热门评论:

题记:

?以下是正文:
目录
一、确定索引
1、索引解释及索引查询
2、问题及解答
????????a、索引有单个索引和组合索引等,
????????b、组合索引的最左原则:
????????c、当用到的索引字段,
二、查询语句
情况一:
情况二:
三、引擎
总结:
(下一篇)?16 条 yyds 的代码规范
40 个 SpringBoot 常用注解
一、确定索引
1、索引解释及索引查询
- ????????索引:给某个字段建一个属于它的目录。
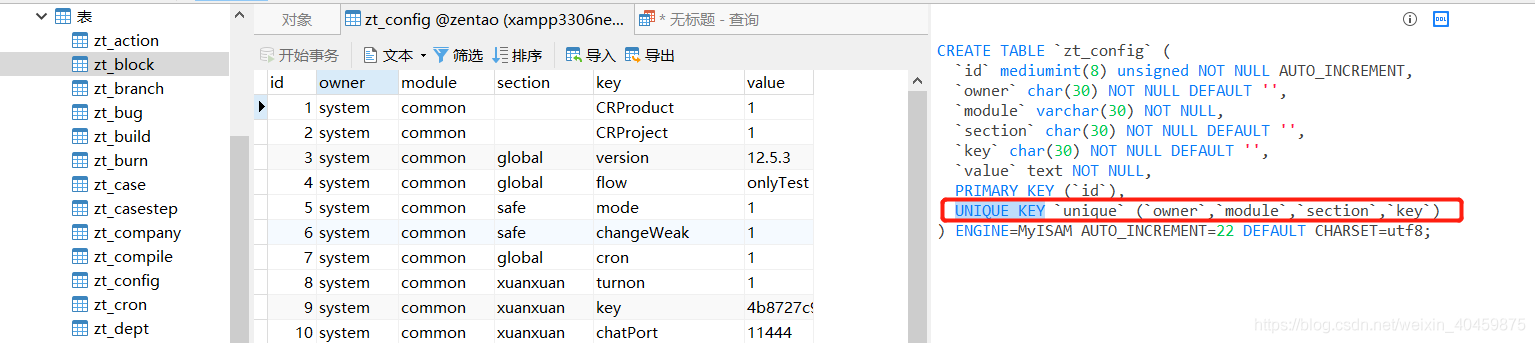
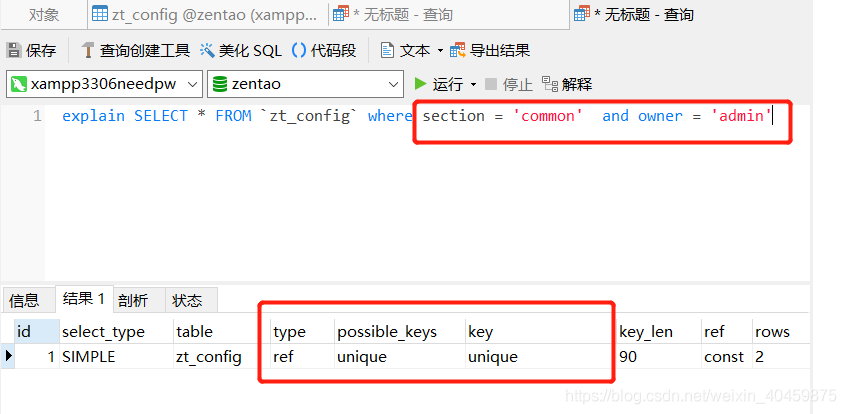
????????打开某张表,如图,UNIQUE KEY 就是一个索引,且是唯一索引,且是组合索引。
????????它这个索引是`owner`,`module`,`section`,`key` 这四个字段组成的一个索引,这四个字段组合可以确定唯一的数据。
????????所以:UNIQUE KEY `unique` (`owner`,`module`,`section`,`key`) 即是四个字段组合成了一个唯一组合索引。
????????我们在查询的时候,如果遇到查询慢,第一步就是确定这个表有没有索引,第二步确定查询语句有没有用到索引,是否是全文检索数据,如果是全文检索,我们优化时就可以做成用索引查询。
