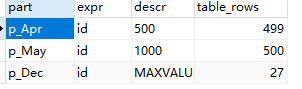
EXPLAIN SELECT * from sy_login_log

可以看到语句使用到了哪几个分区,查询条数等?
六、分区表操作
CREATE?TABLE t1?(
??? id?INT,
??? year_col?INT
)
PARTITION?BY?RANGE?(year_col)?(
????PARTITION p0?VALUES?LESS?THAN?(1991),
????PARTITION p1?VALUES?LESS?THAN?(1995),
????PARTITION p2?VALUES?LESS?THAN?(1999)
);
1、ADD PARTITION (新增分区)
ALTER?TABLE t1?ADD?PARTITION?(PARTITION p3?VALUES?LESS?THAN?(2002));
2、DROP?PARTITION?(删除分区)
ALTER?TABLE t1?DROP?PARTITION p0, p1;
3、TRUNCATE?PARTITION(截取分区)
ALTER?TABLE t1?TRUNCATE?PARTITION p0;
ALTER?TABLE t1?TRUNCATE?PARTITION p1, p3;
4、COALESCE PARTITION(合并分区)
CREATE?TABLE t2?(
????name?VARCHAR?(30),
??? started?DATE
)
PARTITION?BY?HASH(?YEAR(started)?)
PARTITIONS?6;
ALTER?TABLE t2?COALESCE?PARTITION?2;
5、REORGANIZE PARTITION(拆分/重组分区)
1)拆分分区
ALTER?TABLE?table?ALGORITHM=INPLACE,?REORGANIZE?PARTITION;
ALTER TABLE employees ADD PARTITION (
??? PARTITION p5 VALUES LESS THAN (2010),
??? PARTITION p6 VALUES LESS THAN MAXVALUE
);
2)重组分区
ALTER TABLE members REORGANIZE PARTITION s0,s1 INTO (
??? PARTITION p0 VALUES LESS THAN (1970)
);
ALTER TABLE tbl_name
??? REORGANIZE PARTITION partition_list
??? INTO (partition_definitions);
ALTER TABLE members REORGANIZE PARTITION p0,p1,p2,p3 INTO (
??? PARTITION m0 VALUES LESS THAN (1980),
??? PARTITION m1 VALUES LESS THAN (2000)
);
ALTER TABLE tt ADD PARTITION (PARTITION np VALUES IN (4, 8));
ALTER TABLE tt REORGANIZE PARTITION p1,np INTO (
??? PARTITION p1 VALUES IN (6, 18),
??? PARTITION np VALUES in (4, 8, 12)
);
6、ANALYZE 、CHECK PARTITION(分析与检查分区)
1)ANALYZE 读取和存储分区中值的分布情况
ALTER?TABLE t1?ANALYZE?PARTITION p1,?ANALYZE?PARTITION p2;
ALTER?TABLE t1?ANALYZE?PARTITION p1, p2;
2)CHECK 检查分区是否存在错误
ALTER?TABLE t1?ANALYZE?PARTITION p1,?CHECK?PARTITION p2;
7、REPAIR分区
修复被破坏的分区
ALTER TABLE t1 REPAIR PARTITION p0,p1;
8、OPTIMIZE
该命令主要是用于回收空闲空间和分区的碎片整理。对分区执行该命令,相当于依次对分区执行?CHECK PARTITION, ANALYZE PARTITION,REPAIR PARTITION命令。
譬如:
ALTER TABLE t1 OPTIMIZE PARTITION p0, p1;
9、REBUILD分区
重建分区,它相当于先删除分区中的数据,然后重新插入。这个主要是用于分区的碎片整理。
ALTER TABLE t1 REBUILD PARTITION p0, p1;
10、EXCHANGE PARTITION(分区交换)
分区交换的语法如下:
ALTER TABLE pt EXCHANGE PARTITION p WITH TABLE nt
其中,pt是分区表,p是pt的分区(注:也可以是子分区),nt是目标表。
其实,分区交换的限制还是蛮多的:
1) nt不能为分区表
2)nt不能为临时表
3)nt和pt的结构必须一致
4)nt不存在任何外键约束,即既不能是主键,也不能是外键。
5)nt中的数据不能位于p分区的范围之外。
具体可参考MySQL的官方文档
11、迁移分区(DISCARD 、IMPORT )
ALTER?TABLE t1?DISCARD?PARTITION p2, p3?TABLESPACE;
ALTER?TABLE t1?IMPORT?PARTITION p2, p3?TABLESPACE;
实验环境:(都是mysql5.7)
源库:192.168.2.200????? mysql5.7.16??? zhangdb下的emp_2分区表的
目标库:192.168.2.100??? mysql5.7.18??? test下? (将zhangdb的emp表,导入到目标库的test schema下)
--:在源数据库中创建测试分区表emp_2,然后导入数据
MySQL [zhangdb]> CREATE TABLE emp_2(
id BIGINT unsigned NOT NULL AUTO_INCREMENT,
x VARCHAR(500) NOT NULL,
y VARCHAR(500) NOT NULL,
PRIMARY KEY(id)
)
PARTITION BY RANGE COLUMNS(id)
(
PARTITION p1 VALUES LESS THAN (1000),?
