��д�����¿�ʼ֮ǰ�Ҹ����˵��,���ݸ���ѧ�������¼�ıʼ�,�����ʲô������Թ�ע����ϵ����һ�����ۡ����˻��ǽ����Ҷ��ѧϰ��ϵ�ļ��������Ͳ��ὲ��̫ϸ��
1��һ�㶼ʹ�� INNODB �洢����,���Ƕ�д���� < 1%, �ſ���ʹ�� MYISAM �洢����;�����洢�������� DBA �Ľ�����ʹ�á�
2��Stored procedure (�����洢����,����,������) ���� MYSQL ��˵�����Ǻܳ���,û�����Ƶij�����¼����,������ʹ�á�
3��UUID (),USER () ������ MySQL INSIDE �������ڸ�����˵�Ǻ�Σ�յ�,�ᵼ���������ݲ�һ��,�����벻Ҫʹ�á����һ��Ҫʹ�� UUID ��Ϊ����,��Ӧ�ó�����������
4���벻Ҫʹ�����Լ��,������ݴ��������ϵ,���ڳ������ʵ�֡�
5��ѡ����ʵ��ַ���,�� emoji ʹ�� utf8,�� emoji ʹ�� utf8mb4��
6. ѡ����ʵ����͡�
7. ������ɾ��,����,��ʱ�䡣
8. ���ӱ�,�ֶ�ע��
9. ����ʹ�� bigint (20),���������һ�¡�
10. ���ӱ�,�ֶ�ע��
11. ��������
��һ��ʽ:Ҫ��������,����Ҫ��ÿһ���ֶ�ԭ���Բ����ٷ�
�ڶ���ʽ:Ҫ�����з������ֶ���ȫ��������,���ܲ�����������
������ʽ:���з������ֶκ������ֶ�֮�䲻�ܲ�����������
����ʽ��:ָ����ͨ������������ظ���������������ݿ�Ķ����ܡ�
MySQL ����
�������ڿ����ҳ���ij��������һ�ض�ֵ����,��ʹ������,MySQL ����ӵ�һ����¼��ʼ����������,ֱ���ҳ���ص���,��Խ��,��ѯ���������ѵ�ʱ���Խ��,������в�ѯ������һ������,MySQL �ܹ����ٵ���һ��λ��ȥ���������ļ�,�����ز鿴��������,��ô�����ʡ�ܴ�һ����ʱ�䡣
MySQL ���������ŵ��ȱ���ʹ��ԭ��
�ŵ�:
1�����е� MySql ������ (�ֶ�����) �����Ա�����,Ҳ���ǿ��Ը������ֶ���������
2�����ӿ����ݵIJ�ѯ�ٶ�
ȱ��:
1������������ά������Ҫ�ķ�ʱ��,�����������������������ķѵ�ʱ��Ҳ������
2������Ҳ��Ҫռ�ռ�,����֪�����ݱ��е�����Ҳ��������������õ�,��������д���������,�����ļ����ܻ�������ļ�����ﵽ����ֵ
3�����Ա��е����ݽ������ӡ�ɾ������ʱ,����Ҳ��Ҫ��̬��ά��,���������ݵ�ά���ٶȡ�
ʹ��ԭ��:
ͨ������˵���ŵ��ȱ��,����Ӧ�ÿ���֪��,������ÿ���ֶζ����������ͺ�,Ҳ��������Խ��Խ��,������Ҫ�Լ�������ʹ�á�
1���Ծ������µı��ͱ��������й��������,�Ծ������ڲ�ѯ���ֶ�Ӧ�ô�������,
2��������С�ı���ò�Ҫʹ������,��Ϊ�������ݽ���,���ܲ�ѯȫ�����ݻ��ѵ�ʱ��ȱ���������ʱ�仹Ҫ��,�����Ϳ��ܲ�������Ż�Ч����
3����һֵͬ�ٵ����� (�ֶ���) ��Ҫ��������,������ѧ�����ġ� �Ա� �ֶ���ֻ����,Ů������ֵͬ���෴��,��һ���ֶ��ϲ�ֵͬ�϶���Խ���������
�����ķ���
ע��:�������ڴ洢������ʵ�ֵ�,Ҳ����˵��ͬ�Ĵ洢����,��ʹ�ò�ͬ������
MyISAM �� InnoDB �洢����:ֻ֧�� BTREE ����, Ҳ����˵Ĭ��ʹ BTREE,���ܹ�������
MEMORY/HEAP �洢����:֧�� HASH �� BTREE ������
�������Ƿ�Ϊ�������� �������� (��ͨ����,Ψһ����,��������)�����������ȫ���������ռ�������
- ��������:һ������ֻ����������,��һ�����п����ж������������ ���ﲻҪ������ˡ�
��ͨ����:MySQL �л�����������,û��ʲô����,�����ڶ������������в����ظ�ֵ�Ϳ�ֵ,����Ϊ�˲�ѯ���ݸ���һ�㡣
Ψһ����:�������е�ֵ������Ψһ��,��������Ϊ��ֵ,
