-- ����ʱָ���洢���档Ĭ�ϵľ���INNODB,����Ҫ����CREATE TABLE t1 (i INT) ENGINE = INNODB;CREATE TABLE t2 (i INT) ENGINE = CSV;CREATE TABLE t3 (i INT) ENGINE = MEMORY;-- �Ĵ洢����ALTER TABLE t ENGINE = InnoDB;-- ��Ĭ�ϴ洢����,Ҳ�����������ļ�my.cnf����Ĭ������SET default_storage_engine=NDBCLUSTER;
Ĭ�������,ÿ�� CREATE TABLE �� ALTER TABLE ����ʹ��Ĭ�ϴ洢����ʱ,��������һ�����档Ϊ�˷�ֹ����������治����ʱ�������������������Ϊ,�������� NO_ENGINE_SUBSTITUTION SQL ģʽ�������������治����,������ý�������������Ǿ���,���Ҳ��ᴴ������ı�
�洢����Ա�
�����Ĵ洢����� InnoDB��MyISAM��Memory��NDB��
InnoDB ������ MySQL Ĭ�ϵĴ洢����,֧�������м����������
�ļ��洢�ṹ�Ա�
�� MySQL�н����κ�һ�����ݱ�,��������Ŀ¼��Ӧ�����ݿ�Ŀ¼�¶��ж�Ӧ���� .frm �ļ�,.frm �ļ�����������ÿ�����ݱ���Ԫ����(meta)��Ϣ,�������ṹ�Ķ����,�����ݿ�洢������,Ҳ�����κδ洢��������ݱ���������.frm�ļ�,������ʽΪ ���ݱ���.frm,��user.frm��
�鿴MySQL ���ݱ���������:show variables like 'data%'
MyISAM �����ļ��ṹΪ:
.frm�ļ�:�����ص�Ԫ������Ϣ�������frm�ļ�,�������ṹ�Ķ�����Ϣ��.MYD (MYData) �ļ�:MyISAM �洢����ר��,���ڴ洢MyISAM ��������.MYI (MYIndex)�ļ�:MyISAM �洢����ר��,���ڴ洢MyISAM �������������Ϣ
InnoDB �����ļ��ṹΪ:
-
.frm �ļ�:�����ص�Ԫ������Ϣ�������frm�ļ�,�������ṹ�Ķ�����Ϣ��
-
.ibd �ļ��� .ibdata �ļ�:�������ļ����Ǵ�� InnoDB ���ݵ��ļ�,֮�����������ļ���ʽ��� InnoDB ������,����Ϊ InnoDB �����ݴ洢��ʽ�ܹ�ͨ��������������ʹ���������ռ���Ŵ洢����,�������������ռ���Ŵ洢���ݡ�
�������ռ�洢��ʽʹ��.ibd�ļ�,����ÿ����һ��.ibd�ļ� �������ռ�洢��ʽʹ��.ibdata�ļ�,���б���ͬʹ��һ��.ibdata�ļ�(����,���Լ�����)
?
ps:������˾,��Щ����רҵ��άȥ��,���ݱ��ݡ��ָ�ɶ��,����һ�� Javaer ����Ļ�,��Ǯ��?
������ô�ش�
- InnoDB ֧������,MyISAM ��֧���������� MySQL ��Ĭ�ϴ洢����� MyISAM ��� InnoDB ����Ҫԭ��֮һ;
- InnoDB ֧�����,�� MyISAM ��֧�֡���һ����������� InnoDB ��תΪ MYISAM ��ʧ��;
- InnoDB �Ǿ۴�����,MyISAM �ǷǾ۴��������۴��������ļ����������������Ҷ�ӽڵ���,��� InnoDB ����Ҫ������,ͨ����������Ч�ʺܸߡ����Ǹ���������Ҫ���β�ѯ,�Ȳ�ѯ������,Ȼ����ͨ��������ѯ�����ݡ����,������Ӧ�ù���,��Ϊ����̫��,��������Ҳ����ܴ� MyISAM �ǷǾۼ�����,�����ļ��Ƿ����,����������������ļ���ָ�롣�����������������Ƕ����ġ�
- InnoDB ��������ľ�������,ִ��
select count(*) from table ʱ��Ҫȫ��ɨ�衣�� MyISAM ��һ������������������������,ִ���������ʱֻ��Ҫ�����ñ�������,�ٶȺܿ�; - InnoDB ��С��������������,MyISAM ��С���������DZ�����һ������������ס���ű�,����������ѯ���¶��ᱻ����,��˲����������ޡ���Ҳ�� MySQL ��Ĭ�ϴ洢����� MyISAM ��� InnoDB ����Ҫԭ��֮һ;
| �Ա��� | MyISAM | InnoDB |
|---|
| ����� | ��֧�� | ֧�� |
| ���� | ��֧�� | ֧�� |
| �б��� | ����,��ʹ����һ����¼Ҳ����ס������,���ʺϸ߲����IJ��� | ����,����ʱֻ��ijһ��,������������Ӱ��,�ʺϸ߲����IJ��� |
| ���� | ֻ��������,��������ʵ���� | ��������������Ҫ������ʵ����,���ڴ�Ҫ��ϸ�,�����ڴ��С�������о����Ե�Ӱ�� |
| ���ռ� | С | �� |
| ��ע�� | ���� | ���� |
| Ĭ�ϰ�װ | �� | �� |
?
һ�ű�,������ID��������,��insert��17����¼֮��,ɾ���˵�15,16,17����¼,�ٰ�Mysql����,��insertһ����¼,������¼��ID��18����15 ?
�������������MyISAM,��ô��18����ΪMyISAM������������������ID ��¼�������ļ���,����MySQL�������������IDҲ���ᶪʧ;
�������������InnoDB,��ô��15����ΪInnoDB ��ֻ�ǰ��������������ID��¼���ڴ���,�����������ݿ��Ա�����OPTION����,���ᵼ�����ID��ʧ��
?
�ĸ��洢����ִ�� select count(*) ����,Ϊʲô?