PARTITION p2 VALUES LESS THAN (2000),?
PARTITION p3 VALUES LESS THAN (3000)????
);?
(接着创建存储过程,导入测试数据)
DELIMITER //
CREATE PROCEDURE insert_batch()
begin
DECLARE num INT;
SET num=1;
WHILE num < 3000 DO
IF (num%10000=0) THEN
COMMIT;
END IF;
INSERT INTO emp_2 VALUES(NULL, REPEAT('X', 500), REPEAT('Y', 500));
SET num=num+1;
END WHILE;
COMMIT;
END //
DELIMITER ;
mysql> select TABLE_NAME,PARTITION_NAME from information_schema.partitions where table_schema='zhangdb';
+------------+----------------+
| TABLE_NAME | PARTITION_NAME |
+------------+----------------+
| emp??????? | NULL?????????? |
| emp_2????? | p1???????????? |
| emp_2????? | p2???????????? |
| emp_2????? | p3???????????? |
+------------+----------------+
4 rows in set (0.00 sec)
mysql> select count(*) from emp_2 partition (p1);
+----------+
| count(*) |
+----------+
|????? 999 |
+----------+
1 row in set (0.00 sec)
mysql> select count(*) from emp_2 partition (p2);
+----------+
| count(*) |
+----------+
|???? 1000 |
+----------+
1 row in set (0.00 sec)
mysql> select count(*) from emp_2 partition (p3);
+----------+
| count(*) |
+----------+
|???? 1000 |
+----------+
1 row in set (0.00 sec)
从上面可以看出,emp_2分区表已经创建完成,并且有3个子分区,每个分区都有一点数据。
--:在目标数据库中,创建emp_2表的结构,不要数据(要在源库,使用show create table emp_2\G 的方法 查看创建该表的sql)
MySQL [test]> CREATE TABLE `emp_2` (
? `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
? `x` varchar(500) NOT NULL,
? `y` varchar(500) NOT NULL,
? PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3000 DEFAULT CHARSET=utf8mb4
/*!50500 PARTITION BY RANGE? COLUMNS(id)
(PARTITION p1 VALUES LESS THAN (1000) ENGINE = InnoDB,
?PARTITION p2 VALUES LESS THAN (2000) ENGINE = InnoDB,
?PARTITION p3 VALUES LESS THAN (3000) ENGINE = InnoDB) */ ;
[root@localhost test]# ll
-rw-r----- 1 mysql mysql 98304 May 25 15:58 emp_2#P#p0.ibd
-rw-r----- 1 mysql mysql 98304 May 25 15:58 emp_2#P#p1.ibd
-rw-r----- 1 mysql mysql 98304 May 25 15:58 emp_2#P#p2.ibd
注意:
※约束条件、字符集等等也必须一致,建议使用show create table t1; 来获取创建表的SQL,否则在新服务器上导入表空间的时候会提示1808错误。
--:在目标数据库上,丢弃分区表的表空间
MySQL [test]> alter table emp_2 discard tablespace;
Query OK, 0 rows affected (0.12 sec)
[root@localhost test]# ll??? ---这时候在看,刚才的3个分区的idb文件都没有了
-rw-r----- 1 mysql mysql? 8604 May 25 04:14 emp_2.frm
--:在源数据库上运行FLUSH TABLES … FOR EXPORT 锁定表并生成.cfg元数据文件,最后将cfg和ibd文件传输到目标数据库中
mysql> flush tables emp_2 for export;
Query OK, 0 rows affected (0.00 sec)
[root@localhost zhangdb]# scp emp_2* root@192.168.2.100:/mysql/data/test/?? --将文件cp到目标数据库
mysql> unlock tables;?? ---最后将表的锁是否
--:在目标数据库中对文件授权,然后导入表空间查看数据是否完整可用
[root@localhost test]# chown mysql.mysql emp_2#*
MySQL [test]> alter table emp_2 import tablespace;
Query OK, 0 rows affected (0.96 sec)
MySQL [test]> select count(*) from emp_2;
+----------+
| count(*) |
+----------+
|???? 2999 |
+----------+
1 row in set (0.63 sec)
从上面的查看得知,分区表都已经导入到目标数据库中了,
另外,也可以将部分子分区导入到目标数据库中,(往往整个分区表会很大,可用只将需要用到的子分区导入到目标数据库中),
将部分子分区导入到目标数据库的方法是:
1)在创建目标表的时候,只需要创建要导入的分区即可,如: 只创建了p2 p3两个分区
?CREATE TABLE `emp_2` (
? `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
? `x` varchar(500) NOT NULL,
? `y` varchar(500) NOT NULL,
? PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3000 DEFAULT CHARSET=utf8mb4
/*!50500 PARTITION BY RANGE? COLUMNS(id)
(
?PARTITION p2 VALUES LESS THAN (2000) ENGINE = InnoDB,
?PARTITION p3 VALUES LESS THAN (3000) ENGINE = InnoDB) */
2)从源库cp到目标库的文件,当然也就是这俩的,就不需要其他分区的了,
3)其他的操作方法都一样了。
整理自:https://www.cnblogs.com/xibuhaohao/p/10154281.html
https://www.cnblogs.com/pejsidney/p/10074980.html
cs