��������:��һ�������Ψһ����,�������п�ֵ��
- �������
�ڱ��еĶ���ֶ�����ϴ���������,ֻ���ڲ�ѯ������ʹ������Щ�ֶε�����ֶ�ʱ,�����Żᱻʹ��,ʹ���������ʱ��ѭ����ǰ���ϡ���������������,�Ⱥ����������ʱ��ϸ˵
- ȫ������
ȫ������,ֻ���� MyISAM �����ϲ���ʹ��,ֻ���� CHAR,VARCHAR,TEXT �����ֶ���ʹ��ȫ������,������Ҫ��,˵˵ʲô��ȫ������,������һ��������,ͨ�����е�ij���ؼ��ֵ�,�����ҵ����ֶ������ļ�¼��,�����С� ���Ǹ�����,��Ů ���� ͨ������,���ܾͿ����ҵ�������¼������˵���ǿ���,��Ϊȫ��������ʹ���漰�˺ܶ�ϸ��,����ֻ��Ҫ֪����������˼��
- �ռ�����
�ռ������ǶԿռ��������͵��ֶν���������,MySQL �еĿռ���������������,GEOMETRY��POINT��LINESTRING��POLYGON���ڴ����ռ�����ʱ,ʹ�� SPATIAL �ؼ��֡�Ҫ��,����Ϊ MyISAM,�����ռ���������,���뽫������Ϊ NOT NULL��
�����Ż�
1)��� MySQL ����ʹ��������ȫ��ɨ�軹��,��ʹ��������
2)ǰ��ģ����ѯ��������������
ǰ��ģ����ѯ������������:
SELECT * FROM user WHERE name LIKE ��%s%��;
3)�������ͳ�����ʽת����ʱ����������,�ر��ǵ����������ַ���,һ��Ҫ���ַ�����ֵ��������������
4)���������������,��ѯ��������������������߲���(����������ԭ��),�������з���������
5)union��in��or ���ܹ���������,����ʹ�� in��
6)�� or �ָ������,��� or ǰ����������������,�����������û������,��ô�漰�������������ᱻ�õ���
7)����������ѯ����ʹ������,�����Ż�Ϊ in ��ѯ������������:!=��<>��not in��not exists��not like �ȡ�
8)��Χ������ѯ����������������Χ������:<��<=��>��>=��between �ȡ�
9)���ݿ�ִ�м��㲻������������
10)���ø����������в�ѯ,����ر���
11)������������,������Ϊ null��
a. ����ʮ��Ƶ�����ֶ��ϲ��˽�������:��Ϊ���²������� B + ��,�ؽ����������������ʮ���������ݿ����ܵġ�
b. ���ֶȲ�����ֶ��ϲ��˽�������:�������Ա��������ֶȲ�����ֶ�,�������������岻����Ϊ������Ч��������,���ܺ�ȫ��ɨ���൱�����ⷵ�����ݵı����� 30% ����������,�Ż�������ѡ��ʹ��������
c. ҵ���Ͼ���Ψһ���Ե��ֶ�,��ʹ�Ƕ���ֶε����,Ҳ���뽨��Ψһ��������ȻΨһ������Ӱ�� insert �ٶ�,���Ƕ��ڲ�ѯ���ٶ������Ƿdz����Եġ�����,��ʹ��Ӧ�ò����˷dz����Ƶ�У�����,ֻҪû��Ψһ����,�ڲ����������,��Ȼ�������ݲ�����
d. �������ʱ,Ҫ��֤�����ֶ���һ����������
e. ��������ʱ�������´������:����Խ��Խ��,��Ϊһ����ѯ����Ҫ��һ������;��ȱ����,��Ϊ���������Ŀռ䡢�����������º������ٶ�;����Ψһ����,��Ϊҵ���Ψһ��һ����Ҫ��Ӧ�ò�ͨ�� ���Ȳ��塱 ��ʽ���;�����Ż�,�ڲ��˽�ϵͳ������¾Ϳ�ʼ�Ż���
MySQL �еĴ洢����
�� MySQL 5.7 �汾��,MySQL ֧�ֵĴ洢������:
1��InnoDB
2��MyISAM
3��Memory
4��CSV
5��Archive
6��Blackhole
7��Merge:
8��Federated
9��Example
InnoDB:֧��������� (�� begin, commit,rollback ����),֧���м���,�м�������ڱ���,�����ȸ�ϸ,��������������,InnoDB �洢����Ҳ�� MySQL 5.7 �汾��Ĭ�ϵĴ洢���档��ȱ����:�洢�ռ��ռ�ñȽϴ�
MyISAM:�ô洢����洢ռ�õĿռ������ InnoDB �洢������˵���ٺܶ�,����֧�ֵ�Ϊ����,�䲢�����ܻ�ͺܶ�,���Ҳ�֧������,ͨ��ֻӦ����ֻ��ģʽ��Ӧ�á����� MySQL ��ԭʼ�Ĵ洢���档
Memory:�ô洢���������ص���,�������ݾ��������ڴ���,֮ǰ���и����ֽ��� ��Heap����
Ӧ�ó���:��Ҫ�洢һЩ��Ҫ���ٷ��ҷǹؼ�����,Ϊʲô���ǹؼ�������?����Ϊ���������ݱ������ڴ���,Ҳ��������Ϊ����ȫ��
CSV:��������ʶһ�� CSV,CSV �ļ���ʵ�����ö��ŷָ������ı��ļ�,����������ת��,������ƽʱ�õıȽ���,��֧��������
Archive:�浵�ļ�,��Ҫ���ڴ洢�����õ��������ļ�,
Example:�ô洢������Ҫ����չʾ������б�дһ���洢����,һ�㲻��������������ʹ�á�
mysql ����
������ 1000 ��Ǯ,����Ҳ�� 1000 ��Ǯ,���������� 500, ��ʣ�� 500,���Ĵ�ʱ���� 1500�����������Ż�ִ������� mysql ���:
update table user set money=500 where name = ��������;
update table user set money=1500 where name = �����ġ�;
�����ڼ�����п��ܻһ���������������ִ���������û��ִ��,���Ϊ�˱�֤�������Ҫô��ִ��,Ҫô����ִ��,��ʱ����õ�������
�������˼��һ��������һ��������һ����Ԫ,�����ԪҪôȫ��ִ��,Ҫôȫ��ִ�С�
��������ĸ�����,Ҳ�����Գ������ĸ����� ACID:
A(ԭ���� Atomicity):ԭ����ָ����������һ�����ɷָ��,Ҫô��ִ��Ҫô����ִ�С�
C(һ���� Consistency):�������ʹ�����ݿ��һ��һ����״̬,������һ��һ����״̬��
I(������ Isolation):ָ����һ�������ִ��,���ܱ����������������š�
D(�־��� Durability):�־���ָ����һ������һ���ύ��֮��,�����ݿ�ĸı�������õġ�
��������������
���Ҫ����ϵͳ��������,���ж��������Ҫ����ʱ,Ӧ���ö������ͬʱִ��,���������IJ�������Ȼ������ڲ���ִ��,�DZ�Ȼ����ͬһ�����ݲ���ʱ�ij�ͻ����
���¶�ʧ(Lost Update),�������������ͬһ������ʱ,˫������֪���Է��Ĵ���,���п��ܸ��ǶԷ����ġ�����������ͬʱ�༭һ���ĵ�,���һ����������ܻḲ�ǵ�ǰ���Ǹ��˵ĸĶ���
���(Dirty Reads),һ��������ִ��ʱ����ij������,��һ����������Ҳ��ȡ����������,��������������������������,��Ϊǰһ������û�ύ,��������ĺ�����ݽ�һ������,�ͻ��������ص���ʧ��
�����ظ���(Non-Repeatable Reads),ͬ�������������ڲ���ͬһ����,���������ʼʱ����ij����,��ʱ����һ������������������,��������ȥ���������ݵ�ʱ�����Ѿ�����,�����û�취�ظ���һ�����ݡ�
�ö�(Phantom Read),���Ϸ�������ͬ,����һ��ʼ��ij����ѯ����û����κ�����,�����Ϊ��һ�������Ӱ��,��ȥ��ʱȴ�鵽������,���־�������þ���һ��,�������ö���
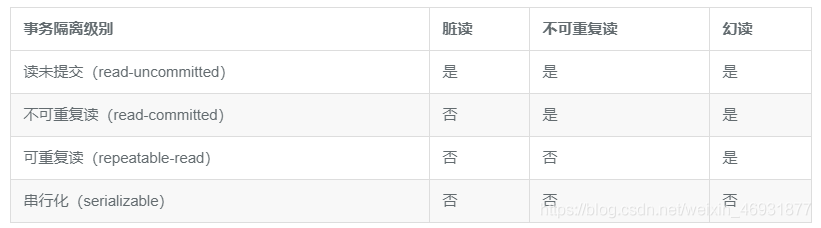
��������ָ��뼶��
��δ�ύ (Read uncommitted),��δ�ύ��ʵ��������û�ύ�Ϳ��Զ�,����Ȼ���ָ��뼶��ᵼ�¶�����Ļ�û�ύ������,һ�����ڶ������������˽�һ������,����һ���������ջع��˲���,��ô���ݾͻ����,���Һ����١��ܵ���˵˵,��δ�ύ����ᵼ�������
���ύ (Read committed),����˼����������ύ����ܶ�,�������������п�ȥ����,��Ǯ֮ǰ�㿴�������� 2000 Ԫ,���ʱ�����������Ա�����,������ǰ�������֧��,���ʱ������֧����ʱ�����ʾ����,���Ƿ����㿴�������Ǯ�ǹ��İ������������������ִ��ʱ,���� A һ��ʼ��ȡ�˿����� 2000 Ԫ,���ʱ������ B �ѿ����Ǯ������,���� A ������ȷ������ʱ���ֿ����Ѿ�û��Ǯ�ˡ�����Ȼ,���ύ�ܽ���������,���ǽ�����˲����ظ�����
Sql Server,Oracle ��Ĭ�ϸ��뼶���� Read committed��
���ظ���( Repeatable read),�����־Ϳ�������,���ij��־���Ϊ�˽�������ظ�������,���� A һ����ʼִ��,�������� B ��ô������,���� A ��Զ�����ľ������տ�ʼ����ֵ����ô���������,�������� B �� id Ϊ 1 �����ݸij��� 2,���� A ����֪�� id �����˱仯,������ A �������ݵ�ʱ��ȴ����Ϊ 2 �� id �Ѿ�������,����ǻö���
MySQL ��Ĭ�ϸ��뼶����� Repeatable read��
���л�( serializable),����������еĴ�����,���е���������һ����ִ��,��Ϊû�в����ij���������,ʲô�ö�������������ظ���ͳͳ�������ڵġ�����ͬ����,��������������dz������,����ʲô���뼶����ȫҪ�����Լ���ҵ��ѡ��,û����õ�,ֻ�����ʺϵġ�
1��������뼶��Ϊ���ύʱ,д����ֻ����ס��Ӧ����
2��������뼶��Ϊ���ظ���ʱ,�����������������(������������)��ʱ��,Ĭ�ϼ�����ʽ�� next-key ��;�����������û������,��������ʱ����ס���ű���һ����϶�����������,���������Dz����������϶�����¼��,�������Է�ֹ�ö���****
3��������뼶��Ϊ���л�ʱ,��д���ݶ�����ס���ű�
4�����뼶��Խ��,Խ�ܱ�֤���ݵ������Ժ�һ����,���ǶԲ������ܵ�Ӱ��ҲԽ��
sql ���
һ������
1���������ݿ�
CREATE DATABASE database-name
2��ɾ�����ݿ�
drop database dbname
3������ sql server
�� ���� �������ݵ� device
USE master
EXEC sp_addumpdevice ��disk��, ��testBack��, ��c:mssql7backupMyNwind_1.dat��
�� ��ʼ ����
BACKUP DATABASE pubs TO testBack
4�������±�
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],��)
�������еı������±�:
A:create table tab_new like tab_old (ʹ�þɱ������±�)
B:create table tab_new as select col1,col2�� from tab_old definition only
5��ɾ���±�
drop table tabname
6������һ����
Alter table tabname add column col type ע:�����Ӻ���ɾ����DB2 ���м��Ϻ���������Ҳ���ܸı�,Ψһ�ܸı�������� varchar ���͵ij��ȡ�
7����������: Alter table tabname add primary key(col)
ɾ������: **Alter table tabname drop primary key (col)
8����������:create [unique] index idxname on tabname(col��.)
ɾ������:drop index idxname
ע:�����Dz��ɸ��ĵ�,����ı���ɾ�����½���
9��������ͼ:create view viewname as select statement
ɾ����ͼ:drop view viewname
10�������Ļ����� sql ���
ѡ��:select * from table1 where ��Χ
����:insert into table1(field1,field2) values(value1,value2)
ɾ��:delete from table1 where ��Χ����:update table1 set field1=value1 where ��Χ
����:select * from table1 where field1 like ��% value1%�� ��like ����ܾ���,������!