????????网上的图书目录就是一个很好的例子,用目录(索引)查询比一页一页翻书查询要快的多。
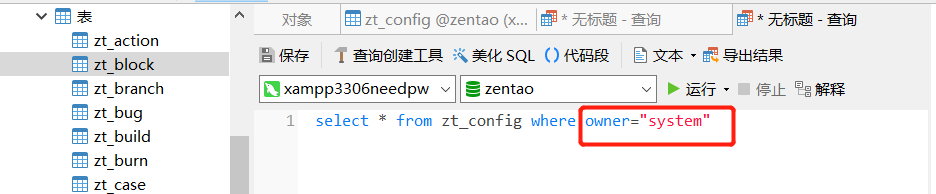
- ????????索引查询:即在where 后面跟上索引字段的条件,例如:
2、问题及解答
????????a、索引有单个索引和组合索引等,
对于我们上面的组合索引UNIQUE KEY `unique` (`owner`,`module`,`section`,`key`) ,是否建立四个单个索引,查询效率一样?
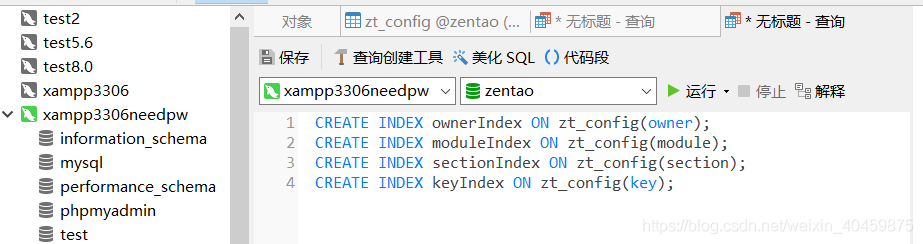
答:否,虽然此时有了四个索引,但 MySQL 只能用到其中的那个它认为似乎是最有效率的单列索引。所以和四个字段组合成一个索引的效率是不一样的。
????????b、组合索引的最左原则:
????????where后面一定要有组合索引最左边的字段,这个索引才能生效,否则索引不生效(即,一定要有owner字段,否则即使用索引里面的section 、key等字段放在where后面,也不会用到它的索引,还是会全文检索)。
- (2)用了owner索引才生效:(owner和section 前后顺序没关系,似乎是mysql优化了,因为之前的版本owner必须在前,索引才能生效。)
但是,如果一个表中所有的字段都建立了索引,那不管怎么查,都会用到索引,因为它相当于给整个表建立了索引,所以这种情况不存在最左原则。
