执行
hdfs namenode -bootstrapStandby
?如果格式化失败或者出现以下错误,把对应节点上的目录删掉再重新格式化
Directory is in an inconsistent state: Can't format the storage directory because the current directory is not empty.



rm -rf /home/cluster/hadoop/data/jn/ns1/*
hdfs namenode -format
8、启动备份NameNode
同步之后,需要在另一台NameNode节点上启动NameNode进程
hdfs --daemon start namenode
9、查看集群状态
hadoop dfsadmin -report
10、访问集群
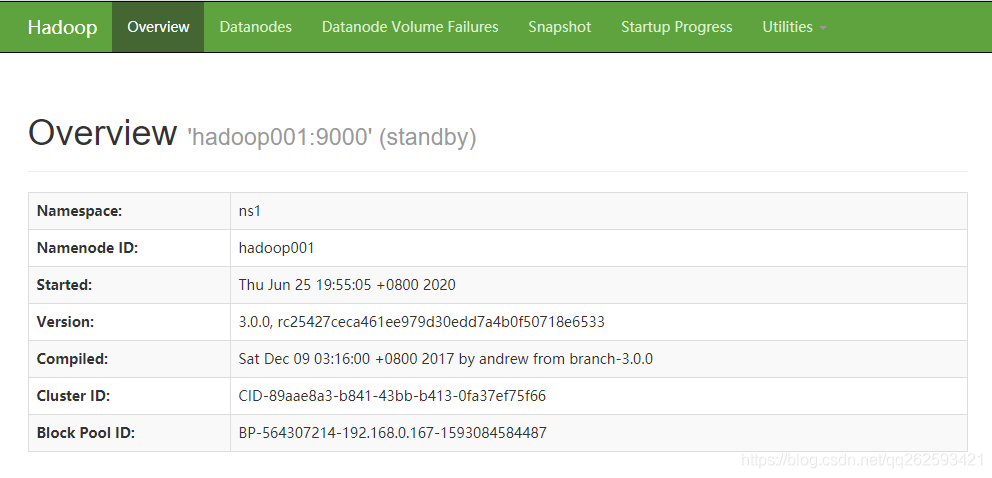
http://hadoop001:50070/
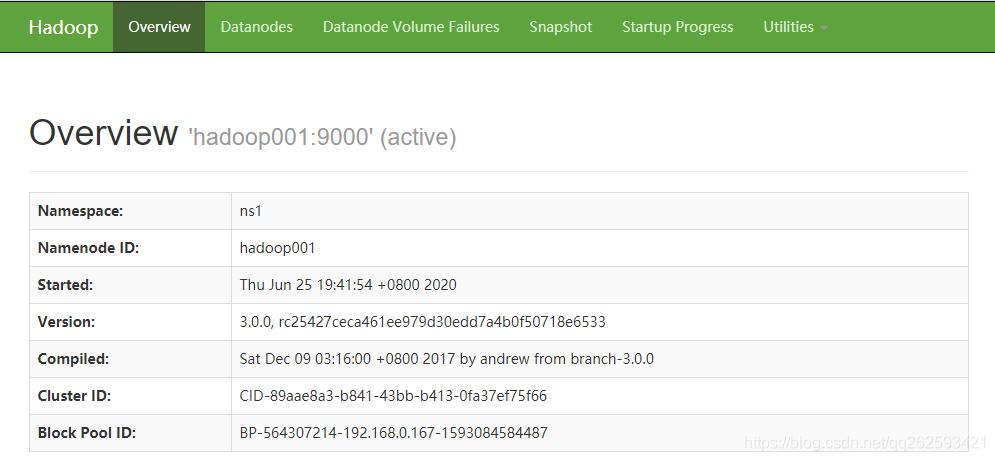