����:select * from table1 order by field1,field2 [desc]
����:select count as totalcount from table1
���:select sum(field1) as sumvalue from table1
ƽ��:select avg(field1) as avgvalue from table1
���:select max(field1) as maxvalue from table1
��С:select min(field1) as minvalue from table1
11����������ѯ�����
A: UNION �����
UNION �����ͨ������������������(���� TABLE1 �� TABLE2)����ȥ�����κ��ظ��ж�������һ����������� ALL �� UNION һ��ʹ��ʱ(�� UNION ALL),�������ظ��С����������,��������ÿһ�в������� TABLE1 �������� TABLE2��
B:EXCEPT �����
EXCEPT �����ͨ������������ TABLE1 �е����� TABLE2 �е��в����������ظ��ж�������һ����������� ALL �� EXCEPT һ��ʹ��ʱ (EXCEPT ALL),�������ظ��С�
C:INTERSECT �����
INTERSECT �����ͨ��ֻ���� TABLE1 �� TABLE2 �ж��е��в����������ظ��ж�������һ����������� ALL �� INTERSECT һ��ʹ��ʱ (INTERSECT ALL),�������ظ��С�
ע:ʹ������ʵļ�����ѯ����б�����һ�µġ�
12��ʹ��������
A��left (outer) join:
��������(������):��������������ӱ���ƥ����,Ҳ���������ӱ��������С�
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B:right (outer) join:
�������� (������):������Ȱ������ӱ���ƥ��������,Ҳ���������ӱ��������С�
C:full/cross (outer) join:
ȫ������:���������������ӱ���ƥ����,�������������ӱ��е����м�¼��
12������:Group by:
һ�ű�,һ������ ��ɺ�,��ѯ��ֻ�ܵõ�����ص���Ϣ��
����ص���Ϣ:(ͳ����Ϣ) count,sum,max,min,avg ����ı�)
�� SQLServer �з���ʱ:������ text,ntext,image ���͵��ֶ���Ϊ��������
�� selecte ͳ�ƺ����е��ֶ�,���ܺ���ͨ���ֶη���һ��;
13�������ݿ���в���:
�������ݿ�: sp_detach_db; �������ݿ�:sp_attach_db ��ӱ���,������Ҫ������·����
- ��������ݿ������:
sp_renamedb ��old_name��, ��new_name��
mysql �Ż�
1��ѡȡ�����õ��ֶ�����
MySQL ���Ժܺõ�֧�ִ��������Ĵ�ȡ,����һ��˵��,���ݿ��еı�ԽС,��������ִ�еIJ�ѯҲ�ͻ�Խ�졣���,�ڴ�������ʱ��,Ϊ�˻�ø��õ�����,���ǿ��Խ������ֶεĿ�����þ�����С��
����,�ڶ���������������ֶ�ʱ,�����������Ϊ CHAR (255), ��Ȼ�����ݿ������˲���Ҫ�Ŀռ�,����ʹ�� VARCHAR ��������Ҳ�Ƕ����,��Ϊ CHAR (6) �Ϳ��Ժܺõ���������ˡ�ͬ����,������ԵĻ�,����Ӧ��ʹ�� MEDIUMINT ������ BIGIN �����������ֶΡ�
����һ�����Ч�ʵķ������ڿ��ܵ������,Ӧ�þ������ֶ�����Ϊ NOTNULL,�����ڽ���ִ�в�ѯ��ʱ��,���ݿⲻ��ȥ�Ƚ� NULL ֵ��
����ijЩ�ı��ֶ�,���� ��ʡ�ݡ� ���� ���Ա�,���ǿ��Խ����Ƕ���Ϊ ENUM ���͡���Ϊ�� MySQL ��,ENUM ���ͱ�������ֵ������������,����ֵ�����ݱ������������ٶ�Ҫ���ı����Ϳ�öࡣ����,�����ֿ���������ݿ�����ܡ�
2��ʹ������(JOIN)�������Ӳ�ѯ (Sub-Queries)
MySQL �� 4.1 ��ʼ֧�� SQL ���Ӳ�ѯ�������������ʹ�� SELECT ���������һ�����еIJ�ѯ���,Ȼ�����������Ϊ��������������һ����ѯ�С�����,����Ҫ���ͻ�������Ϣ����û���κζ����Ŀͻ�ɾ����,�Ϳ��������Ӳ�ѯ�ȴ�������Ϣ���н����з��������Ŀͻ� ID ȡ����,Ȼ������ݸ�����ѯ,������ʾ:
DELETE FROM customerinfo
