就像其他的领域有自己的经典流程一样,一个文本分析的项目也有属于自己的流程。虽然每一个NLP项目有所不同,但至于流程来说没有太多本质的区别。这里会涉及到如分词、停用词过滤、文本向量的转化等步骤。
分词是所有工作的第一步,分词的准确性直接影响到后续任务的表现。现如今分词技术相对比较成熟,也有很多开源的工具可用来做中文或者对其他语言的分词。下面,主要介绍如何初步使用Jieba分词工具进行分词。
import jieba
# 基于jieba的分词, 结巴词库不包含"贪心学院"关键词
seg_list = jieba.cut("贪心学院专注于人工智能教育", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))
jieba.add_word("贪心学院") # 加入关键词
seg_list = jieba.cut("贪心学院专注于人工智能教育", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))
输出结果:
Default Mode: 贪心/ 学院/ 专注/ 于/ 人工智能/ 教育
Default Mode: 贪心学院/ 专注/ 于/ 人工智能/ 教育
可以看出将贪心学院加入词典后,分词结果就能包含贪心学院。?
3.最大匹配算法
下面介绍分词的最基础的方法――最大匹配算法。最大匹配算法主要包括正向最大匹配算法、逆向最大匹配算法、双向匹配算法等。 其主要原理都是切分出单字串,然后和词库进行比对,如果是一个词就记录下来, 否则通过增加或者减少一个单字,继续比较,一直还剩下一个单字则终止,如果该单字串无法切分,则作为未登录处理。
算法思想:
正向最大匹配算法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。但这里有一个问题:要做到最大匹配,并不是第一次匹配到就可以切分的?。我们来举个例子:
待分词文本:?? content[]={"我","们","经常","有","意","见","分","歧","。"}
词典:?? dict[]={"我们", "经常" , "有","有意见","意见","分歧"}
(1) 取字符串长度为5,从content[1]开始,发现"我们经常有"不在词典dict[]中了。
(2) 继续扫描content[2],发现"我们经常"并不是dict[]中的词。
(3) 继续扫描content[3],发现"我们经"也不是dict[]中的词。继续扫描下去:
(4) 当扫描content[4]的时候,发现"我们"是词典中的词。因此可以切分出前面最大的词――"我们"。
(5)接下来继续扫描content[5],发现"经常有意见"不在词典dict[]中,按如上步骤一直扫描到包含的词典中的词。最终分词结果:我们\经常\有意见\分歧\。
最大匹配算法并不能保证找到的是最好的分词结果。整个过程是贪心策略,寻求的是局部最好的选项,但从全局来讲未必是最好的。另一方面,由于是贪心策略,所以分词的效率也很高。而且并没有考虑到语义信息。如上述例子,其实最好的分词结果应该是:我们\经常\有意见\分歧\。
4.考虑语义的一种分词方法
如何将语义信息融入到分词中,大致的思想就是根据词典及其每个词出现的概率,可以得到所有可能出现路径,找到最大概率的路径。

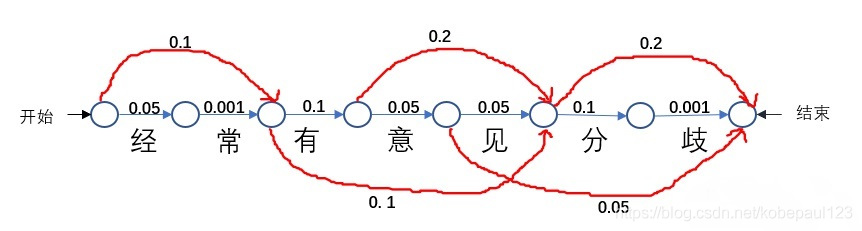
那我们得到了这个路径图,该如何找到最大路径呢?这时主要就用到了维特比算法。
维特比算法是一种动态规划算法用于寻找最有可能产生观测事件序列的-维特比路径-隐含状态序列,特别是在马尔可夫信息源上下文和隐马尔可夫模型中。具体流程可以参考算法实现分词。
总的来说,分词可以认为是已经解决的问题,分为两种方法:基于匹配规则和基于概率统计方法(LM,HMM,CRF)。
二、停用词与词的标准化
1.词的过滤