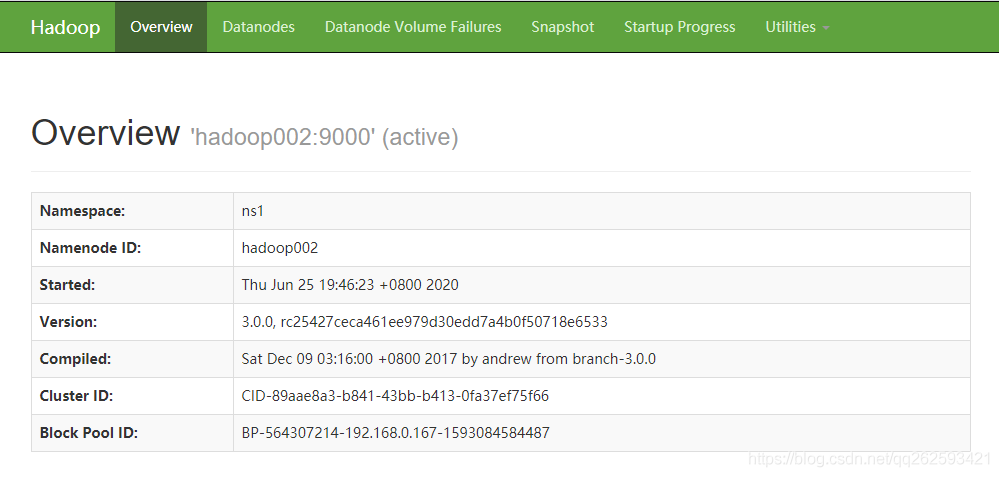
http://hadoop002:50070/
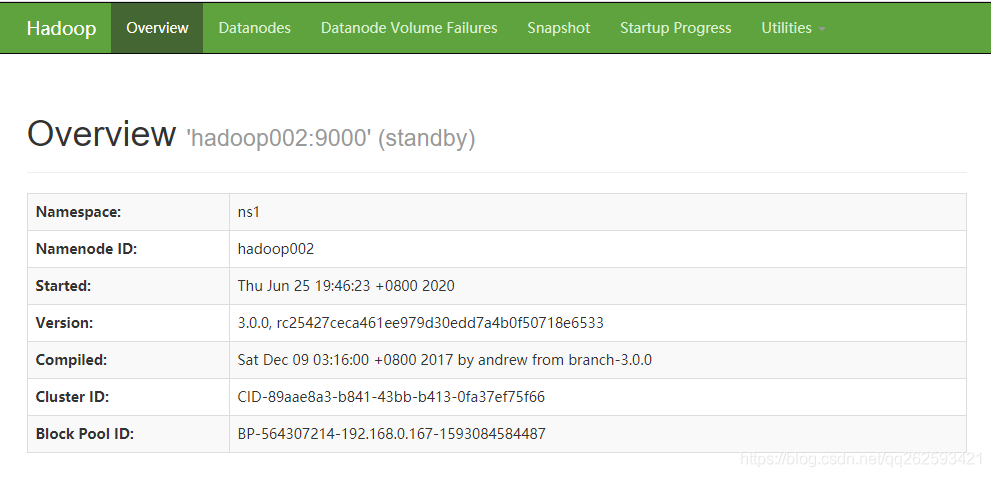
六、集群高可用测试
1、停止Active状态的NameNode
在active状态上的NameNode执行(hadoop1)
hdfs --daemon stop namenode
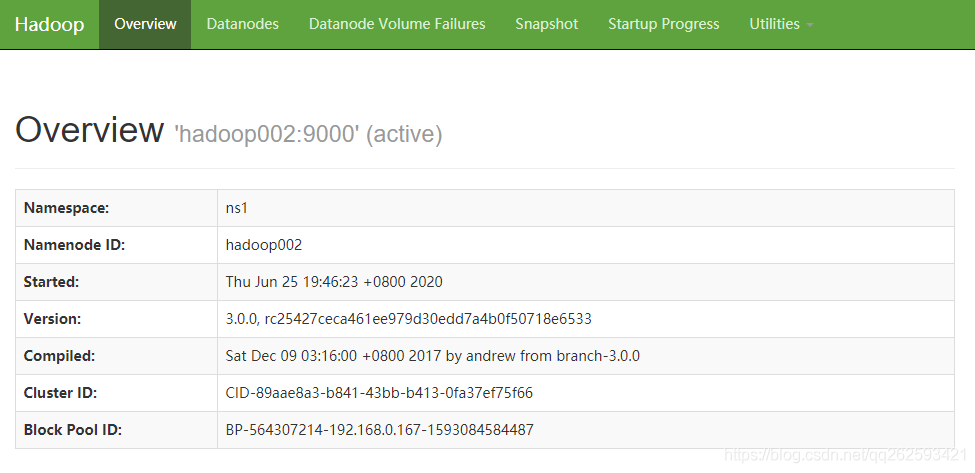
2、查看standby状态的NameNode
http://hadoop002:50070/?可以看到,hadoop2从standby变成了active状态
3、重启启动停止的NameNode
停止之后,浏览器无法访问,重启恢复
hdfs --daemon start namenode
4、查看两个NameNode状态
http://hadoop001:50070/
http://hadoop002:50070/
cs