MyISAM����,��ΪMyISAM�ڲ�ά����һ��������,����ֱ�ӵ�ȡ��
- �� MyISAM �洢������,�ѱ����������洢�ڴ�����,��ִ�� select count(*) from t ʱ,ֱ�ӷ��������ݡ�
- �� InnoDB �洢������,�� MyISAM ��һ��,û�н��������洢�ڴ�����,��ִ�� select count(*) from t ʱ,���Ȱ����ݶ�����,һ��һ�е��ۼ�,�����������
InnoDB �� count(*) �������ִ�е�ʱ��,ȫ��ɨ��ͳ��������,���Ե�����Խ��Խ��ʱ,����Խ��Խ��ʱ��,Ϊʲô InnoDB ���治�� MyISAM ����һ��,���������洢��������?��� InnoDB �����������й�,���ڶ�汾��������(MVCC)��ԭ��,InnoDB ����Ӧ�÷��ض����С�Ҳ�Dz�ȷ���ġ�
������������
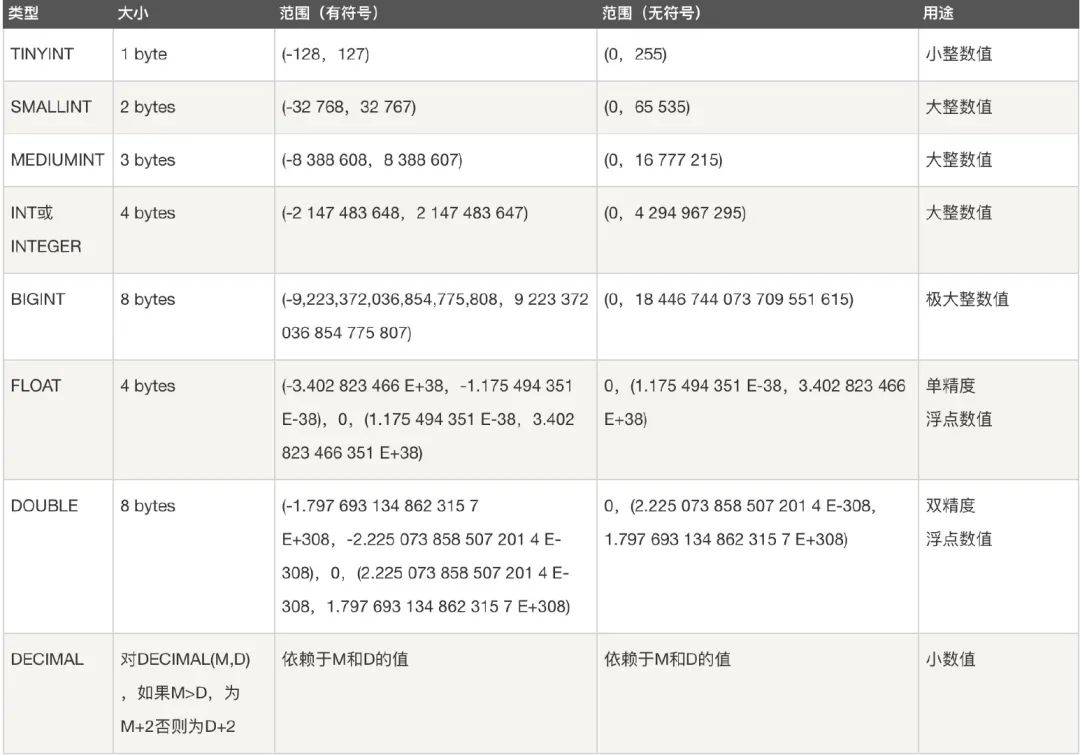
��Ҫ�������������:
- ��������:BIT��BOOL��TINY INT��SMALL INT��MEDIUM INT�� INT�� BIG INT
- ����������:FLOAT��DOUBLE��DECIMAL
- �ַ�������:CHAR��VARCHAR��TINY TEXT��TEXT��MEDIUM TEXT��LONGTEXT��TINY BLOB��BLOB��MEDIUM BLOB��LONG BLOB
- ��������:Date��DateTime��TimeStamp��Time��Year
- ������������:BINARY��VARBINARY��ENUM��SET��Geometry��Point��MultiPoint��LineString��MultiLineString��Polygon��GeometryCollection��
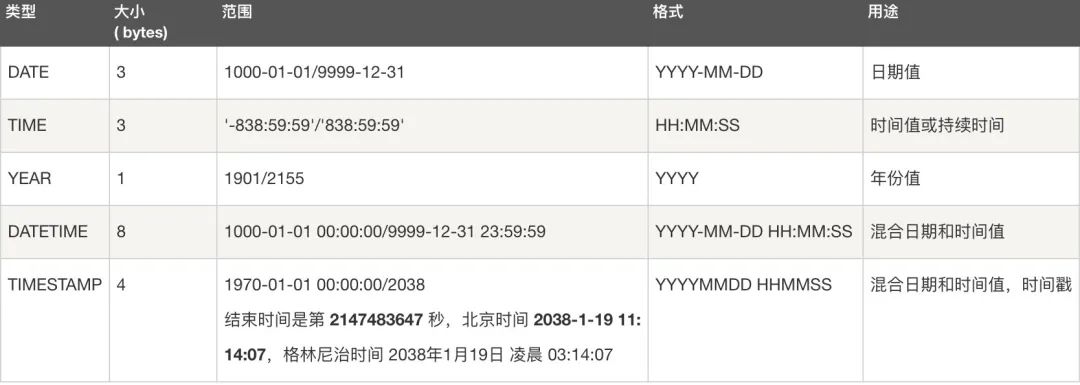
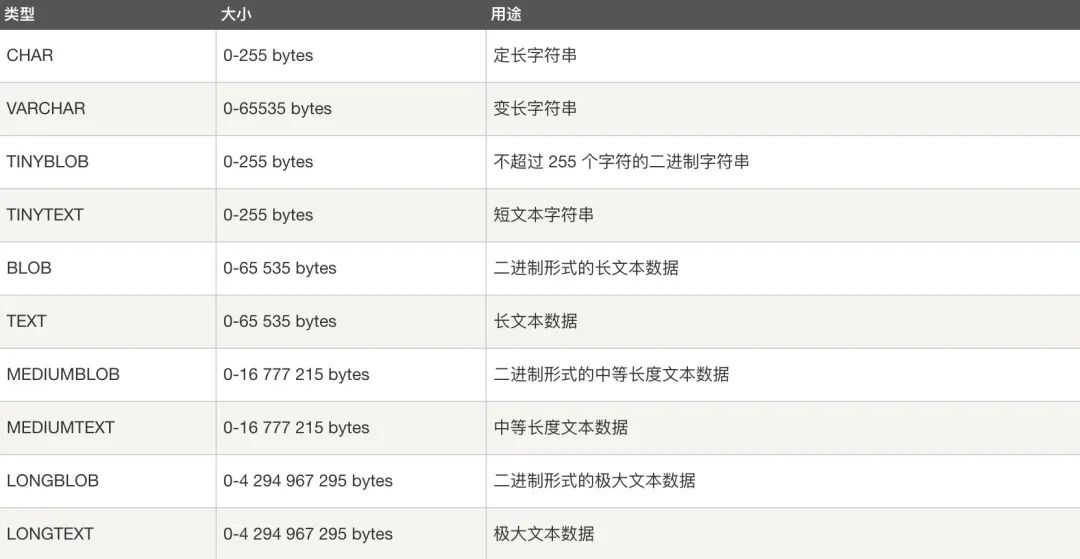
?