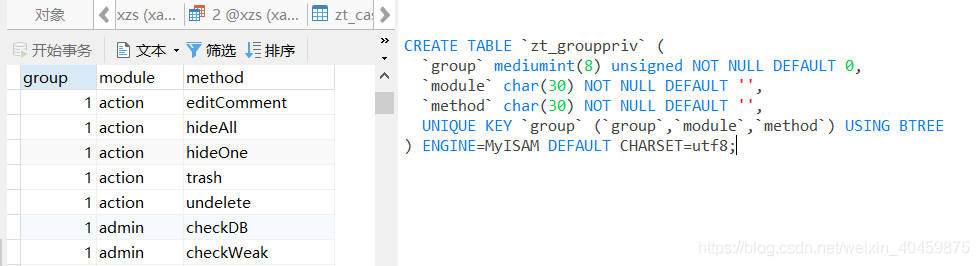
比如这张表:
????????一共3个字段,3个字段都建立了索引,所以where后面不管怎么查,都是用到了索引:

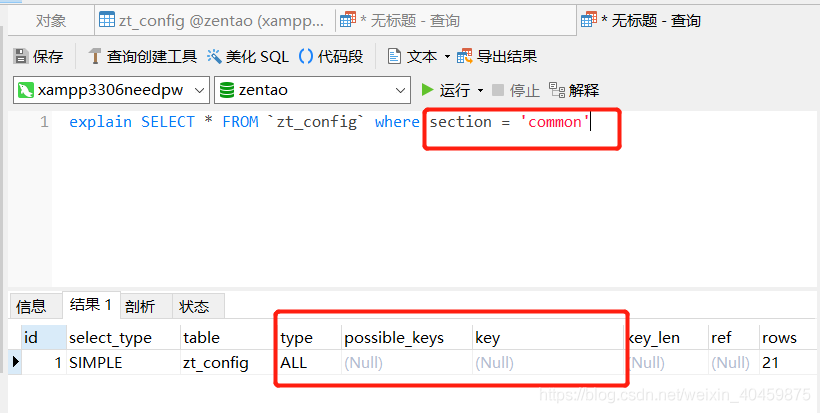
????????c、当用到的索引字段,
????????它的值在表中数据大部分都一样时,用这个索引字段查询,索引仍旧不生效:
例如:索引字段owner,它有两个值,“system”占了很多,“admin”只有两个。那么我用 where owner="system"时,索引就不生效,而用where owner="admin"时,索引就生效,这也很好理解,因为你要查的数据值占了很大篇幅,我直接全文检索就可以了,你查的值只占了很小的篇幅,我再用索引就会明显快。
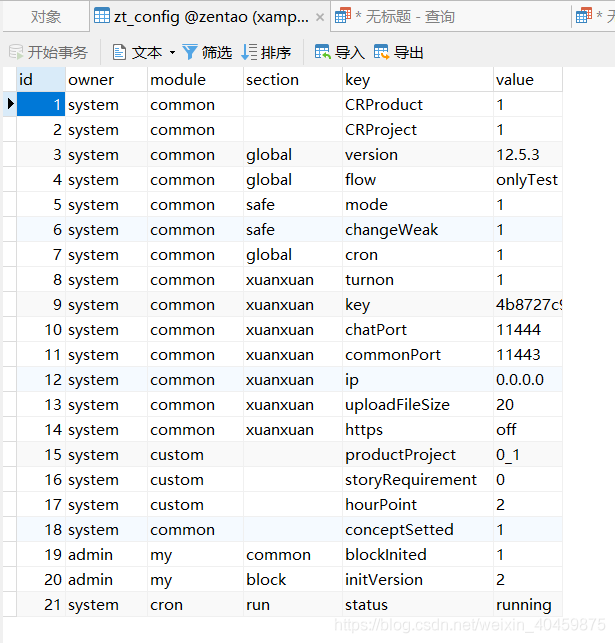
where owner="system"时,索引就不生效:
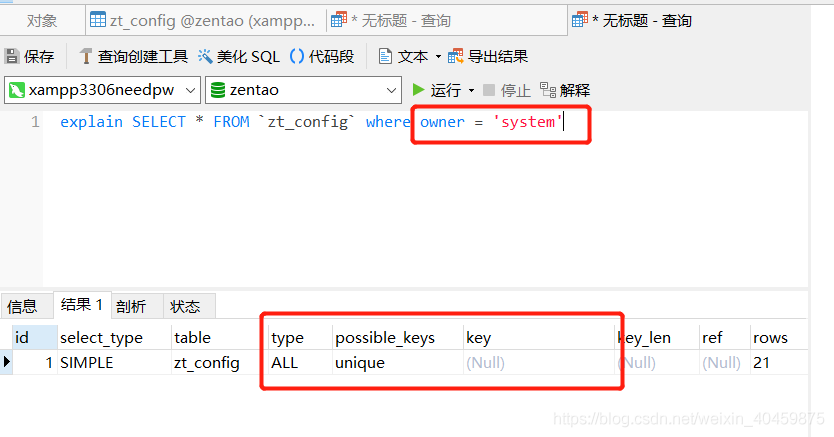
where owner="admin"时,索引就生效:
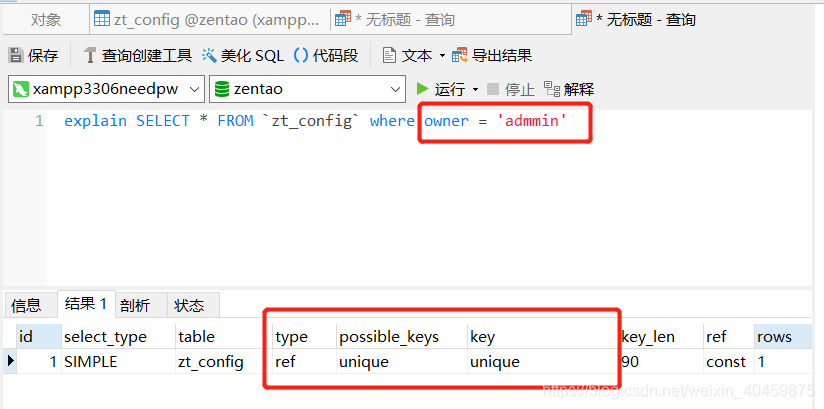
