前言
正则表达式作为计算机科学的一个概念,通常被用来检索、替换那些符合某个规则的文本。正则表达式是对字符串操作的一种逻辑公式,用事先定义好的规则字符串对字符串进行过滤逻辑处理。
re模块总结,正则表达式。在网络爬虫中对于数据定位,学习regex也很有必要
常用方法
- re.compile()
将指定的正则表达式模式编译为正则表达式对象,可用于匹配和搜索
- re.match()
该方法用于匹配字符串开头的模式
- re.serach()
该方法用于匹配出现在字符串中任意位置的模式
- re.findall()
该方法返回字符串中制定正则表达式模式的所有非重叠匹配项
- re.finditer()
对于从左到右扫描字符串中的特定模式,该方法以迭代器的形式返回所有匹配的实例
- re.sub()
用于以替换串来替代字符串中特定的模式,他仅仅替换字符串中最左侧出现的模式
重要标识符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:

常用表达式规则
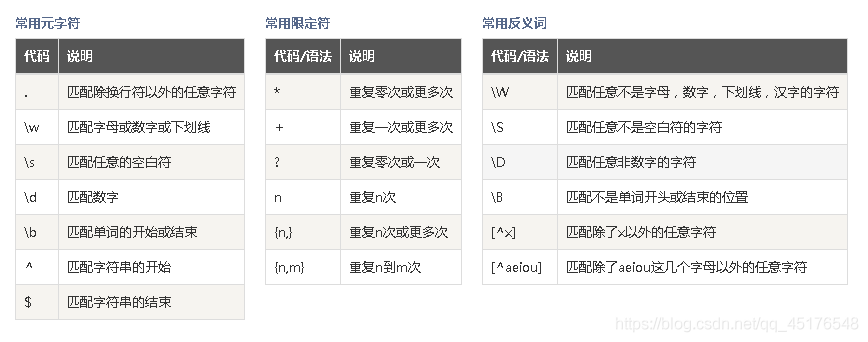
举例说明
下面的代码描述了其中一些方法,并展示了在处理字符串和正则表达式通常如何使用他们
import re
pattern = "python"
s1 = "Python is an excellent language"
s2 = "I love Python language.I also use Python to build applicants at work!"
re.match(pattern, string, flags=0)
从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
因为大小写,无法匹配成功
re.I 或 re.IGNORECASE 用于匹配不区分大小写的模式
re.match(pattern,s1,re.I)
<re.Match object; span=(0, 6), match='Python'>
re.match(pattern,s1,re.IGNORECASE)
<re.Match object; span=(0, 6), match='Python'>
re.search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个
现在来看下find()和search()方法在正则表达式是如何工作的
re.search(pattern,s2,re.IGNORECASE)
<re.Match object; span=(7, 13), match='Python'>
re.findall(pattern, string, flags=0)
match and search均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
re.findall(pattern,s2,re.IGNORECASE)
['Python', 'Python']
re.sub(pattern, repl, string, count=0, flags=0)
用于文本替换的正则表达式对于查找和替换字符串中的特定文本标识符很有用
用于替换匹配的字符串,比str.replace功能更加强大
re.sub(pattern,"Java",s2,flags=re.I)
'I love Java language.I also use Java to build applicants at work!'
re.subn(pattern,"Java",s2,flags=re.I)
('I love Java language.I also use Java to build applicants at work!', 2)
re.split(pattern, string, maxsplit=0, flags=0)
用匹配到的值做为分割点,把值分割成列表
s1
'Python is an excellent language'
re.split(" ",s1)
['Python', 'is', 'an', 'excellent', 'language']
按数字分割
print(re.split("\d+","https://blog.csdn.net/qq_45176548"))
‘(?P…)' 分组匹配
s = '230701200104280028'
print(re.search('(?P<province>\d{3})(?P<city>\d{3})(?P<born_date>\d{8})(?P<seq>\d{4})',s))
print(re.search('(?P<province>\d{3})(?P<city>\d{3})(?P<born_date>\d{8})(?P<seq>\d{4})',s).groups())
res = re.search('(?P<province>\d{3})(?P<city>\d{3})(?P<born_date>\d{8})(?P<seq>\d{4})',s)
print(res.groupdict())
<re.Match object; span=(0, 18), match='230701200104280028'>
('230', '701', '20010428', '0028')
{'province': '230', 'city': '701', 'born_date': '20010428', 'seq': '0028'}
---
总结
js