CHAR �� VARCHAR ������?
char�ǹ̶�����,varchar���ȿɱ�:
char(n) �� varchar(n) �������� n �����ַ��ĸ���,���������ֽڸ���,���� CHAR(30) �Ϳ��Դ洢 30 ���ַ���
�洢ʱ,ǰ�߲���ʵ�ʴ洢���ݵij���,ֱ�Ӱ� char �涨�ij��ȷ���洢�ռ�;���������ʵ�ʴ洢�����ݷ������յĴ洢�ռ�
��ͬ��:
- char(n),varchar(n)�е�n�������ַ��ĸ���
- ����char,varchar���n�����ƺ�,�ַ����ᱻ�ضϡ�
��ͬ��:
- char����ʵ�ʴ洢���ַ�������ռ��n���ַ��Ŀռ�,��varcharֻ��ռ��ʵ���ַ�Ӧ��ռ�õ��ֽڿռ��1(ʵ�ʳ���length,0<=length<255)���2(length>255)����Ϊvarchar��������ʱ����Ҫ�����ַ���֮����һ���ֽ�����¼����(������������ȴ���255��ʹ�������ֽ������泤��)��
- �ܴ洢�����ռ����Ʋ�һ��:char�Ĵ洢����Ϊ255�ֽڡ�
- char�ڴ洢ʱ��ض�β���Ŀո�,��varchar���ᡣ
char���ʺϴ洢�̵ܶġ�һ��̶����ȵ��ַ���������,char�dz��ʺϴ洢�����MD5ֵ,��Ϊ����һ��������ֵ�����ڷdz��̵���,char��varchar�ڴ洢�ռ���Ҳ����Ч�ʡ�
?
�е��ַ������Ϳ�����ʲô?
�ַ���������:SET��BLOB��ENUM��CHAR��CHAR��TEXT��VARCHAR
?
BLOB��TEXT��ʲô����?
BLOB��һ�������ƶ���,�������ɿɱ����������ݡ����������͵�BLOB:TINYBLOB��BLOB��MEDIUMBLO�� LONGBLOB
TEXT��һ�������ִ�Сд��BLOB������TEXT����:TINYTEXT��TEXT��MEDIUMTEXT �� LONGTEXT��
BLOB �������������,TEXT �����ַ����ݡ�
�ġ�����
?
˵˵��� MySQL ����������?
���ݿ�������ԭ��,ΪʲôҪ�� B+��,Ϊʲô���ö�����?
�ۼ�������Ǿۼ�����������?
InnoDB�����е���������,�˽����?
���������ķ�ʽ����Щ?
�۴�����/�Ǿ۴�����,mysql�����ײ�ʵ��,Ϊʲô����B-tree,Ϊʲô����hash,Ҷ�ӽ���ŵ������ݻ���ָ�����ݵ��ڴ��ַ,ʹ��������Ҫע��ļ����ط�?
- MYSQL�ٷ��������Ķ���Ϊ:����(Index)�ǰ���MySQL��Ч��ȡ���ݵ����ݽṹ,����˵�����ı�����:���ݽṹ
- ������Ŀ��������߲�ѯЧ��,��������ֵ䡢 ��վ�ij��α���ͼ���Ŀ¼�� ��
- ���Լ�����Ϊ���ź���Ŀ��ٲ������ݽṹ��,���ݱ���֮��,���ݿά����һ�������ض������㷨�����ݽṹ,��Щ���ݽṹ��ij�ַ�ʽ����(ָ��)����,�����Ϳ�������Щ���ݽṹ��ʵ�ָ������㷨���������ݽṹ,������������ͼ��һ�ֿ��ܵ�������ʽʾ����
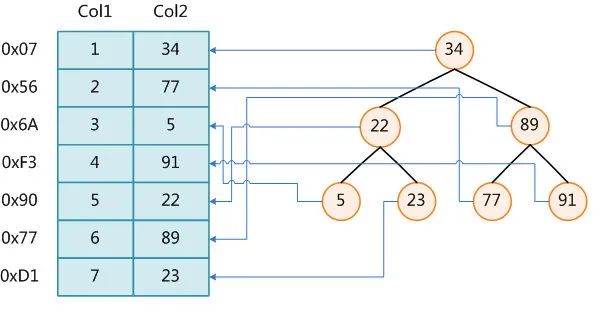 ��ߵ����ݱ�,һ��������������¼,����ߵ������ݼ�¼��������ַ��Ϊ�˼ӿ�Col2�IJ���,����ά��һ���ұ���ʾ�Ķ��������,ÿ���ڵ�ֱ����������ֵ,��һ��ָ���Ӧ���ݼ�¼������ַ��ָ��,�����Ϳ������ö��������һ���ĸ��Ӷ��ڻ�ȡ����Ӧ������,�Ӷ����ټ��������������ļ�¼��
��ߵ����ݱ�,һ��������������¼,����ߵ������ݼ�¼��������ַ��Ϊ�˼ӿ�Col2�IJ���,����ά��һ���ұ���ʾ�Ķ��������,ÿ���ڵ�ֱ����������ֵ,��һ��ָ���Ӧ���ݼ�¼������ַ��ָ��,�����Ϳ������ö��������һ���ĸ��Ӷ��ڻ�ȡ����Ӧ������,�Ӷ����ټ��������������ļ�¼�� - ��������Ҳ�ܴ�,������ȫ���洢���ڴ���,һ���������ļ�����ʽ�洢�ڴ�����
- ƽ��˵������,û���ر�ָ���Ļ�,����B+��(��·������,��һ���Ƕ�����)�ṹ��֯�����������оۼ�����,��Ҫ����,��������,��������,ǰ����,Ψһ����Ĭ�϶���ʹ��B+������,ͳ������������й�ϣ�����ȡ�
�����:
����
- ������ݼ���Ч��,�������ݿ�IO�ɱ�
- ������������ijɱ�,����CPU������
����
- ����Ҳ��һ�ű�,�����������������ֶ�,��ָ��ʵ����ļ�¼,����Ҳ��Ҫռ���ڴ�
- ��Ȼ�����������˲�ѯ�ٶ�,ͬʱȴ�ή���±����ٶ�,��Ա�����INSERT��UPDATE��DELETE����Ϊ���±�ʱ,MySQL����Ҫ��������,��Ҫ����һ�������ļ�ÿ�θ��������������е��ֶ�, ���������Ϊ�����������ļ�ֵ�仯���������Ϣ
MySQL��������
���ݽṹ�Ƕ�
- B+������
- Hash����
- Full-Textȫ������
- R-Tree����
�������洢�Ƕ�
�����Ƕ�
- ��������:����������һ�������Ψһ����,�������п�ֵ
- ��ͨ�������ߵ�������:ÿ������ֻ����������,һ���������ж����������
- ��������(������������������):��������ָ����ֶ��ϴ���������,ֻ���ڲ�ѯ������ʹ���˴�������ʱ�ĵ�һ���ֶ�,�����Żᱻʹ�á�ʹ�ø�������ʱ��ѭ����ǰ����
- Ψһ�������߷�Ψһ����
- �ռ�����:�ռ������ǶԿռ��������͵��ֶν���������,MYSQL�еĿռ�����������4��,�ֱ���GEOMETRY��POINT��LINESTRING��POLYGON��MYSQLʹ��SPATIAL�ؼ��ֽ�����չ,ʹ���ܹ����ڴ��������������͵�������ռ������������ռ���������,���뽫������ΪNOT NULL,�ռ�����ֻ���ڴ洢����ΪMYISAM�ı��д���
?
ΪʲôMySQL ��������B+tree,����B-tree ����������,Ϊʲô���� Hash ����
�۴�����/�Ǿ۴�����,MySQL �����ײ�ʵ��,Ҷ�ӽ���ŵ������ݻ���ָ�����ݵ��ڴ��ַ,ʹ��������Ҫע��ļ����ط�?
ʹ��������ѯһ������߲�ѯ��������?Ϊʲô?
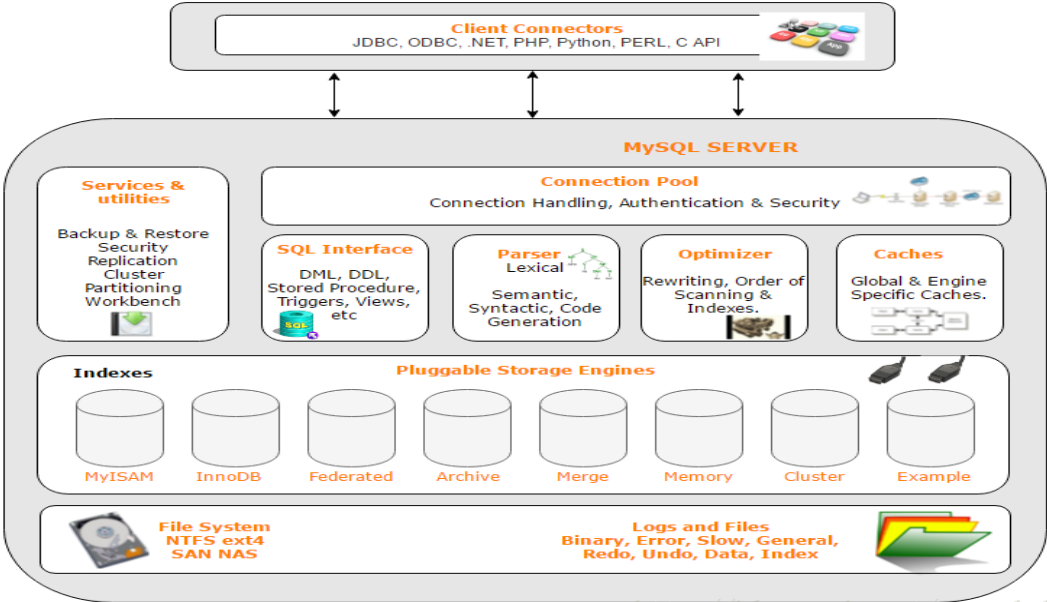
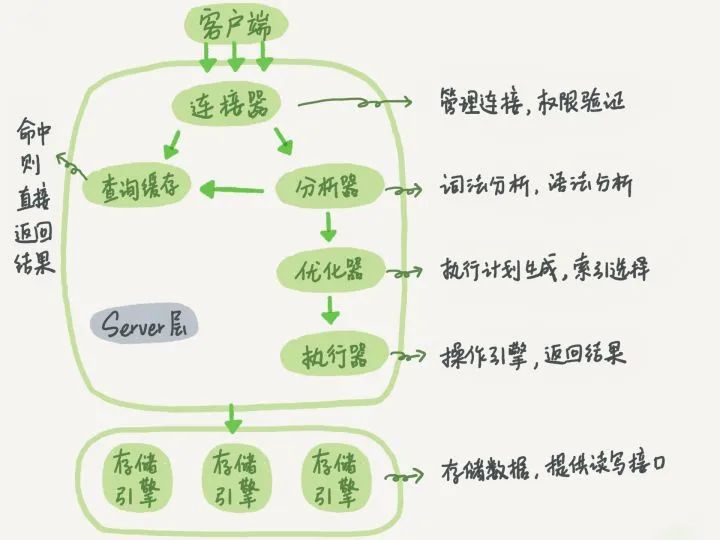
MySQL�����ṹ
����Ҫ��������(index)���ڴ洢����(storage engine)����ʵ�ֵ�,������server�������������еĴ洢���涼֧�����е��������͡���ʹ����洢����֧��ijһ��������,���ǵ�ʵ�ֺ���ΪҲ�����������
B+Tree����
MyISAM �� InnoDB �洢����,��ʹ�� B+Tree�����ݽṹ,������� B-Tree�ṹ,���е����ݶ������Ҷ�ӽڵ���,�Ұ�Ҷ�ӽڵ�ͨ��ָ�����ӵ�һ��,�γ���һ����������,�Լӿ��������ݵļ���Ч�ʡ�
���˽��� B-Tree �� B+Tree ������
B-Tree
B-Tree��Ϊ���̵���洢�豸��Ƶ�һ��ƽ���������
ϵͳ�Ӵ��̶�ȡ���ݵ��ڴ�ʱ���Դ��̿�(block)Ϊ������λ��,λ��ͬһ�����̿��е����ݻᱻһ���Զ�ȡ����,��������Ҫʲôȡʲô��
InnoDB �洢��������ҳ(Page)�ĸ���,ҳ������̹�������С��λ��InnoDB �洢������Ĭ��ÿ��ҳ�Ĵ�СΪ16KB,��ͨ������ innodb_page_size ��ҳ�Ĵ�С����Ϊ 4K��8K��16K,�� MySQL �п�ͨ����������鿴ҳ�Ĵ�С:show variables like 'innodb_page_size';
��ϵͳһ�����̿�Ĵ洢�ռ�����û����ô��,��� InnoDB ÿ��������̿ռ�ʱ���������ɵ�ַ�������̿����ﵽҳ�Ĵ�С 16KB��InnoDB �ڰѴ������ݶ��뵽����ʱ����ҳΪ������λ,�ڲ�ѯ����ʱ���һ��ҳ�е�ÿ�����ݶ��������ڶ�λ���ݼ�¼��λ��,�⽫����ٴ���I/O����,��߲�ѯЧ�ʡ�
B-Tree �ṹ�����ݿ�����ϵͳ��Ч���ҵ��������ڵĴ��̿顣Ϊ������ B-Tree,���ȶ���һ����¼Ϊһ����Ԫ��[key, data] ,keyΪ��¼�ļ�ֵ,��Ӧ���е�����ֵ,data Ϊһ�м�¼�г�����������ݡ����ڲ�ͬ�ļ�¼,keyֵ������ͬ��
һ��m��B-Tree����������:
- ÿ���ڵ������m������
- ���˸��ڵ��Ҷ�ӽڵ���,����ÿ���ڵ�������Ceil(m/2)�����ӡ�
- �����ڵ㲻��Ҷ�ӽڵ�,��������2������
- ����Ҷ�ӽڵ㶼��ͬһ��,�Ҳ����������ؼ�����Ϣ
- ÿ�����ն˽ڵ����n���ؼ�����Ϣ(P0,P1,��Pn, k1,��kn)
- �ؼ��ֵĸ���n����:ceil(m/2)-1 <= n <= m-1
- ki(i=1,��n)Ϊ�ؼ���,�ҹؼ�����������
- Pi(i=1,��n)Ϊָ���������ڵ��ָ�롣P(i-1)ָ������������нڵ�ؼ��־�С��ki,��������k(i-1)
B-Tree �е�ÿ���ڵ����ʵ����������������Ĺؼ�����Ϣ�ͷ�֧,����ͼ��ʾΪһ�� 3 �� B-Tree:
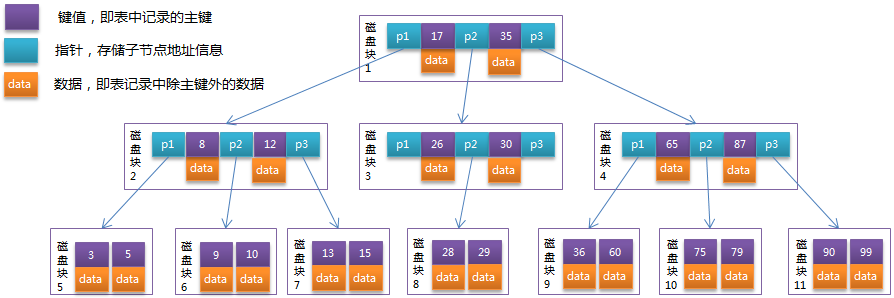 ����
����
ÿ���ڵ�ռ��һ���̿�Ĵ��̿ռ�,һ���ڵ�����������������Ĺؼ��ֺ�����ָ���������ڵ��ָ��,ָ��洢�����ӽڵ����ڴ��̿�ĵ�ַ�������ؼ��ʻ��ֳɵ�������Χ���Ӧ����ָ��ָ������������ݵķ�Χ���Ը��ڵ�Ϊ��,�ؼ���Ϊ17��35,P1ָ��ָ������������ݷ�ΧΪС��17,P2ָ��ָ������������ݷ�ΧΪ17~35,P3ָ��ָ������������ݷ�ΧΪ����35��
ģ����ҹؼ���29�Ĺ���:
- ���ݸ��ڵ��ҵ����̿�1,�����ڴ档������I/O������1�Ρ�
- �ȽϹؼ���29������(17,35),�ҵ����̿�1��ָ��P2��
- ����P2ָ���ҵ����̿�3,�����ڴ档������I/O������2�Ρ�
- �ȽϹؼ���29������(26,30),�ҵ����̿�3��ָ��P2��
- ����P2ָ���ҵ����̿�8,�����ڴ档������I/O������3�Ρ�
- �ڴ��̿�8�еĹؼ����б����ҵ��ؼ���29��
�����������,������Ҫ3�δ���I/O����,��3���ڴ���Ҳ����������ڴ��еĹؼ�����һ��������ṹ,�������ö��ַ��������Ч�ʡ���3�δ���I/O������Ӱ������B-Tree����Ч�ʵľ������ء�B-Tree�����AVLTree�����˽ڵ����,ʹÿ�δ���I/Oȡ���ڴ�����ݶ�����������,�Ӷ�����˲�ѯЧ�ʡ�
B+Tree
B+Tree ���� B-Tree �����ϵ�һ���Ż�,ʹ����ʺ�ʵ����洢�����ṹ,InnoDB �洢��������� B+Tree ʵ���������ṹ��
����һ���е�B-Tree�ṹͼ�п��Կ���ÿ���ڵ��в����������ݵ�keyֵ,����dataֵ����ÿһ��ҳ�Ĵ洢�ռ�������,���data���ݽϴ�ʱ���ᵼ��ÿ���ڵ�(��һ��ҳ)�ܴ洢��key��������С,���洢���������ܴ�ʱͬ���ᵼ��B-Tree����Ƚϴ�,�����ѯʱ�Ĵ���I/O����,����Ӱ���ѯЧ�ʡ���B+Tree��,�������ݼ�¼�ڵ㶼�ǰ��ռ�ֵ��С˳������ͬһ���Ҷ�ӽڵ���,����Ҷ�ӽڵ���ֻ�洢keyֵ��Ϣ,�������Դ��Ӵ�ÿ���ڵ�洢��keyֵ����,����B+Tree�ĸ߶ȡ�
B+Tree�����B-Tree�м��㲻ͬ:
- ��Ҷ�ӽڵ�ֻ�洢��ֵ��Ϣ;
- ����Ҷ�ӽڵ�֮�䶼��һ����ָ��;
- ���ݼ�¼�������Ҷ�ӽڵ���
����һ���е�B-Tree�Ż�,����B+Tree�ķ�Ҷ�ӽڵ�ֻ�洢��ֵ��Ϣ,����ÿ�����̿��ܴ洢4����ֵ��ָ����Ϣ,����B+Tree����ṹ����ͼ��ʾ: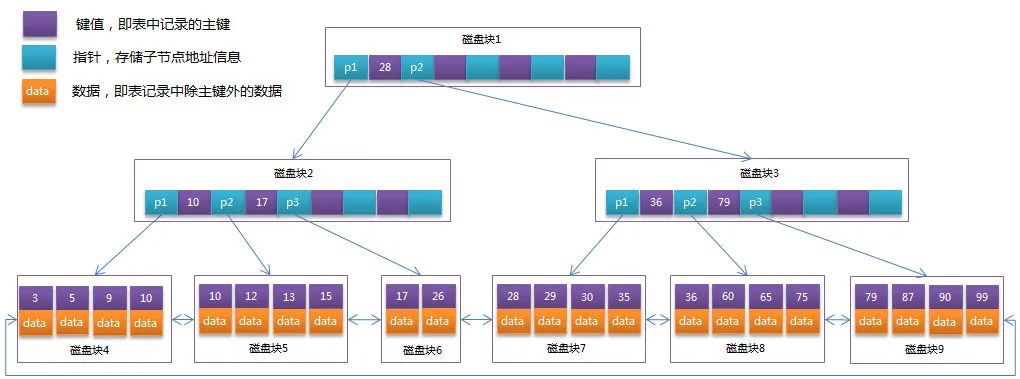
ͨ����B+Tree��������ͷָ��,һ��ָ����ڵ�,��һ��ָ��ؼ�����С��Ҷ�ӽڵ�,��������Ҷ�ӽڵ�(�����ݽڵ�)֮����һ����ʽ���ṹ����˿��Զ�B+Tree�������ֲ�������:һ���Ƕ��������ķ�Χ���Һͷ�ҳ����,��һ���ǴӸ��ڵ㿪ʼ,����������ҡ�
��������������ֻ��22�����ݼ�¼,������B+Tree���ŵ�,������һ������:
InnoDB�洢������ҳ�Ĵ�СΪ16KB,һ�������������ΪINT(ռ��4���ֽ�)��BIGINT(ռ��8���ֽ�),ָ������Ҳһ��Ϊ4��8���ֽ�,Ҳ����˵һ��ҳ(B+Tree�е�һ���ڵ�)�д�Ŵ洢16KB/(8B+8B)=1K����ֵ(��Ϊ�ǹ�ֵ,Ϊ�������,�����KȡֵΪ103)��Ҳ����˵һ�����Ϊ3��B+Tree��������ά��103 * 10^3 * 10^3 = 10�� ����¼��
ʵ�������ÿ���ڵ���ܲ��������,��������ݿ���,B+Tree�ĸ߶�һ�㶼��2-4�㡣MySQL��InnoDB�洢���������ʱ�ǽ����ڵ㳣פ�ڴ��,Ҳ����˵����ijһ��ֵ���м�¼ʱ���ֻ��Ҫ1~3�δ���I/O������
B+Tree����
- ͨ������ķ���,����֪��IO����ȡ����b+���ĸ߶�h,���赱ǰ���ݱ�������ΪN,ÿ�����̿���������������m,����h=�S(m+1)N,��������Nһ���������,mԽ��,hԽС;��m = ���̿�Ĵ�С / ������Ĵ�С,���̿�Ĵ�СҲ����һ������ҳ�Ĵ�С,�ǹ̶���,���������ռ�Ŀռ�ԽС,�����������Խ��,���ĸ߶�Խ�͡������Ϊʲôÿ��������,�������ֶ�Ҫ������С,����intռ4�ֽ�,Ҫ��bigint8�ֽ���һ�롣��Ҳ��Ϊʲôb+��Ҫ�����ʵ�����ݷŵ�Ҷ�ӽڵ�������ڲ�ڵ�,һ���ŵ��ڲ�ڵ�,���̿��������������½�,���������ߡ������������1ʱ�����˻������Ա���
- ��b+�����������Ǹ��ϵ����ݽṹ,����(name,age,sex)��ʱ��,b+���ǰ��մ����ҵ�˳����������������,���統(����,20,F)������������������ʱ��,b+�������ȱȽ�name��ȷ����һ�������ѷ���,���name��ͬ�����αȽ�age��sex,���õ�����������;����(20,F)������û��name����������ʱ��,b+���Ͳ�֪����һ���ò��ĸ��ڵ�,��Ϊ������������ʱ��name���ǵ�һ���Ƚ�����,����Ҫ�ȸ���name����������֪����һ��ȥ�����ѯ�����統(����,F)����������������ʱ,b+��������name��ָ����������,����һ���ֶ�age��ȱʧ,����ֻ�ܰ����ֵ������������ݶ��ҵ�,Ȼ����ƥ���Ա���F��������, ����Ƿdz���Ҫ������,������������ƥ��������
MyISAM���������븨�������Ľṹ
MyISAM����������ļ��������ļ��Ƿ���ġ�MyISAM���������ṹ��Ҷ�ӽڵ��������,��ŵIJ�����ʵ�ʵ����ݼ�¼,�������ݼ�¼�ĵ�ַ�������ļ��������ļ�����,������������Ϊ"�Ǿ۴�����"��MyISAM���������븨������������,ֻ�����������������ظ��Ĺؼ��֡�
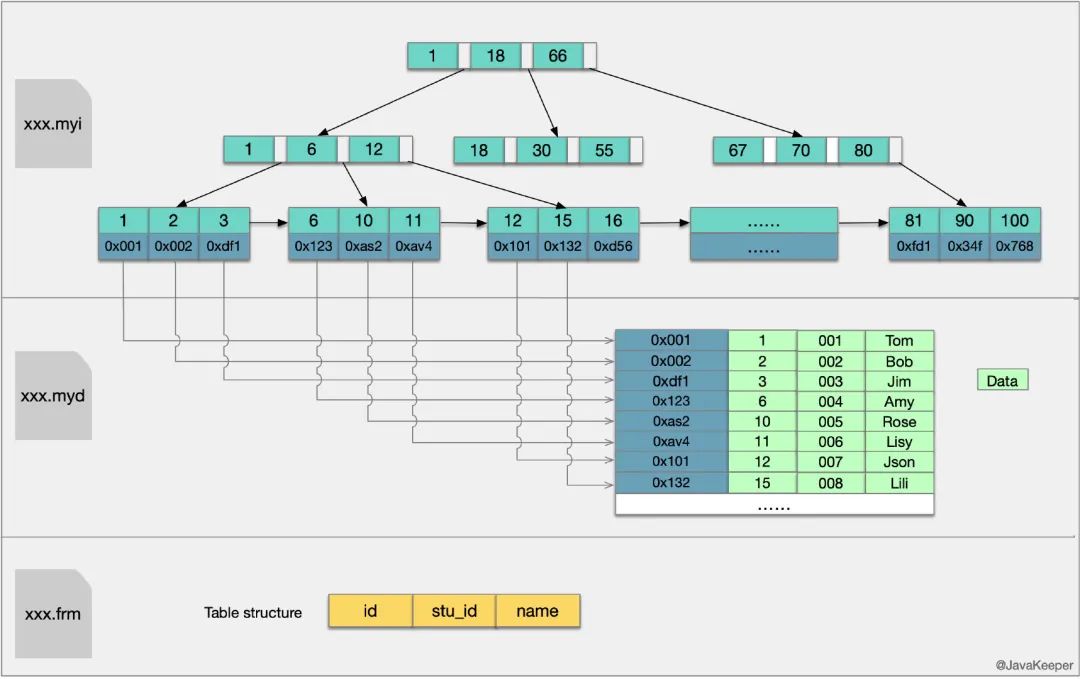
��MyISAM��,����(��Ҷ�ӽڵ�)����ڵ�����.myi�ļ���,Ҷ�ӽڵ��ŵ������ݵ�������ַƫ����(ͨ��ƫ�������ʾ����������,�ٶȺܿ�)��
��������ָ��������,��ֵ�������ظ�;��������������ͨ����,��ֵ�����ظ���
ͨ�������������ݵ�����:�ȴ������ļ��в��ҵ������ڵ�,�����õ����ݵ��ļ�ָ��,�ٵ������ļ���ͨ���ļ�ָ�붨λ�˾�������ݡ������������ơ�
InnoDB���������븨�������Ľṹ
InnoDB���������ṹ��Ҷ�ӽڵ��������,��ŵľ���ʵ�ʵ����ݼ�¼(����������,�˴����ű������е����ݼ�¼;���ڸ��������˴�����������,������ʱ��ͨ�������������������ҵ���Ӧ������),����˵,InnoDB�������ļ������������������ļ�,��������������Ϊ���۴�������,һ����ֻ����һ���۴�������
��������:
����֪��InnoDB�����Ǿۼ�����,���������������Ǵ���ͬһ��.idb�ļ��е�,������������ṹ����ͬһ�����ڵ���ͬʱ�������������,����ͼ����ײ��Ҷ�ӽڵ�����������,��Ӧ�����ݱ��е�id��stu_id��name�����
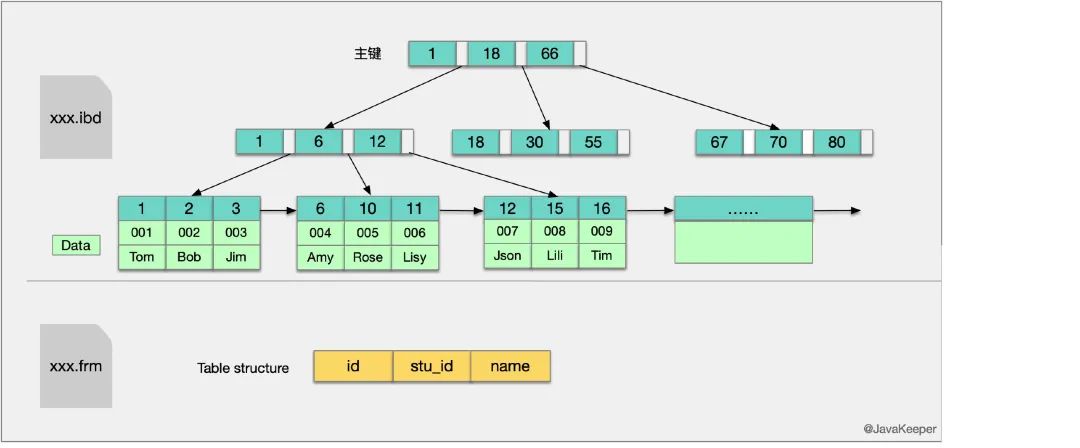
��Innodb��,������Ҷ�ӽڵ�ͷ�Ҷ�ӽڵ�,��Ҷ�ӽڵ�����»��ֵ��Ŀ¼,�����������������,Ҷ�ӽڵ�����˳�����е�,�����ݶ��С�Innodb�������ļ������ձ����з�(ֻ��Ҫ����innodb_file_per_table),�зֺ�����xxx.ibd��,Ĭ�ϲ��з�,�����xxx.ibdata�С�
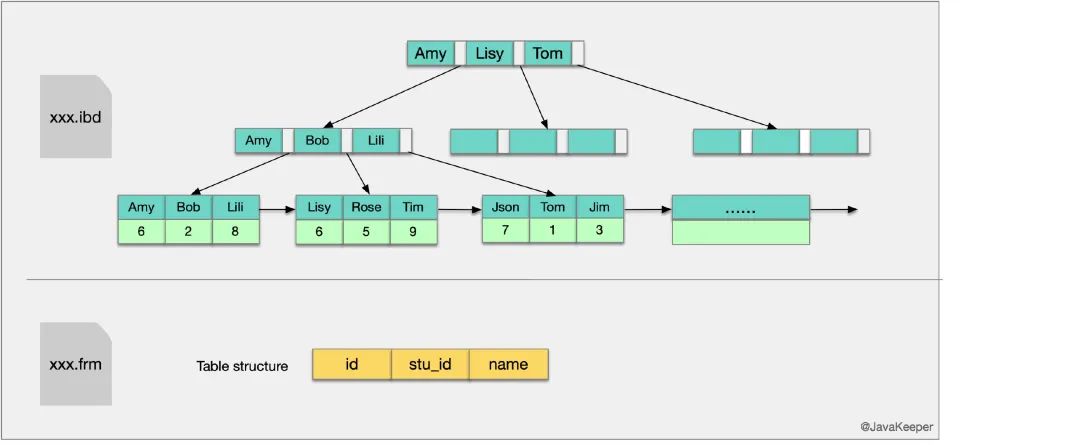
����(������)����:
���������ʾ����ѧ�����е�name�н�����������,���������ṹ�����������Ľṹ�кܴ���,����ײ��Ҷ�ӽ������������,��һ�е��ַ����Ǹ�������,����ASCII���������,�ڶ��е�������������ֵ��
�����ζ��,��name�н�����������,��Ҫ��������:
�� �ڸ��������ϼ���name,������Ҷ�ӽڵ��ȡ��Ӧ������;
�� ʹ�����������������ٽ��ж�Ӧ�ļ�������
��Ҳ������ν�ġ��ر���ѯ��
InnoDB �����ṹ��Ҫע��ĵ�
- �����ļ��������������ļ�
- �������ļ��������ǰ� B+Tree ��֯��һ�������ṹ�ļ�
- �ۼ�������Ҷ�ڵ���������������ݼ�¼
- InnoDB ������Ҫ������,�����Ƽ�ʹ��������������
��������������� InnoDB �洢�ṹ,�����������ǹ�ͬ�洢��,�����������������Ǹ�������,�ڲ���ʱ����ͨ���Ȳ��ҵ������ڵ�����õ����Ӧ������,�����������Ʊ��ṹʱû����ʽָ�������еĻ�,MySQL ��ӱ���ѡ�����ݲ��ظ����н�������,���û�з��ϵ���,�� MySQL �Զ�Ϊ InnoDB ������һ�������ֶ���Ϊ����,��������ֶγ���Ϊ6���ֽ�,����Ϊ���͡�
?
��Ϊʲô�Ƽ�ʹ��������������������ѡ��UUID?
- UUID���ַ���,���������ĸ���Ĵ洢�ռ�;
- ��B+���н��в���ʱ��Ҫ�������Ľڵ�ֵ�Ƚϴ�С,�������ݵıȽ�������ַ���������;
- ���������������ڴ����л������洢,�ڶ�ȡһҳ����ʱҲ������;UUID�����������,��ȡ�������������ݴ洢�Ƿ�ɢ��,���ʺ�ִ��where id > 5 && id < 20��������ѯ��䡣
- �ڲ����ɾ������ʱ,����������������Ҷ�ӽ���ĩβ�����µ�Ҷ�ӽڵ�,�����ƻ���������Ľṹ;UUID���������׳������������,B+��Ϊ��ά������������,�п��ܻ���нṹ���ع�,���ĸ����ʱ�䡣
?
Ϊʲô�����������ṹҶ�ӽڵ�洢��������ֵ?
��֤����һ���Ժͽ�ʡ�洢�ռ�,������ô����:�̳�ϵͳ��������洢һ���û�ID��Ϊ�������,�����Ƽ��洢�������û���Ϣ,��Ϊ�������û����е���Ϣ(��ʵ���ơ��ֻ��š��ջ���ַ������)�ĺ�,����Ҫ�ٴ�ά�����������û�����,ͬʱҲ��ʡ�˴洢�ռ䡣
Hash����
-
��Ҫ����ͨ��Hash�㷨(������Hash�㷨��ֱ�Ӷ�ַ����ƽ��ȡ�з����۵���������ȡ�෨���������),�����ݿ��ֶ�����ת���ɶ�����Hashֵ,���������ݵ���ָ��һ������Hash���Ķ�Ӧλ��;�������Hash��ײ(������ͬ�ؼ��ֵ�Hashֵ��ͬ),���ڶ�ӦHash������������ʽ�洢��
�����㷨:�ڼ�����ѯʱ,���ٴζԴ���ؼ����ٴ�ִ����ͬ��Hash�㷨,�õ�Hashֵ,����ӦHash����Ӧλ��ȡ�����ݼ���,�������Hash��ײ,����Ҫ��ȡֵʱ����ɸѡ��Ŀǰʹ��Hash���������ݿⲢ����,��Ҫ��Memory�ȡ�
MySQLĿǰ��Memory�����NDB����֧��Hash������
full-textȫ������
- ȫ������Ҳ��MyISAM��һ��������������,��Ҫ����ȫ������,InnoDB��MYSQL5.6�汾�ṩ��ȫ��������֧�֡�
- ���������Ч�ʽϵ͵�LIKEģ��ƥ�����,���ҿ���ͨ�����ֶ���ϵ�ȫ������һ����ȫģ��ƥ�����ֶΡ�
- ͬ��ʹ��B-Tree�����������,��ʹ�õ����ض����㷨,���ֶ����ݷָ���ٽ�������(һ��ÿ4���ֽ�һ�ηָ�),�����ļ��洢���Ƿָ�ǰ�������ַ�������,��ָ���������Ϣ,��ӦBtree�ṹ�Ľڵ�洢���Ƿָ��Ĵ���Ϣ�Լ����ڷָ�ǰ�������ַ��������е�λ�á�
R-Tree�ռ�����
�ռ�������MyISAM��һ��������������,��Ҫ���ڵ����ռ���������
?
ΪʲôMysql����Ҫ��B+������B��?
��B+������B�����ǵ���IO�����ܵ�Ӱ��,B����ÿ���ڵ㶼�洢����,��B+��ֻ��Ҷ�ӽڵ�Ŵ洢����,���Բ�����ͬ�������������,B���ĸ߶ȸ���,IO��Ƶ�������ݿ������Ǵ洢�ڴ����ϵ�,����������ʱ,�Ͳ��ܰ���������ȫ�����ص��ڴ���,ֻ����һ����ÿһ������ҳ(��Ӧ�������Ľڵ�)��������MySQL�ײ��B+�����н�һ���Ż�:��Ҷ�ӽڵ�����˫������,����������ͷ����β�ڵ�Ҳ��ѭ��ָ��ġ