在文本处理过程中,对于有些词需要做过滤。这些被过滤掉的单词可认为是对语义理解帮助不大,或者反而影响语义理解的单词。同时,过滤单词有助于减小词库的大小,进而提高训练的效率和减少内存空间的使用。主要是去掉停用词、低频次的词。
# 方法1: 自己建立一个停用词词典
stop_words = ["the", "an", "is", "there"]
# 在使用时: 假设 word_list包含了文本里的单词
word_list = ["we", "are", "the", "students"]
filtered_words = [word for word in word_list if word not in stop_words]
# 方法2:直接利用别人已经构建好的停用词库
from nltk.corpus import stopwords
cachedStopWords = stopwords.words("english")
filtered_words1 = [word for word in word_list if word not in cachedStopWords]
print (filtered_words1)
2.词的标准化
词的标准化包括词干提取(stemming)和词形还原(lemmazation)。
lemmatization是把一个任何形式的语言词汇还原为一般形式(能表达完整语义),stemming是抽取词的词干或词根形式(不一定能够表达完整语义)。词形还原和词干提取是词形规范化的两类重要方式,都能够达到有效归并词形的目的,相对而言,词干提取是简单的轻量级的词形归并方式,最后获得的结果为词干,并不一定具有实际意义。词形还原处理相对复杂,获得结果为词的原形,能够承载一定意义,与词干提取相比,更具有研究和应用价值。
使用Porter stemmer工具进行分词。
from nltk.stem.porter import *
stemmer = PorterStemmer()
test_strs = ['caresses', 'flies', 'dies', 'mules', 'denied',
'died', 'agreed', 'owned', 'humbled', 'sized',
'meeting', 'stating', 'siezing', 'itemization',
'sensational', 'traditional', 'reference', 'colonizer',
'plotted']
singles = [stemmer.stem(word) for word in test_strs]
print(' '.join(singles)) # doctest: +NORMALIZE_WHITESPACE
三、 拼写纠错
在人为输入文本或者语音转文本后,容易出现拼写错误或者语法错误。由于语法错误判断主要涉及语言模型相关知识,在之后的系列文章会提到,所以在本节中主要研究拼写错误。
对于两个单词的拼写相似度衡量,可以通过三个操作:add、replace以及delete。
总结起来,关于拼写纠错单词的第一种方法是:
- 第一步:寻找拼写错误的单词
- 第二步:寻找跟上面单词“长得”最像的,可通过循环词库,并计算编辑距离来获得。
- 第三步:从上述候选集里,根据上下文进一步做筛选和排序,最终寻找最合适的单词。
关于拼写纠错单词的第二种方法是:
- 第一步:找到拼写错误的单词
- 第二步:生成跟上述单词类似的其他单词,当作是候选集
- 第三步:根据单词在上下文中的统计信息来排序并选出最好的。
总结
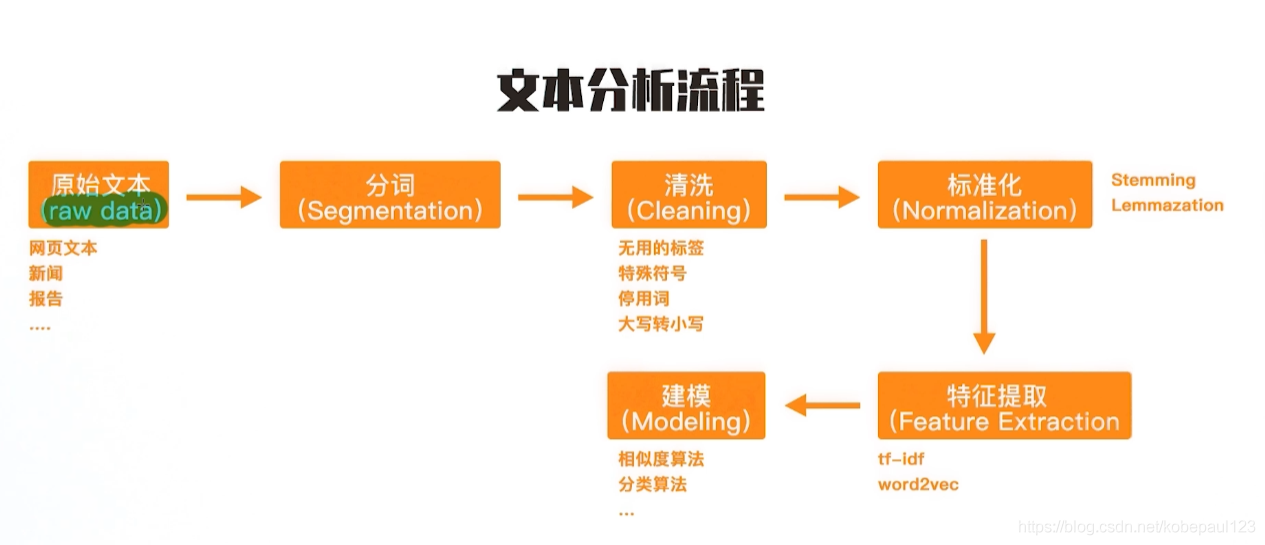
总的来说,文本处理主要包括以下几个步骤:原始文本进入、分词、清洗、标准化、特征提取、建模。如下图所示:
参考:
贪心学院nlp
算法实现分词
词干提取(stemming)和词形还原(lemmatization)
如何通俗地讲解 viterbi 算法?
cs