有些说法“当索引字段查询条件有??> = < + - * % is null ,is not null?时,索引不生效 ”,但其实我执行的时候,都生效,所以mysql不同版本应该有不同要求,至于要完全弄清,大概要花费非常多的时间,是DBA的必修吧。
但对于我们来说,每个人职业规划不同,所以术业专攻。
二、查询语句
讲完索引,我们看语句。
下面只讲两种情况:
情况一:
????????sql1:?
select
*
from
zt_grouppriv t1
left join
zt_group t2
on
t1.`group` = t2.id
where
t1.module = "bug"
这种查询,第一步会先生成一个虚拟表,这个虚拟表里有t1的所有数据,如果t1非常大,那么就会生成一个非常大的虚拟表;
- 第二步才会用where t1.module = "bug" 做筛选。
所以优化的思路就是:1、先过滤t1的数据,可以用索引过滤。2、在过滤之后的t1小表和t1做联合查询。
语句即是:
????????sql2:
select *
from (
select *
from
zt_grouppriv
where
module="bug"
) t1
left join
zt_group t2
on
t1.`group` = t2.id
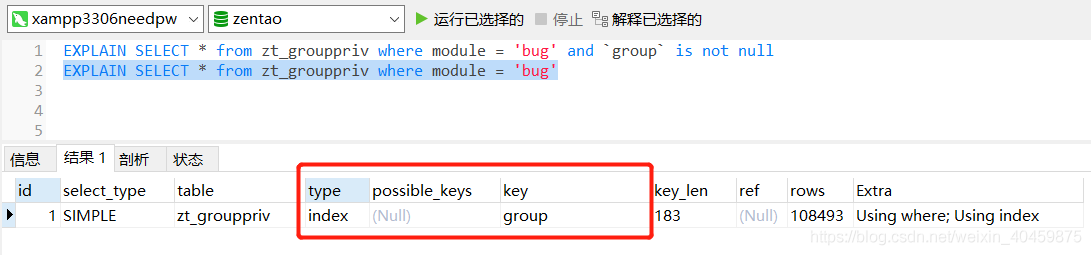