WHERE CustomerID NOT IN (SELECT CustomerID FROM salesinfo)
ʹ���Ӳ�ѯ����һ���Ե���ɺܶ�������Ҫ������������ɵ� SQL ����,ͬʱҲ���Ա���������߱�����,����д����Ҳ�����ס�����,��Щ�����,�Ӳ�ѯ���Ա�����Ч�ʵ�����(JOIN)�� ���������,��������Ҫ������û�ж�����¼���û�ȡ����,���������������ѯ���:
SELECT * FROM customerinfo
WHERE CustomerID NOT IN (SELECTC ustomerID FROM salesinfo)
���ʹ������(JOIN)�� ����������ѯ����,�ٶȽ����ܶࡣ�����ǵ� salesinfo ���ж� CustomerID ���������Ļ�,���ܽ������,��ѯ����:
SELECT * FROM customerinfo
LEFT JOIN salesinfo ON customerinfo.CustomerID=salesinfo.CustomerID
WHERE salesinfo.CustomerID ISNULL
����(JOIN)�� ֮���Ը���Ч��һЩ,����Ϊ MySQL ����Ҫ���ڴ��д�����ʱ�������������ϵ���Ҫ��������IJ�ѯ������
3��ʹ������ (UNION) �������ֶ���������ʱ��
MySQL �� 4.0 �İ汾��ʼ֧�� union ��ѯ,��������Ҫʹ����ʱ�������������� select ��ѯ�ϲ���һ����ѯ�С��ڿͻ��˵IJ�ѯ�Ự������ʱ��,��ʱ���ᱻ�Զ�ɾ��,�Ӷ���֤���ݿ����롢��Ч��ʹ�� union ��������ѯ��ʱ��,����ֻ��Ҫ�� UNION ��Ϊ�ؼ��ְѶ�� select ������������Ϳ�����,Ҫע��������� select ����е��ֶ���ĿҪ��ͬ����������Ӿ���ʾ��һ��ʹ�� UNION �IJ�ѯ��
SELECT Name,Phone FROM client UNION
SELECT Name,BirthDate FROM author UNION
SELECT Name,Supplier FROM product
4������
�������ǿ���ʹ���Ӳ�ѯ(Sub-Queries)������(JOIN)������(UNION)���������ָ����IJ�ѯ,���������е����ݿ����������ֻ��һ������������ SQL ���Ϳ�����ɵġ������ʱ������Ҫ�õ�һϵ�е���������ij�ֹ��������������������,����������е�ijһ��������г�����ʱ��,��������IJ����ͻ��ò�ȷ������������һ��,Ҫ��ij������ͬʱ��������������ı���,���ܻ�������������:��һ�����гɹ����º�,���ݿ�ͻȻ��������״��,��ɵڶ������еIJ���û�����,����,�ͻ�������ݵIJ�����,�������ƻ����ݿ��е����ݡ�Ҫ�����������,��Ӧ��ʹ������,����������:Ҫô������ÿ����䶼�����ɹ�,Ҫô��ʧ�ܡ����仰˵,���ǿ��Ա������ݿ������ݵ�һ���Ժ������ԡ������� BEGIN �ؼ��ֿ�ʼ,COMMIT �ؼ��ֽ���������֮���һ�� SQL ����ʧ��,��ô,ROLLBACK ����Ϳ������ݿ�ָ��� BEGIN ��ʼ֮ǰ��״̬��
BEGIN; INSERT INTO salesinfo SET CustomerID=14; UPDATE inventory SET Quantity=11 WHERE item='book'; COMMIT;
�������һ����Ҫ�����ǵ�����û�ͬʱʹ����ͬ������Դʱ,�����������������ݿ�ķ�����Ϊ�û��ṩһ�ְ�ȫ�ķ��ʷ�ʽ,�������Ա�֤�û��IJ��������������û������š�
5��������
����������ά�����ݿ������Ե�һ���dz��õķ���,��ȴ��Ϊ���Ķ�ռ��,��ʱ��Ӱ�����ݿ������,�������ںܴ��Ӧ��ϵͳ�С�����������ִ�еĹ�����,���ݿ⽫�ᱻ����,����������û�����ֻ����ʱ�ȴ�ֱ����������������һ�����ݿ�ϵͳֻ�����������û���ʹ��,������ɵ�Ӱ�첻���Ϊһ��̫�������;�������г�ǧ������û�ͬʱ����һ�����ݿ�ϵͳ,�������һ������������վ,�ͻ�����Ƚ����ص���Ӧ�ӳ١�
��ʵ,��Щ��������ǿ���ͨ���������ķ�������ø��õ����ܡ���������Ӿ����������ķ��������ǰ��һ������������Ĺ��ܡ�
LOCK TABLE inventory WRITE SELECT Quantity FROM inventory WHERE Item='book';
...
