����ѧϰ��̣���ѧϰ��ʱ����������õ�֪ʶ�㱣�����������ǿ���֪ʶ�������������ת���pdf��ʽ�������������ֻ�������ʱ�������Ǻܷ����
����һ�������IJ�������תpdf��ʽ�IJ���
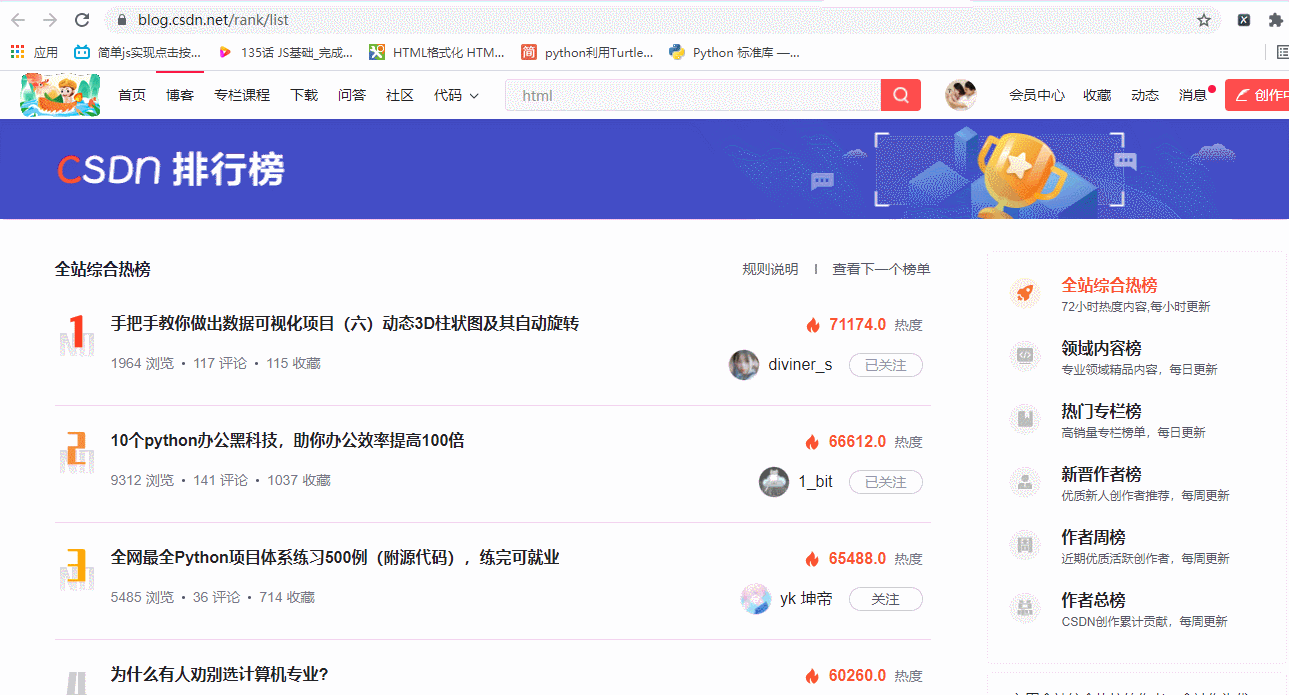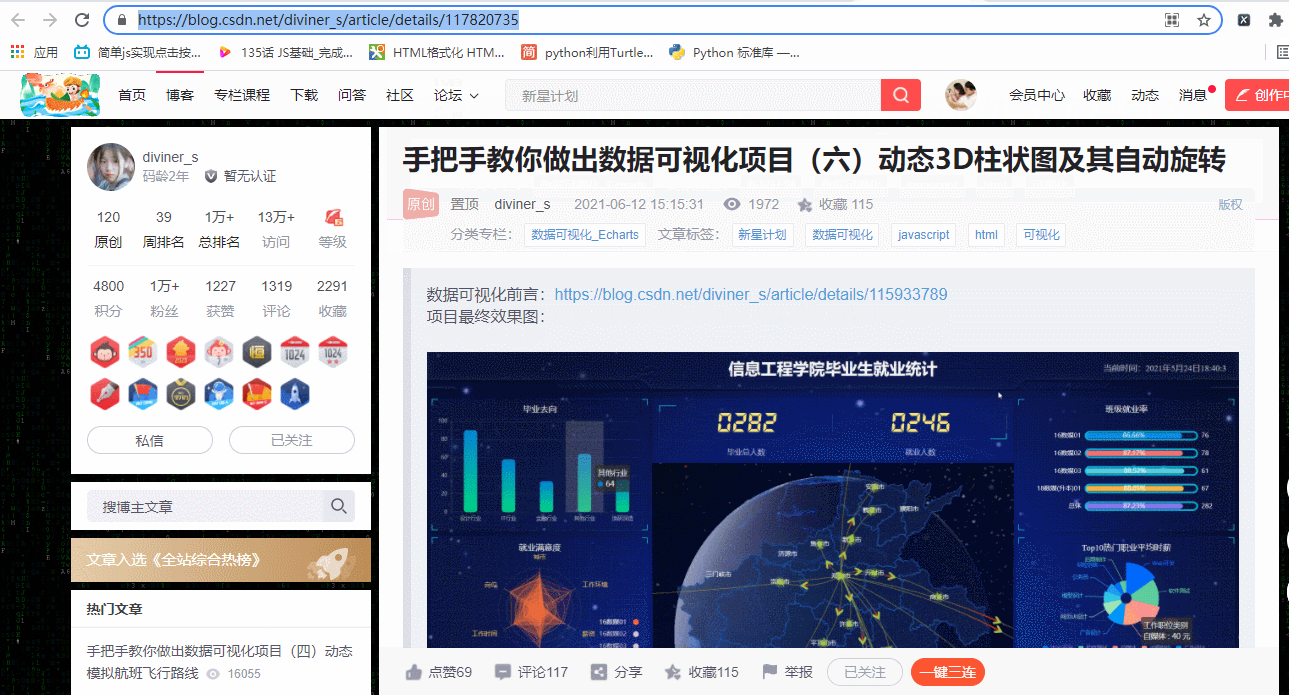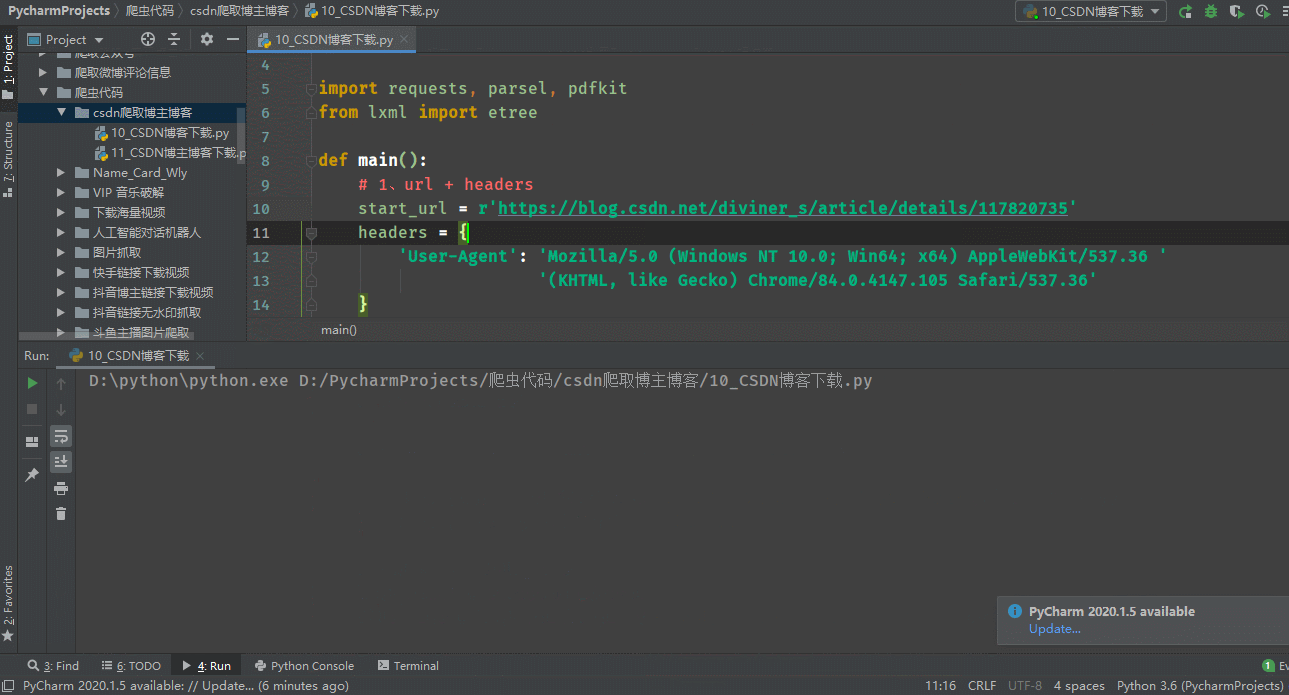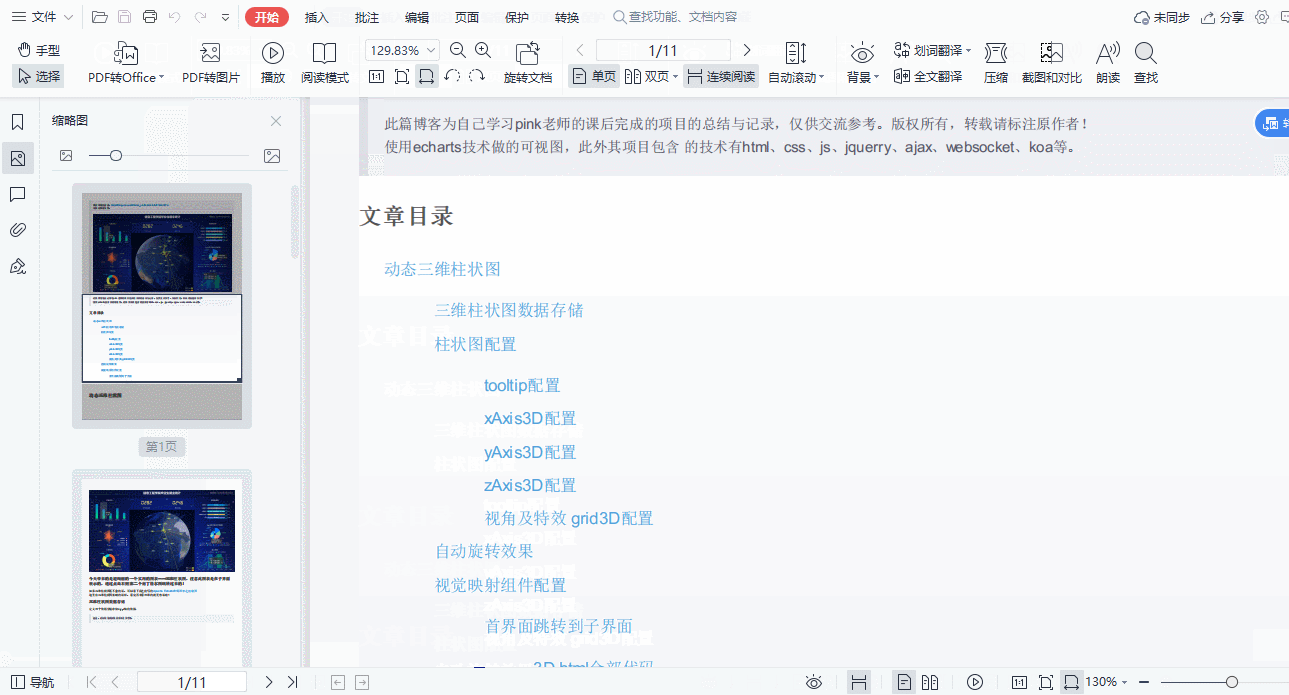
python�н�htmlת��Ϊpdf�ij��ù�����Wkhtmltopdf���߰�����python�����£�pdfkit��������߰��ķ�װ�ࡣ���ʹ��pdfkit�Լ���������أ������¼������衣
����wkhtmltopdf��װ�������Ұ�װ�������ϡ�
���ص�ַ��https://wkhtmltopdf.org/downloads.html
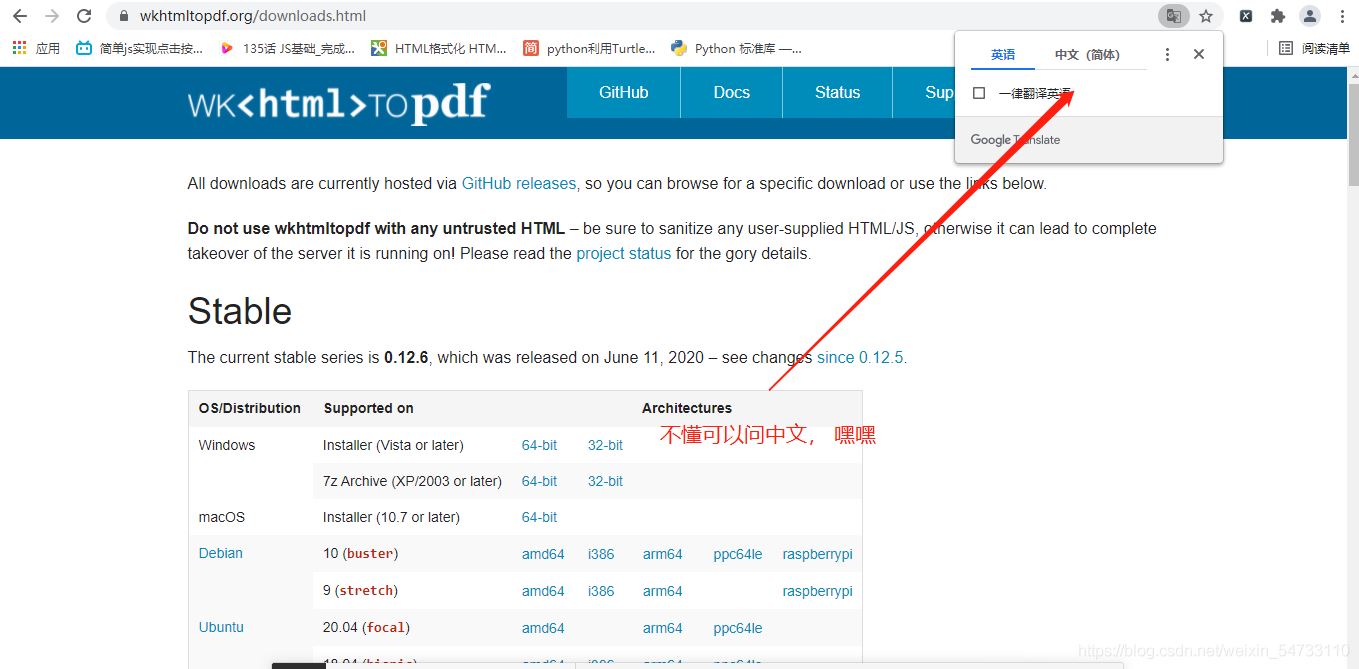
���µ�������汾����װ��ʱ��Ҫ��ס·����֮�����Ҫ�õ�·��

��������
- python
- pycharm
- pdfkit ��pip install pdfkit��
- lxml
����Ŀ�꣺������ȫ���������أ�����תpdf��ʽ����
����˼·��
1��url + headers
2��������ҳ�� CSDN��ҳ�Ǿ�̬��ҳ�� �����ȡ��ҳԴ����
3��lxml������ȡboke_urls, author_name
4��ѭ���������õ� boke_url
5��xpath������ȡ�ļ���
6��cssѡ������ȡ��ǩ�ı�������
7������ƴ��html�ļ�
8������html�ļ�
9���ļ���ת��
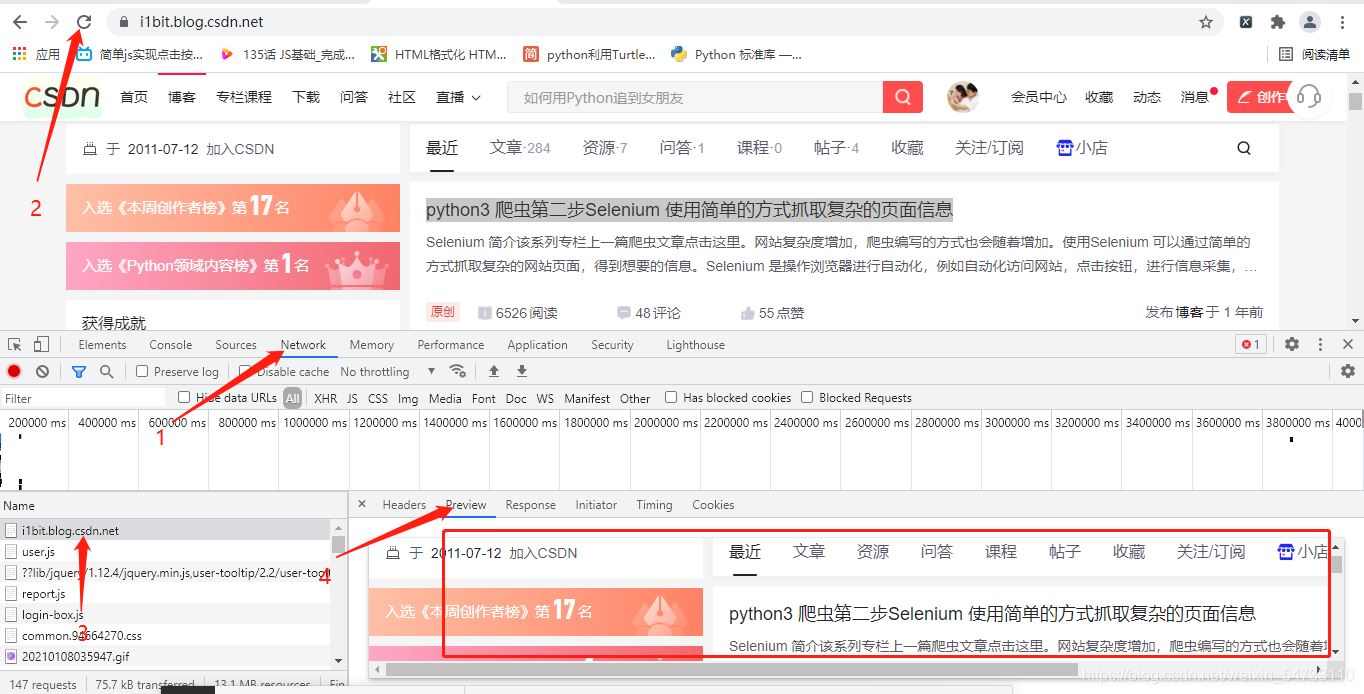
