pythonДгзжЗћДЎжаЬсШЁЪ§зж
ЪЙгУе§дђБэДяЪНЃЌгУЗЈШчЯТЃК
## змНс
## ^ ЦЅХфзжЗћДЎЕФПЊЪМЁЃ
## $ ЦЅХфзжЗћДЎЕФНсЮВЁЃ
## \b ЦЅХфвЛИіЕЅДЪЕФБпНчЁЃ
## \d ЦЅХфШЮвтЪ§зжЁЃ
## \D ЦЅХфШЮвтЗЧЪ§зжзжЗћЁЃ
## x? ЦЅХфвЛИіПЩбЁЕФ x зжЗћ (ЛЛбджЎЃЌЫќЦЅХф 1 ДЮЛђеп 0 ДЮ x зжЗћ)ЁЃ
## x* ЦЅХф0ДЮЛђепЖрДЮ x зжЗћЁЃ
## x+ ЦЅХф1ДЮЛђепЖрДЮ x зжЗћЁЃ
## x{n,m} ЦЅХф x зжЗћЃЌжСЩй n ДЮЃЌжСЖр m ДЮЁЃ
## (a|b|c) вЊУДЦЅХф aЃЌвЊУДЦЅХф bЃЌвЊУДЦЅХф cЁЃ
## (x) вЛАуЧщПіЯТБэЪОвЛИіМЧвфзщ (remembered group)ЁЃФуПЩвдРћгУ re.search КЏЪ§ЗЕЛиЖдЯѓЕФ groups() КЏЪ§ЛёШЁЫќЕФжЕЁЃ
## е§дђБэДяЪНжаЕФЕуКХЭЈГЃвтЮЖзХ ЁАЦЅХфШЮвтЕЅзжЗћЁБ
НтЬтЫМТЗЃК
МШШЛЪЧЬсШЁЪ§зжЃЌФЧУДЪ§зжЕФаЮЪНвЛАуЪЧЃКећЪ§ЃЌаЁЪ§ЃЌећЪ§МгаЁЪ§ЃЛ
ЫљвдвЛАуЪЧаЮШчЃК----.-----ЃЛ
ИљОнЩЯЪіе§дђБэДяЪНЕФКЌвхЃЌПЩаДГіШчЯТЕФБэДяЪНЃК"\d+\.?\d*"ЃЛ
\d+ЦЅХф1ДЮЛђепЖрДЮЪ§зжЃЌзЂвтетРяВЛвЊаДГЩ*ЃЌвђЮЊМДБуЪЧаЁЪ§ЃЌаЁЪ§ЕужЎЧАвВЕУгавЛИіЪ§зжЃЛ\.?етИіЪЧЦЅХфаЁЪ§ЕуЕФЃЌПЩФмгаЃЌвВПЩФмУЛгаЃЛ\d*етИіЪЧЦЅХфаЁЪ§ЕужЎКѓЕФЪ§зжЕФЃЌЫљвдЪЧ0ИіЛђепЖрИіЃЛ
ДњТыШчЯТЃК
import re
string="A1.45ЃЌb5ЃЌ6.45ЃЌ8.82"
print re.findall(r"\d+\.?\d*",string)
# ['1.45', '5', '6.45', '8.82']
ЦЅХфжИЖЈзжЗћДЎПЊЭЗЕФЪ§зж
Р§ШчЯТУцЕФstringЃК
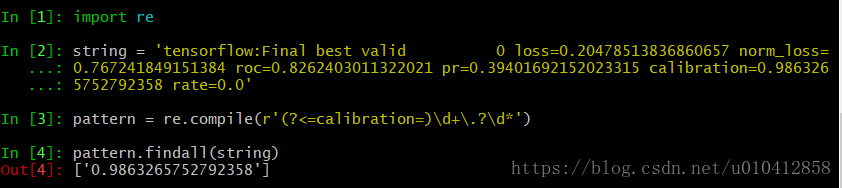
tensorflow:Final best valid 0 loss=0.20478513836860657 norm_loss=0.767241849151384 roc=0.8262403011322021 pr=0.39401692152023315 calibration=0.9863265752792358 rate=0.0
ЬсШЁ calibration=0.9863265752792358 .
# ЦЅХфЁАcalibration=ЁБКѓУцЕФЪ§зж
pattern = re.compile(r'(?<=calibration=)\d+\.?\d*')
pattern.findall(string)
# ['0.9863265752792358']
ЦЅХфАќКЌжИЖЈзжЗћДЎПЊЭЗЕФЪ§зж
pattern = re.compile(r'(?:loss=)\d+\.?\d*')
pattern.findall(string)
# ['loss=0.20478513836860657', 'loss=0.767241849151384']

ЦЅХфЪБМфЃЌ17:35:24
string = "WARNING:tensorflow: 20181011 15:28:39 Initialize training"
pattern = re.compile(r'\d{2}:\d{2}:\d{2}')
pattern.findall(string)
# ['15:28:39']
ЦЅХфЪБМфЃЌ20181011 15:28:39
string = "WARNING:tensorflow: 20181011 15:28:39 Initialize training"
pattern = re.compile(r'\d{4}\d{2}\d{2}\s\d{2}:\d{2}:\d{2}')
pattern.findall(string)
# ['20181011 15:28:39']
змНс
вдЩЯЫљЪіЪЧаЁБрИјДѓМвНщЩмЕФpythonе§дђБэДяЪНДгзжЗћДЎжаЬсШЁЪ§зжЕФЫМТЗЯъНт ,ЯЃЭћЖдДѓМвгаЫљАяжњЃЌШчЙћДѓМвгаШЮКЮвЩЮЪЧыИјЮвСєбдЃЌаЁБрЛсМАЪБЛиИДДѓМвЕФЁЃдкДЫвВЗЧГЃИааЛДѓМвЖдеОГЄВЉПЭЭјеОЕФжЇГжЃЁ
ШчЙћФуОѕЕУБОЮФЖдФугаАяжњЃЌЛЖгзЊдиЃЌЗГЧызЂУїГіДІЃЌаЛаЛЃЁ
jsjbwy