torch.where() гУгкНЋСНИіbroadcastableЕФtensorзщКЯГЩаТЕФtensorЃЌРрЫЦгкc++жаЕФШ§дЊВйзїЗћЁА?:ЁБ
ЧјБ№гкpython numpyжаЕФwhere()жБНгПЩвдевЕНЬиЖЈЬѕМўдЊЫиЕФindex
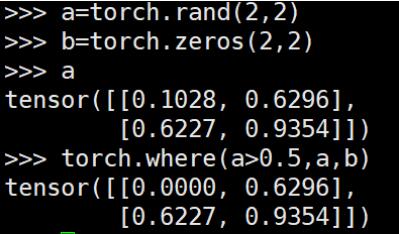
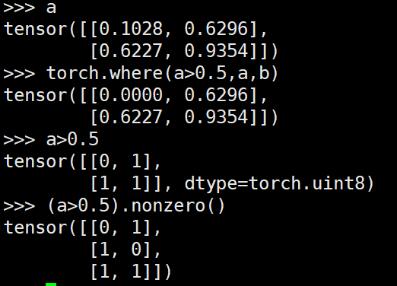
ЯывЊЪЕЯжnumpyжаwhere()ЕФЙІФмЃЌПЩвдНшжњnonzero()
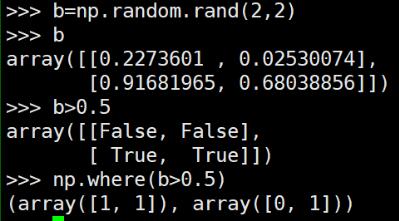
ЖдгІnumpyжаЕФwhere()ВйзїаЇЙћ:
ВЙГфЃКPytorch torch.Tensor.detach()ЗНЗЈЕФгУЗЈМАаоИФжИЖЈФЃПщШЈжиЕФЗНЗЈ
detach
detachЕФжаЮФвтЫМЪЧЗжРыЃЌЙйЗННтЪЭЪЧЗЕЛивЛИіаТЕФTensor,ДгЕБЧАЕФМЦЫуЭМжаЗжРыГіРД

ашвЊзЂвтЕФЪЧЃЌЗЕЛиЕФTensorКЭдTensorЙВЯэЯрЭЌЕФДцДЂПеМфЃЌЕЋЪЧЗЕЛиЕФ Tensor гРдЖВЛЛсашвЊЬнЖШ
import torch as t
a = t.ones(10,)
b = a.detach()
print(b)
tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
ФЧУДетИіКЏЪ§гаЪВУДзїгУ?
ЈCМйШчAЭјТчЪфГіСЫвЛИіTensorРраЭЕФБфСПa, aвЊзїЮЊЪфШыДЋШыЕНBЭјТчжаЃЌШчЙћЮвЯыЭЈЙ§Ы№ЪЇКЏЪ§ЗДЯђДЋВЅаоИФBЭјТчЕФВЮЪ§ЃЌЕЋЪЧВЛЯыаоИФAЭјТчЕФВЮЪ§ЃЌетИіЪБКђОЭПЩвдЪЙгУdetcah()ЗНЗЈ
a = A(input)
a = detach()
b = B(a)
loss = criterion(b, target)
loss.backward()
РДПДвЛИіЪЕМЪЕФР§згЃК
import torch as t
x = t.ones(1, requires_grad=True)
x.requires_grad #True
y = t.ones(1, requires_grad=True)
y.requires_grad #True
x = x.detach() ЁЁЁЁ#ЗжРыжЎКѓ
x.requires_grad #False
y = x+y #tensor([ЃВ.])
y.requires_grad #ЮвЛЙЪЧTrue
y.retain_grad() #yВЛЪЧвЖзгеХСПЃЌвЊМгЩЯетвЛаа
z = t.pow(y, 2)
z.backward() ЁЁЁЁ#ЗДЯђДЋВЅ
y.grad ЁЁЁЁЁЁЁЁЁЁЁЁ#tensor([ЃД.])
x.grad ЁЁЁЁЁЁЁЁЁЁЁЁ#None
вдЩЯДњТыОЭЫЕУїСЫЗДЯђДЋВЅЕНyОЭНсЪјСЫЃЌУЛгаЕНДяx,ЫљвдxЕФgradЪєадЮЊNone
МШШЛЬИЕНСЫаоИФФЃаЭЕФШЈжиЮЪЬтЃЌФЧУДЛЙгавЛжжЧщПіЪЧ:
ЈCМйШчAЭјТчЪфГіСЫвЛИіTensorРраЭЕФБфСПa, aвЊзїЮЊЪфШыДЋШыЕНBЭјТчжаЃЌШчЙћЮвЯыЭЈЙ§Ы№ЪЇКЏЪ§ЗДЯђДЋВЅаоИФAЭјТчЕФВЮЪ§ЃЌЕЋЪЧВЛЯыаоИФBЭјТчЕФВЮЪ§ЃЌетИіЪБКђгжгІИУдѕУДАьСЫ?
етЪБПЩвдЪЙгУTensor.requires_gradЪєадЃЌжЛашвЊНЋrequires_gradаоИФЮЊFalseМДПЩЃЎ
for param in B.parameters():
param.requires_grad = False
a = A(input)
b = B(a)
loss = criterion(b, target)
loss.backward()
вдЩЯЮЊИіШЫОбщЃЌЯЃЭћФмИјДѓМввЛИіВЮПМЃЌвВЯЃЭћДѓМвЖрЖржЇГжеОГЄВЉПЭЁЃШчгаДэЮѓЛђЮДПМТЧЭъШЋЕФЕиЗНЃЌЭћВЛСпДЭНЬЁЃ
js