������ҳ�� CSDN��ҳ�Ǿ�̬��ҳ�� �����ȡ��ҳԴ����
start_url =��https://i1bit.blog.csdn.net/�� ��
ȷ����ַΪͬ������
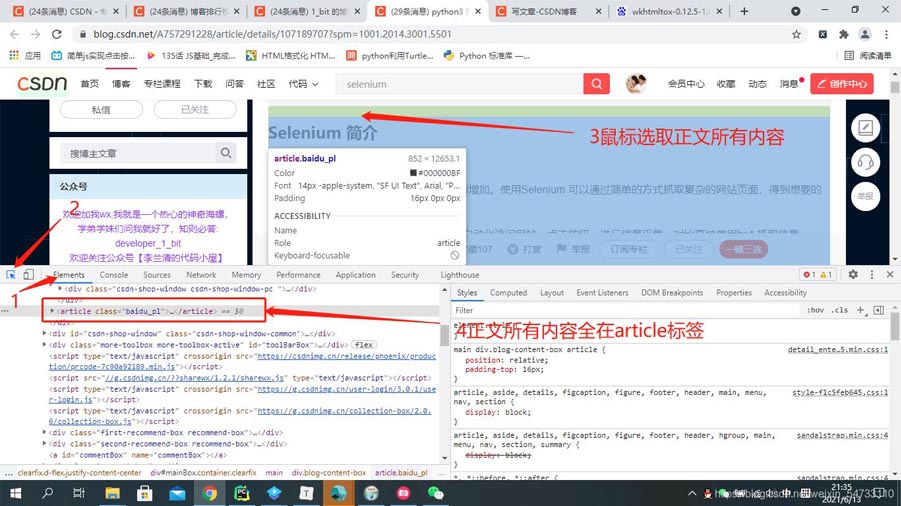
cssѡ������ȡ��ǩ�ı�������Ϊ����Ҫ�㲿��
css�����
# cssѡ������ȡ��ǩ�ı�������
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# ����ƴ��html�ļ�
html = \
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>
'''.format(html_content)
�㿪������һƪ���Ĵ����߹���
# cssѡ������ȡ��ǩ�ı�������
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# ����ƴ��html�ļ�
html = \
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>
'''.format(html_content)
�ļ���ת��
config = pdfkit.configuration(wkhtmltopdf=r'����Ϊ����wkhtmltopdf.exe��·��')
pdfkit.from_file(
��һ������Ҫת���html�ļ�,
�ڶ�������ת����pdf�ļ�,
configuration=config
)
# ��������д���һ�㣬Ҳ����ֱ��
pdfkit.from_file(
��һ������Ҫת���html�ļ�,
�ڶ�������ת����pdf�ļ�,
configuration=pdfkit.configuration(wkhtmltopdf=r'����Ϊ����wkhtmltopdf.exe��·��')
)
Դ��չʾ��
import parsel, os, pdfkit
from lxml import etree
from requests_html import HTMLSession
session = HTMLSession()
def main():
# 1��url + headers
start_url = input(r'������csdn�����ĵ�ַ��')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
# 2��������ҳ�� CSDN��ҳ�Ǿ�̬��ҳ�� �����ȡ��ҳԴ����
response_1 = session.get(start_url, headers=headers).text
# 3��������ȡboke_urls, author_name
html_xpath_1 = etree.HTML(response_1)
author_name = html_xpath_1.xpath(r'//*[@]/div/div[1]/div[2]/div[2]/div[1]/div[1]/text()')[0]