这里有个问题,如果module不是索引或者不是最左索引怎么办,那select * from zt_grouppriv where module="bug" 是全文检索,所以虽然比sql1快,但也没有"极致"优化。
此时,我们可以1.如果module不是索引,给module设置为单个索引;2.如果module不是最左索引,给select * from zt_grouppriv where module="bug" 加上最左索引查询,比如最左是group字段:
select * from zt_grouppriv where module="bug" and `group` is not null,即sql变成:
select
*
from
(
select
*
from
zt_grouppriv
where
module="bug" and `group` is not null
) t1
left join
zt_group t2
on
t1.`group` = t2.id
关于sql执行顺序可以查看:https://blog.csdn.net/u011630575/article/details/51002126
情况二:
对于联合查询,如果我们只用到某张表的某一个字段,那么其实我们可以不用写联合查询语句也可以实现联合查询功能。
思路:
- ????????第一步:查t1表符合要求的数据(可以用到索引);
- ????????第二步:t1表的数据放到一个集合里,在代码里用for循环这个集合,写sql语句查询t2表,条件是t1返回的结果,查询字段是我们需要的t2的某一个字段。
例如:t1表要查 module="bug"的数据;t2表要查t2的name字段值,条件是t2的id等于t1的group字段。联合查询:
select t1.*,t2.name from zt_grouppriv t1 left join zt_group t2
on t1.`group` = t2.id
where t1.module = "bug"
按我们的思路修改之后:
- ????????1、查询 zt_grouppriv 符合条件的,比如我要查module="bug"的数据,至于用不用索引,要看具体实现是否使用索引更快速。
- ????????2、
for(zt_grouppriv 返回的数据集合,比如是list){
select name from zt_group t2 where t2.id = list.getId();
grouppriv.setName(name);
}
grouppriv是我们代码里的类,它的属性就是t1的某些字段和t2的name。
具体如何修改,是不是要用索引,是不是要组合查询等等等等,一定要按实际情况来,因为索引不是一定可以优化的,索引也会增加开销。
数据库优化是一个非常大的领域,没办法出几个固定公式说套用就可以,
所以一定要按实际情况为主,做完优化之后,要测试完全,适用的才是好用的。
三、引擎