UPDATE inventory SET Quantity=11 WHERE Item='book'; UNLOCKTABLES
����,������һ�� select ���ȡ����ʼ����,ͨ��һЩ����,�� update ��佫��ֵ���µ����С������� WRITE �ؼ��ֵ� LOCKTABLE �����Ա�֤�� UNLOCKTABLES ���ִ��֮ǰ,�����������ķ������� inventory ���в��롢���»���ɾ���IJ�����
6��ʹ�����
�������ķ�������ά�����ݵ�������,������ȴ���ܱ�֤���ݵĹ����ԡ����ʱ�����ǾͿ���ʹ�������
����,������Ա�֤ÿһ�����ۼ�¼��ָ��ijһ�����ڵĿͻ���������,������� customerinfo ���е� CustomerID ӳ�䵽 salesinfo ���� CustomerID,�κ�һ��û�кϷ� CustomerID �ļ�¼�����ᱻ���»���뵽 salesinfo �С�
CREATE TABLE customerinfo( CustomerIDINT NOT NULL,PRIMARYKEY(CustomerID))TYPE=INNODB;
CREATE TABLE salesinfo( SalesIDNT NOT NULL,CustomerIDINT NOT NULL,
PRIMARYKEY(CustomerID,SalesID),
FOREIGNKEY(CustomerID) REFERENCES customerinfo(CustomerID) ON DELETE CASCADE)TYPE=INNODB;
ע�������еIJ��� ��ON DELETE CASCADE�����ò�����֤�� customerinfo ���е�һ���ͻ���¼��ɾ����ʱ��,salesinfo ����������ÿͻ���صļ�¼Ҳ�ᱻ�Զ�ɾ�������Ҫ�� MySQL ��ʹ�����,һ��Ҫ��ס�ڴ�������ʱ�������Ͷ���Ϊ����ȫ�� InnoDB ���͡������Ͳ��� MySQL ����Ĭ�����͡�����ķ������� CREATETABLE ����м��� TYPE=INNODB����������ʾ��
7��ʹ������
������������ݿ����ܵij��÷���,�����������ݿ�������Ա�û��������ö���ٶȼ����ض�����,�������ڲ�ѯ��䵱�а����� MAX (),MIN () �� ORDERBY ��Щ�����ʱ��,������߸�Ϊ���ԡ�
�Ǹö���Щ�ֶν���������?
һ��˵��,����Ӧ��������Щ������ JOIN,WHERE �жϺ� ORDERBY ������ֶ��ϡ�������Ҫ�����ݿ���ij�����д����ظ���ֵ���ֶν�������������һ�� ENUM ���͵��ֶ���˵,���ִ����ظ�ֵ�Ǻ��п��ܵ����
���� customerinfo �е� ��province���� �ֶ�,���������ֶ��Ͻ���������������ʲô����;�෴,���п��ܽ������ݿ�����ܡ������ڴ�������ʱ�����ͬʱ�������ʵ�����,Ҳ����ʹ�� ALTERTABLE �� CREATEINDEX ���Ժ�����������,MySQL �Ӱ汾 3.23.23 ��ʼ֧��ȫ��������������ȫ�������� MySQL ����һ�� FULLTEXT ��������,���������� MyISAM ���͵ı�������һ��������ݿ�,������װ�ص�һ��û�� FULLTEXT �����ı���,Ȼ����ʹ�� ALTERTABLE �� CREATEINDEX ��������,���Ƿdz���ġ������������װ�ص�һ���Ѿ��� FULLTEXT �����ı���,ִ�й��̽���dz�����
8���Ż��IJ�ѯ���
������������,ʹ������������߲�ѯ���ٶ�,����� SQL ���ʹ�ò�ǡ���Ļ�,��������������Ӧ�е����á�
������Ӧ��ע��ļ������档
����,���������ͬ���͵��ֶμ���бȽϵIJ�����
�� MySQL3.23 ��֮ǰ,��������һ����������������粻�ܽ�һ������������ INT �ֶκ� BIGINT �ֶν��бȽ�;������Ϊ��������,�� CHAR ���͵��ֶκ� VARCHAR �����ֶε��ֶδ�С��ͬ��ʱ��,���Խ����ǽ��бȽϡ�
���,�ڽ����������ֶ��Ͼ�����Ҫʹ�ú������в�����
����,��һ�� DATE ���͵��ֶ���ʹ�� YEAE () ����ʱ,����ʹ�������ܷ���Ӧ�е����á�����,�����������ѯ��Ȼ���صĽ��һ��,������Ҫ��ǰ�߿�öࡣ