boke_urls = html_xpath_1.xpath(r'//article[@class="blog-list-box"]/a/@href')
# 4��ѭ���������õ� boke_url
for boke_url in boke_urls:
# 5������
response_2 = session.get(boke_url, headers=headers).text
# 6��xpath������ȡ�ļ���
html_xpath_2 = etree.HTML(response_2)
file_name = html_xpath_2.xpath(r'//h1[@]/text()')[0]
# 7��cssѡ������ȡ��ǩ�ı�������
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 8������ƴ��html�ļ�
html = \
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>
'''.format(html_content)
# 9�����������ļ��У� һ����������html һ����������pdf�ļ�
if not os.path.exists(r'{}-html'.format(author_name)):
os.mkdir(r'{}-html'.format(author_name))
if not os.path.exists(r'{}-pdf'.format(author_name)):
os.mkdir(r'{}-pdf'.format(author_name))
# 10������html�ļ�
try:
with open(r'{}-html/{}.html'.format(author_name, file_name), 'w', encoding='utf-8') as f:
f.write(html)
except Exception as e:
print('�ļ�������')
# 11���ļ���ת��
try:
config = pdfkit.configuration(wkhtmltopdf=r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')
pdfkit.from_file(
'{}-html/{}.html'.format(author_name, file_name),
'{}-pdf/{}.pdf'.format(author_name, file_name),
configuration=config
)
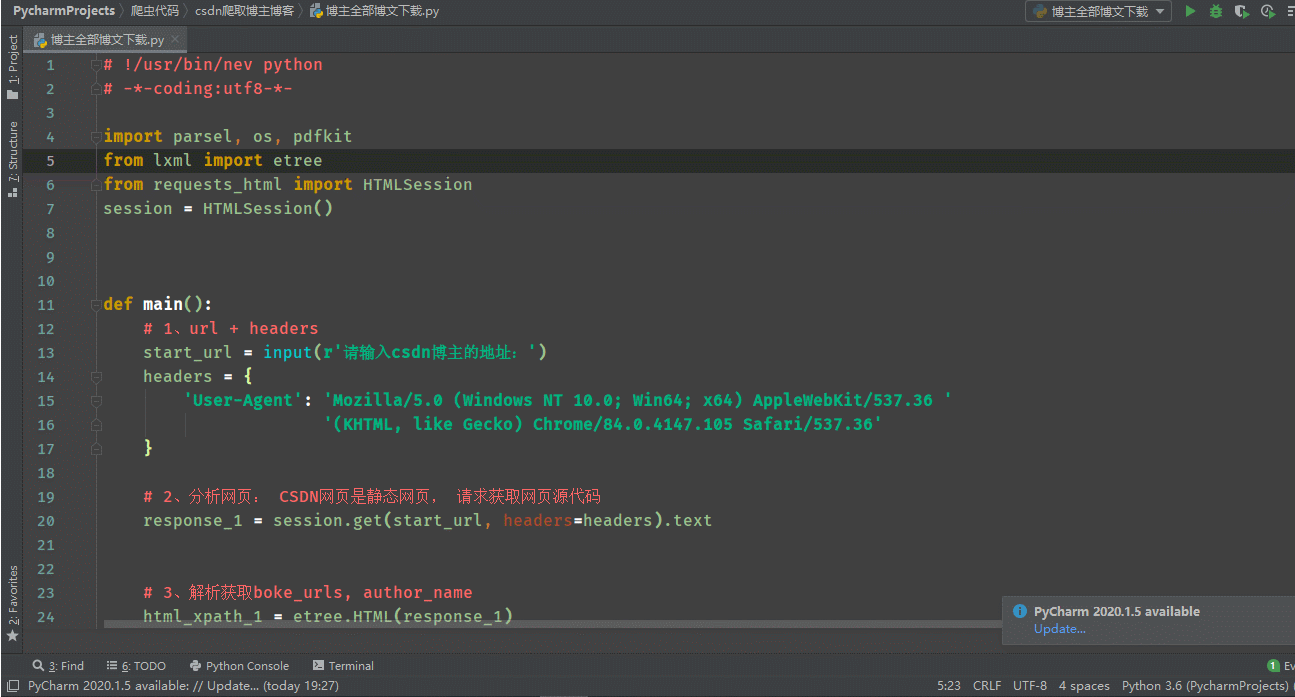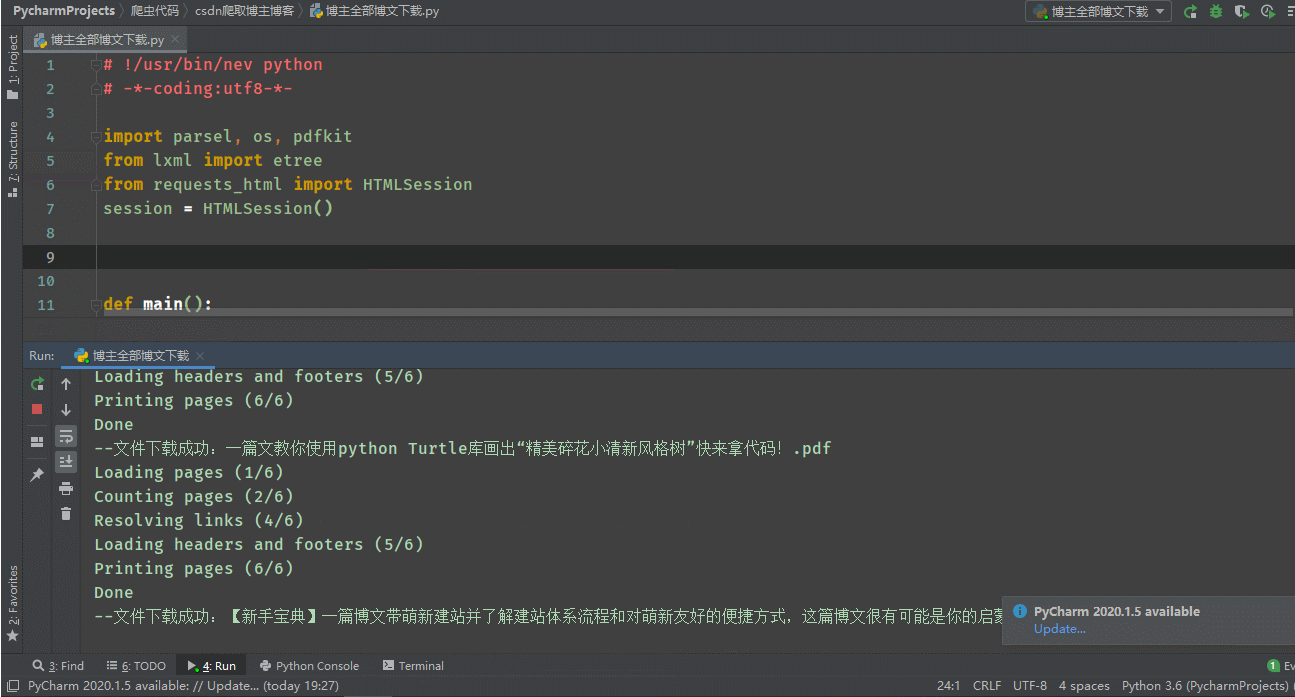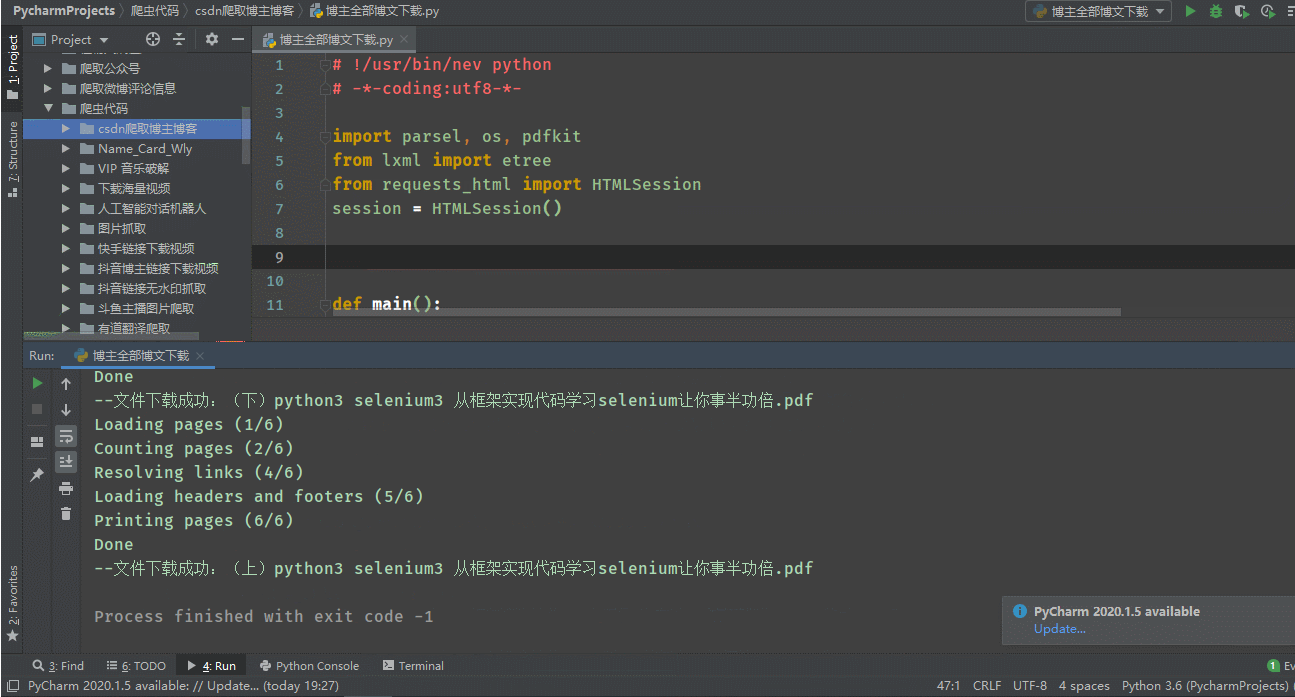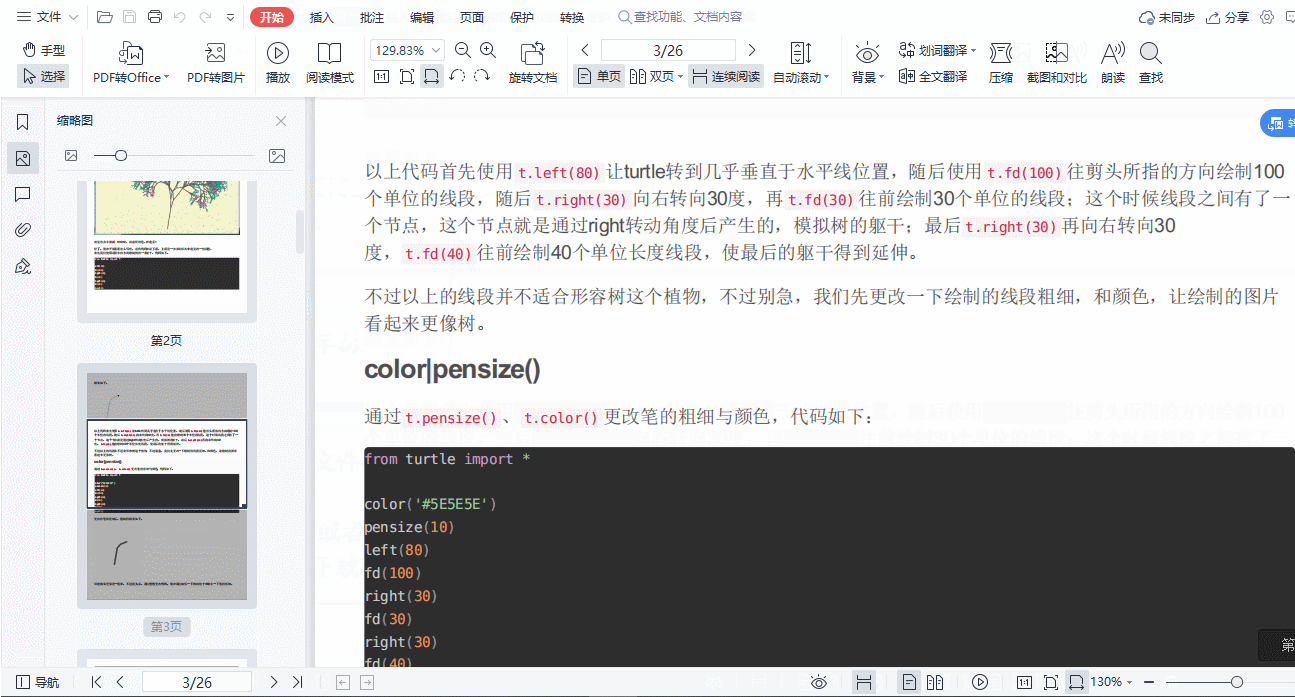
a = print(r'--�ļ����سɹ���{}.pdf'.format(file_name))
except Exception as e:
continue
if __name__ == '__main__':
main()
���������
jsjbwy