最后我们补充一下数据库引擎,它一开始是在建表的时候就确定的,所以一般我们做优化,不会涉及修改引擎,除非要新建一个表,那么我们就要关注,用什么引擎,对你的crud更友好。
mysql有InnoDB和MyISAM 两种引擎。
- MyISAM 不支持事务,所以它主要应用于查询插入比较多,修改比较少,或者对数据修改要求不高的库。比如文章报道这种库,或者我们例子中用的禅道。
- InnoDB支持事务,但是它查询不如MyISAM。
MyISAM是表级锁,即我们做修改的时候,哪怕修改一条数据,它也会锁住整个表,别人就不能修改了:
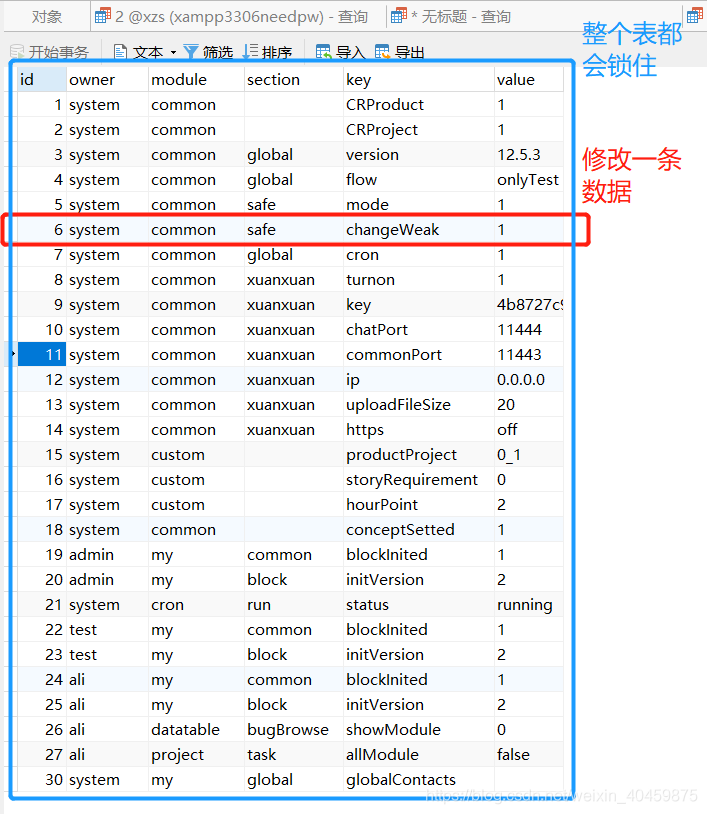
InnoDB是行级锁,只锁你正在修改的数据:
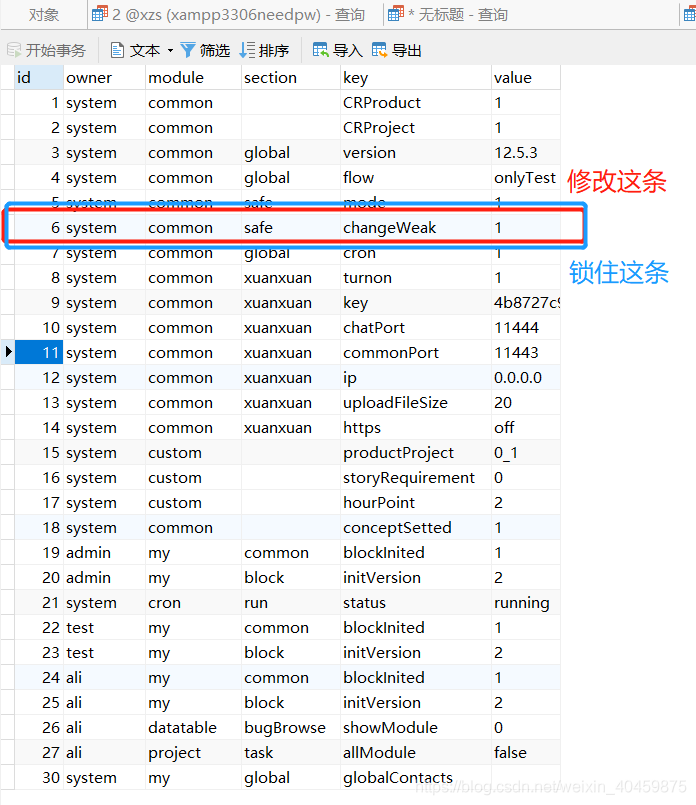
表锁行锁也说明了,
- MyISAM应用于查询插入比较多,修改比较少的库。
- InnoDB适用用修改比较多,对事务,对数据修改要求比较高的库,比如涉及交易、金钱这种的库。
但同样的InnoDB查询不如MyISAM快,
我们用实例来说明:
- ????????zentao库的zt_grouppriv 和?zt_group 两个表和 xzs库的zt_grouppriv 和?zt_group 两个表字段数据完全一样,
- ????????但是zentao库的zt_grouppriv 和?zt_group用MyISAM引擎,