����,�������ַ����ֶ�ʱ,������ʱ��ʹ�� LIKE �ؼ��ֺ�ͨ���,����������Ȼ��,��ȴҲ��������ϵͳ����Ϊ���۵ġ�
��������IJ�ѯ����Ƚϱ��е�ÿһ����¼��
SELECT * FROM books
WHERE name like"MySQL%"
���������������IJ�ѯ,���صĽ��һ��,���ٶȾ�Ҫ���Ϻܶ�:
SELECT * FROM books
WHERE name>="MySQL" andname <"MySQM"
���,Ӧ��ע������ڲ�ѯ���� MySQL �����Զ�����ת��,��Ϊת������Ҳ��ʹ������ò������á�
mysql ��־
�� MariaDB/MySQL ��,��Ҫ�� 5 ����־�ļ�:
- ������־ (error log):��¼ mysql �������ͣʱ��ȷ�ʹ������Ϣ,����¼������ֹͣ�����й����еĴ�����Ϣ��
- ��ѯ��־ (general log):��¼�����Ŀͻ������Ӻ�ִ�е���䡣
- ��������־ (bin log):��¼���и������ݵ����,���������ݸ��ơ�
- ����ѯ��־ (slow log):��¼����ִ��ʱ�䳬�� long_query_time �����в�ѯ��ʹ�������IJ�ѯ��
- �м���־ (relay log):���Ӹ���ʱʹ�õ���־��
��־ˢ�²���
���²�����ˢ����־�ļ�,ˢ����־�ļ�ʱ��رվɵ���־�ļ������´���־�ļ���������Щ��־����,���������־,ˢ����־�������־�ļ�,���������ǹرղ����´�
mysql> FLUSH LOGS;
shell> mysqladmin flush-logs
shell> mysqladmin refresh
������־
������־������Ҫ����־֮һ,����¼�� MariaDB/MySQL ����������ֹͣ��ȷ�ʹ������Ϣ,����¼�� mysqld ʵ�����й����з����Ĵ����¼���Ϣ��
����ʹ�á� �Clog-error=[file_name] ����ָ�� mysqld ��¼�Ĵ�����־�ļ�,���û��ָ�� file_name,��Ĭ�ϵĴ�����־�ļ�Ϊ datadir Ŀ¼�µ� hostname.err ,hostname ��ʾ��ǰ����������
Ҳ������ MariaDB/MySQL �����ļ��е� mysqld ���ò���,ʹ�� log-error ָ��������־��·����
�����֪��������־��λ��,���Բ鿴���� log_error ���鿴��
show variables like ��log_error��;
�� MySQL 5.5.7 ֮ǰ,ˢ����־���� (�� flush logs) �ᱸ�ݾɵĴ�����־ (��_old ��β),������һ���µĴ�����־�ļ�����,�� MySQL 5.5.7 ֮��,ִ��ˢ����־�IJ���ʱ,������־��رղ����´�,���������־������,����ȴ�����
�� MariaDB/MySQL ��������״̬��ɾ��������־��,�����Զ�����������־,ֻ����ˢ����־��ʱ��Żᴴ��һ���µĴ�����־�ļ���
һ���ѯ��־
��ѯ��־��Ϊһ���ѯ��־������ѯ��־,������ͨ����ѯ�Ƿ����� long_query_time ָ��ʱ���ֵ���ж��ġ��ڳ�ʱʱ������ɵIJ�ѯ��һ���ѯ,���Խ����¼��һ���ѯ��־��,���ǽ���ر�������־(Ĭ���ǹرյ�),����ʱ��IJ�ѯ������ѯ,���Խ����¼������ѯ��־�С�
ʹ�á� �Cgeneral_log={0|1} ���������Ƿ�����һ���ѯ��־,ʹ�á� �Cgeneral_log_file=file_name ����ָ����ѯ��־��·����������·��ʱĬ�ϵ��ļ����� hostname.log ������
�Ͳ�ѯ��־�йصı�����:
long_query_time = 10 # ָ������ѯ��ʱʱ��,������ʱ������������ѯ,���¼������ѯ��־�� log_output={TABLE|FILE|NONE}# ����һ���ѯ��־������ѯ��־�������ʽ,��ָ��ʱĬ��Ϊfile
TABLE ��ʾ��¼��־������,FILE ��ʾ��¼��־���ļ���,NONE ��ʾ����¼��־��ֻҪ����ָ��Ϊ NONE,��ʹ������һ���ѯ��־������ѯ��־,Ҳ���������κμ�¼��
��һ���ѯ��־��صı�����:
general_log=off ``# �Ƿ�����һ���ѯ��־,Ϊȫ�ֱ���,������global���ġ�sql_log_off=off # ��session��������Ƿ�����һ���ѯ��־,Ĭ��Ϊoff,������