- ????????xzs库的zt_grouppriv 和?zt_group用InnoDB引擎。
我们分别看下查询速度:
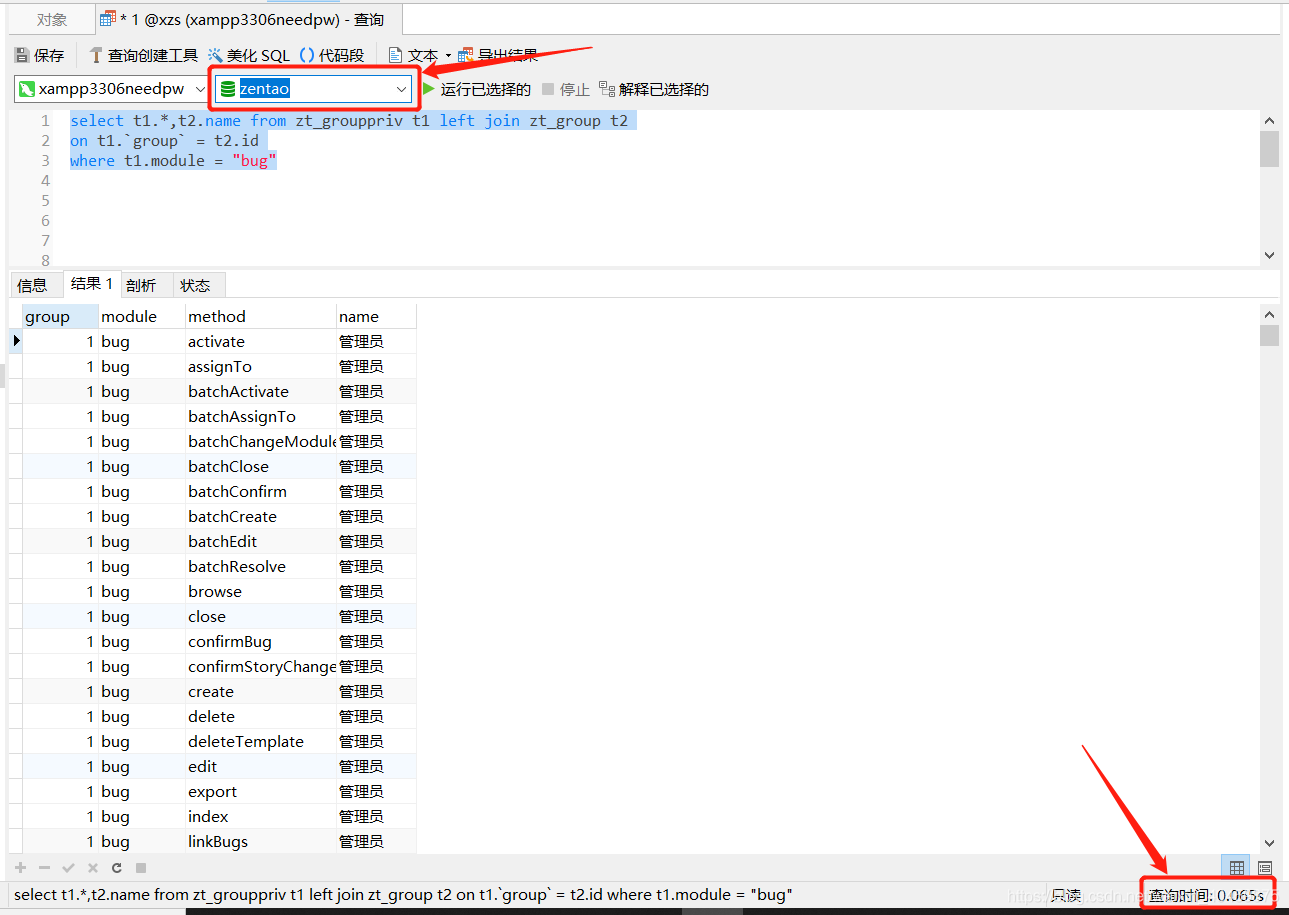
zentao库,zt_grouppriv 和?zt_group用MyISAM引擎:
xzs库,zt_grouppriv 和?zt_group用InnoDB引擎:
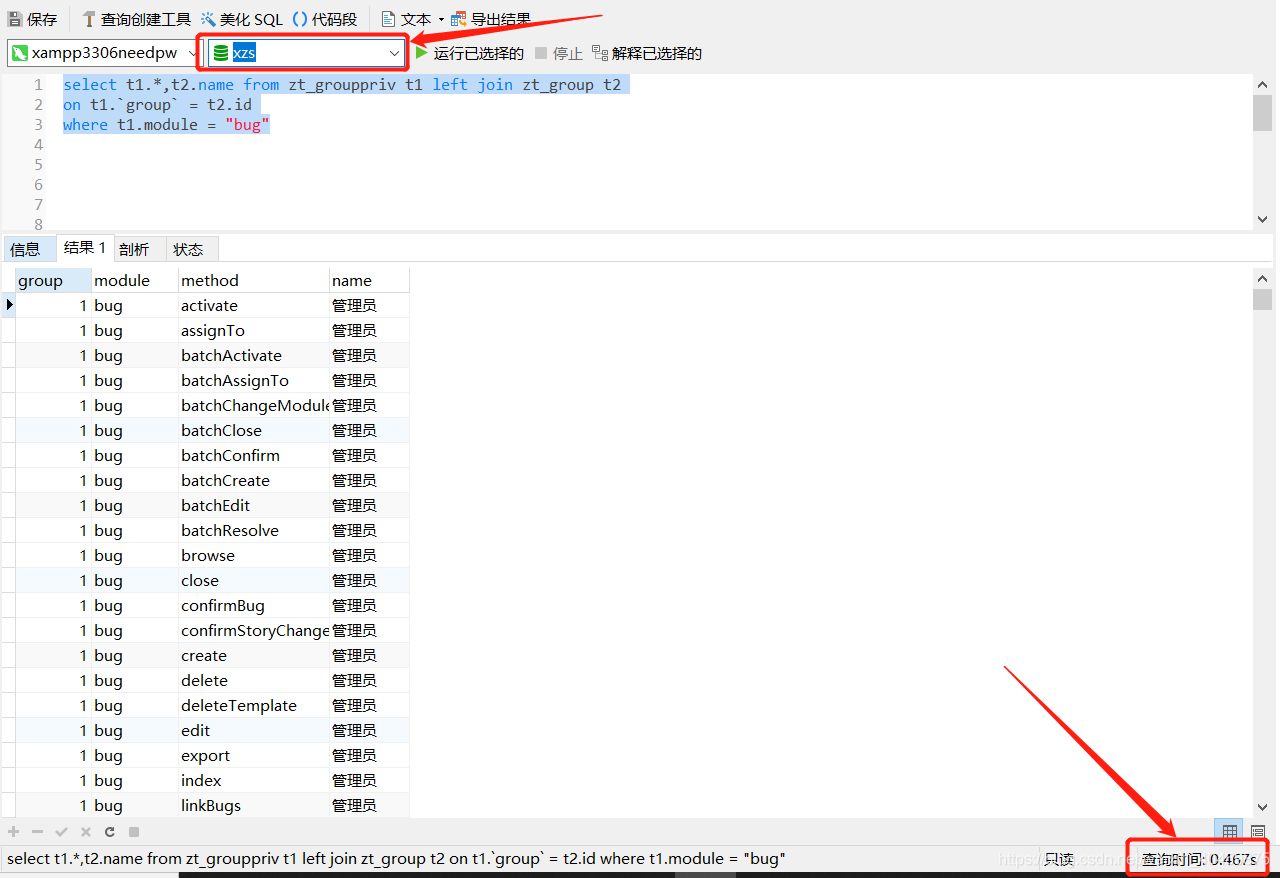
对比还是非常明显的,可以了解到
????????MyISAM引擎 相比较于InnoDB引擎,查询速度更快。
至于更底层的数据结构,需要花更多的时间精力学习,还是一句话:
- 看是否符合你的职业规划~~
- 毕竟人生最重要的必修课就是知道自己所往
????????????????如上,技术在于交流流通,/握手
原文作者:高一级花阿梨喜欢吃榴莲
???????https://blog.csdn.net/weixin_40459875/article/details/115794319


?五年从程序员到架构师!这是我见过史上最好的程序员职业规划
(下一篇)?16 条 yyds 的代码规范
40 个 SpringBoot 常用注解
别慌,在Java面试的时候,面试官会这样问关于框架的问题?

想要实时关注更多干货好文,扫描下图关注或微信搜索【万言尽书上】关注公众公众号:

cs