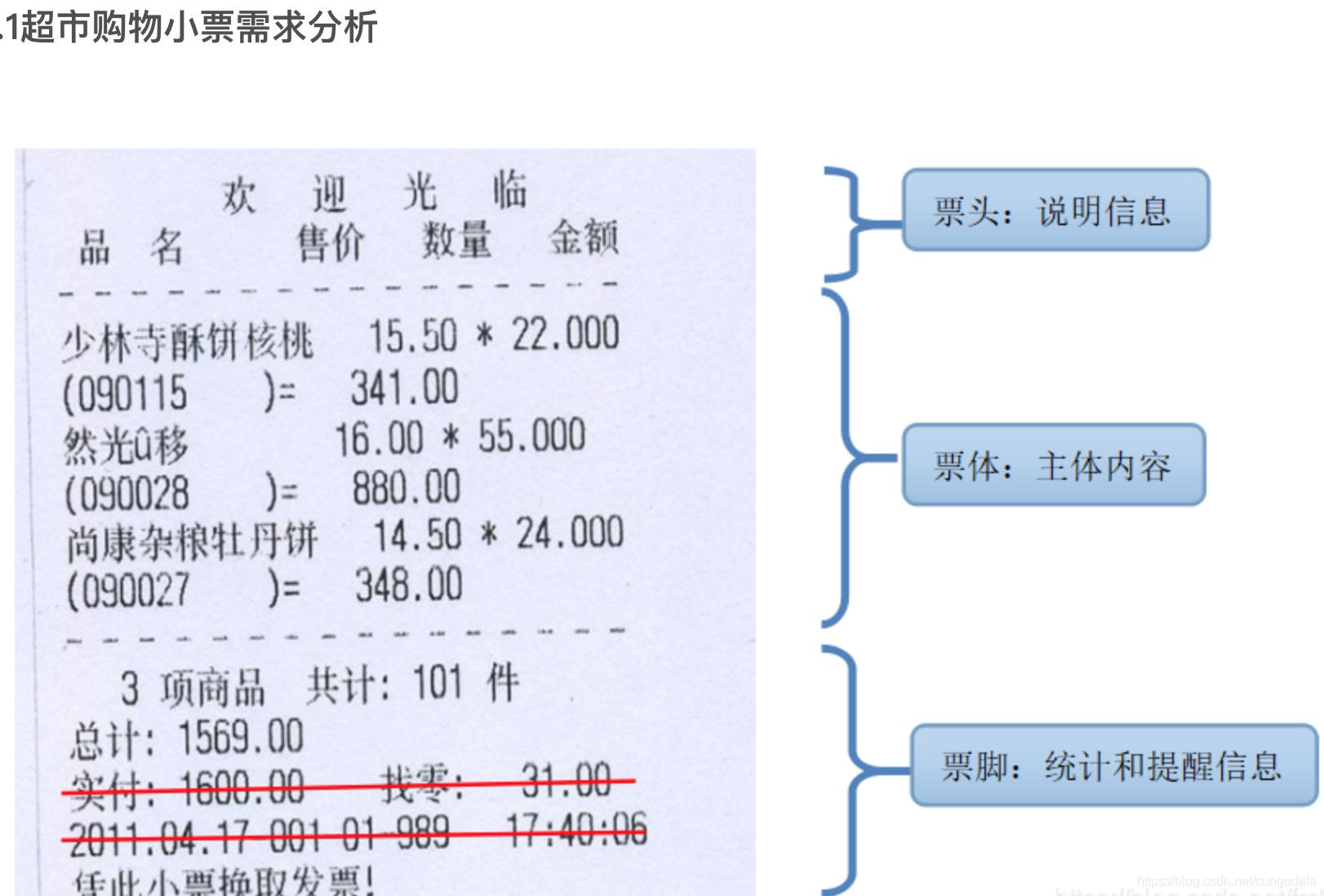
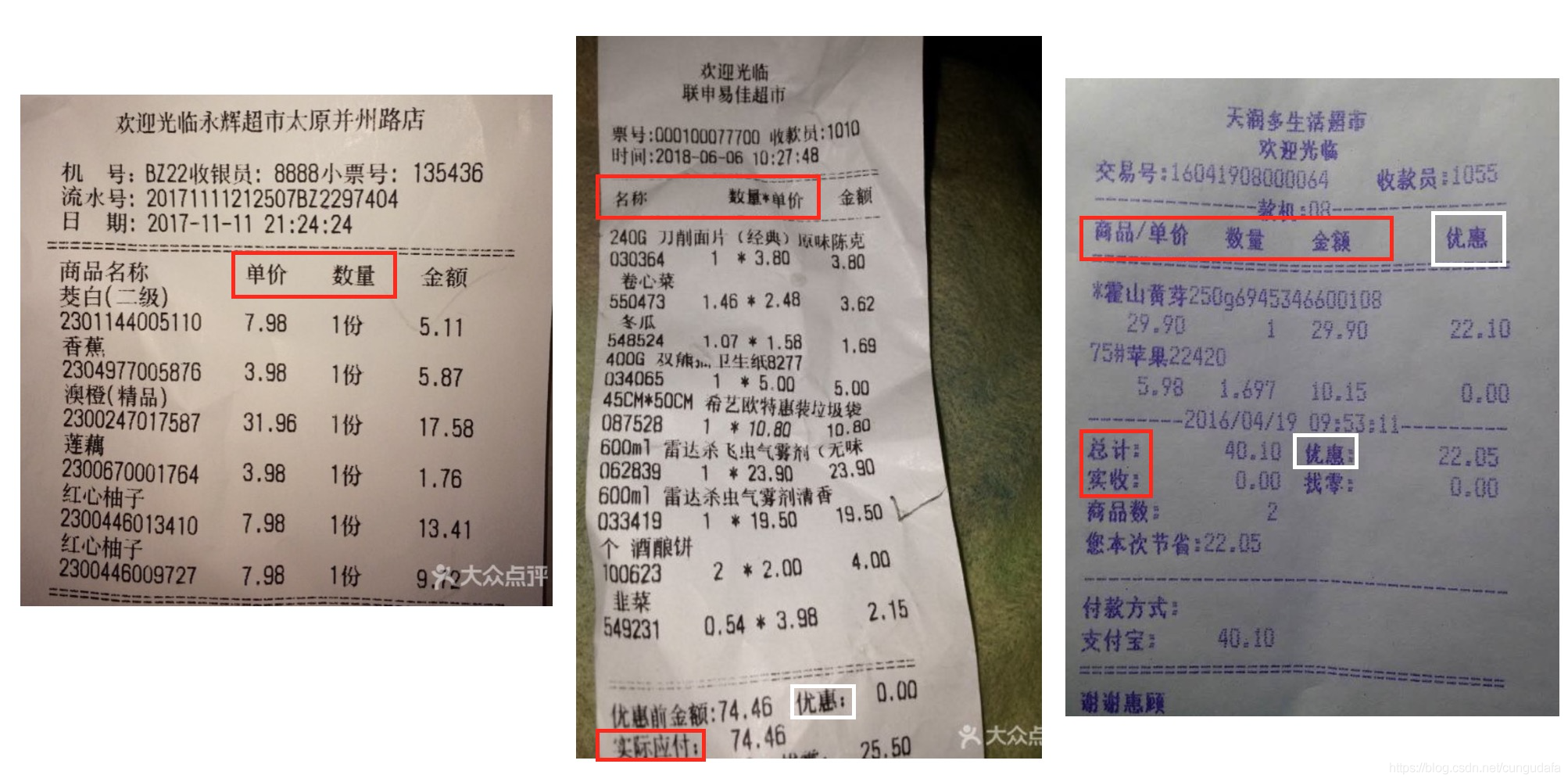
def _isWhat(words,array):
for key,value in array.items():
if key in words:
return key
for batching in value:
if batching in words:
return batching
return '其他'
array = {'糖果':{'棒棒糖','糖'},'蔬菜':{'青菜','瓜'},'饮料':{'果汁','可乐','橙汁','牛奶','奶茶'},'薯片':{'乐事'},'蛋糕':{'糕点',"绿豆糕"}}
resultList = []
for food in wordList:
type = _isWhat(food,array)
resultList.append({food,type})
print(resultList)
文章到这里就结束了,代码的逻辑很简单,需求不复杂;同理:百度的图像识别接口除了小票文字还有物体识别,好比如识别到某一类的物体,根据你的字典去归类区分,可以应用于垃圾分类,物品存储过期提醒,烹饪菜谱推荐等等。
四、源代码
import requests
import base64
import json
import re
'''
通用票据识别
'''
def getToken(AccessKey,SecretKey):
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+AccessKey+'&client_secret='+SecretKey
headers = {
'Content-Type': 'application/json;charset=UTF-8'
}
access_token = ''
response = requests.get(url=host, headers=headers)
if response:
res = response.json()
access_token = res['access_token']
return access_token
def getResult(url,access_token):
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/receipt"
f = open(url, 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
return response.json()
def _isbody(response):
begin,end = 0,999999
beginWords = ["数量","单价","售价","单位"]
endWords = ["总计","总金额","支付","应收","应付","合计"]
for idx in response['words_result']:
for i in beginWords:
if i in idx['words']:
temp = idx['location']['top']
if temp > begin:
begin = temp
for
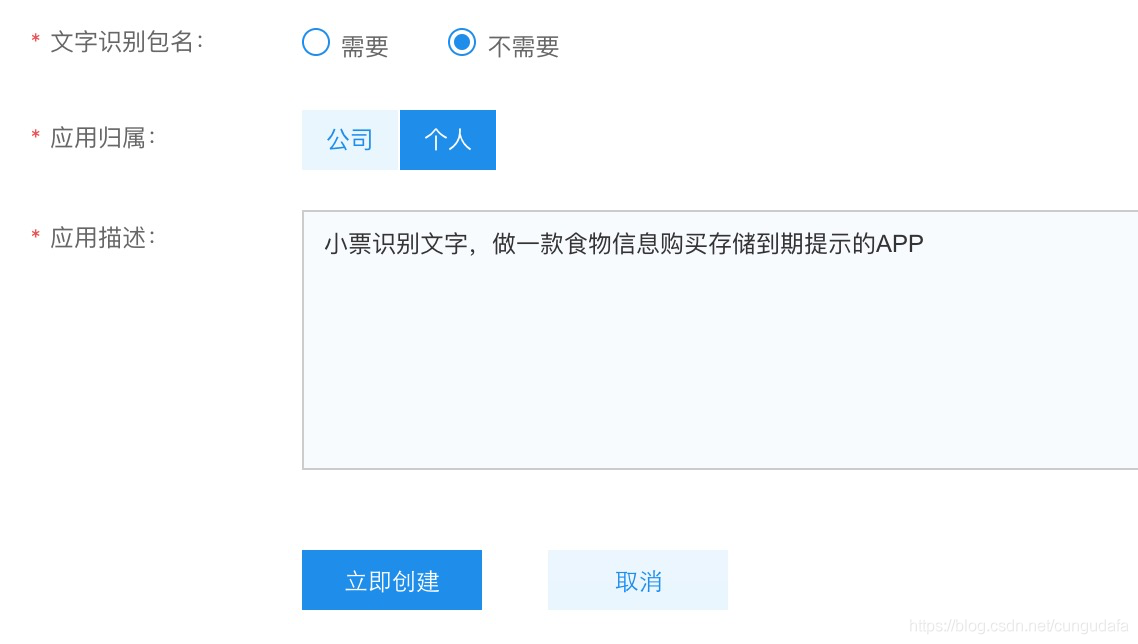
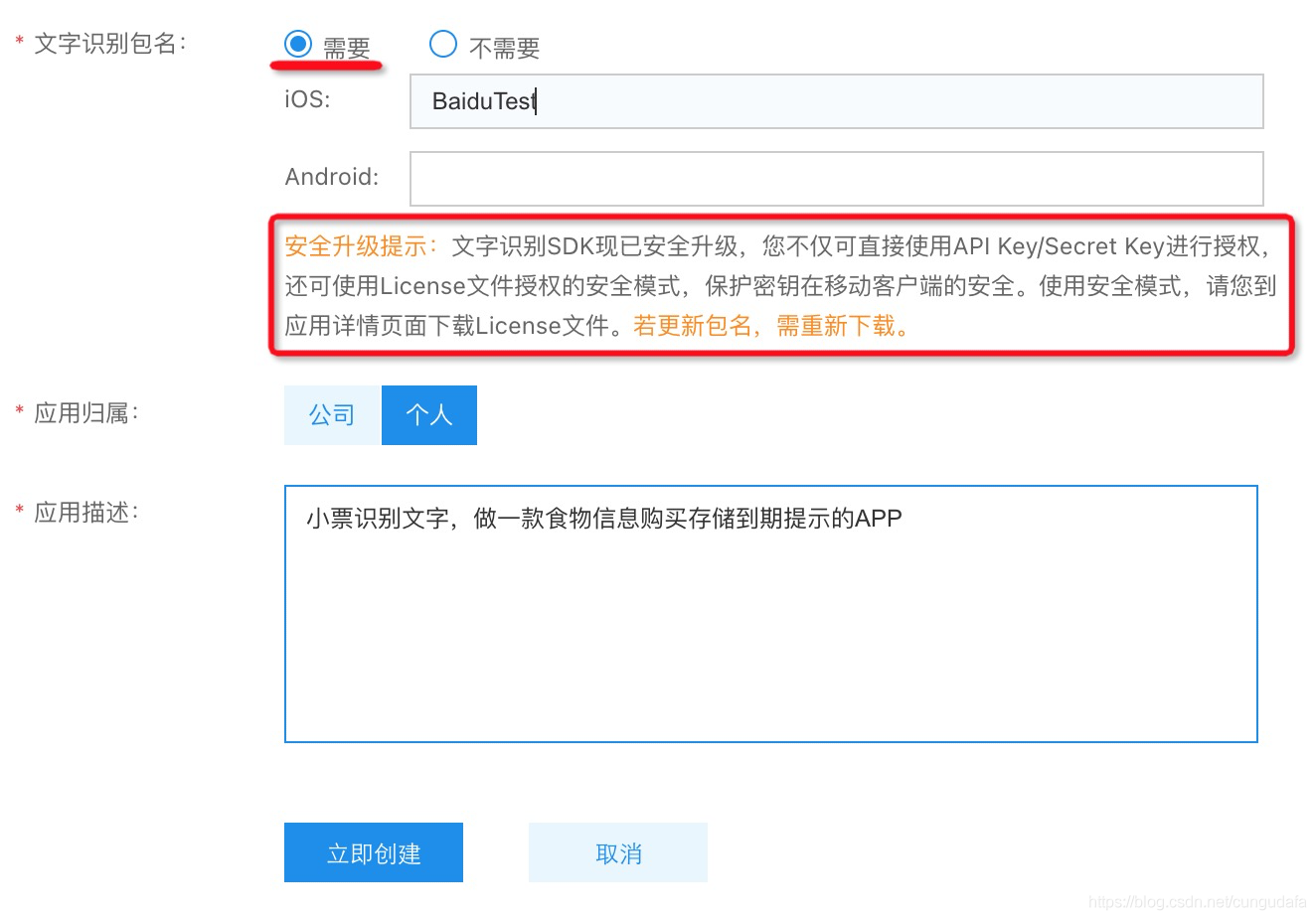

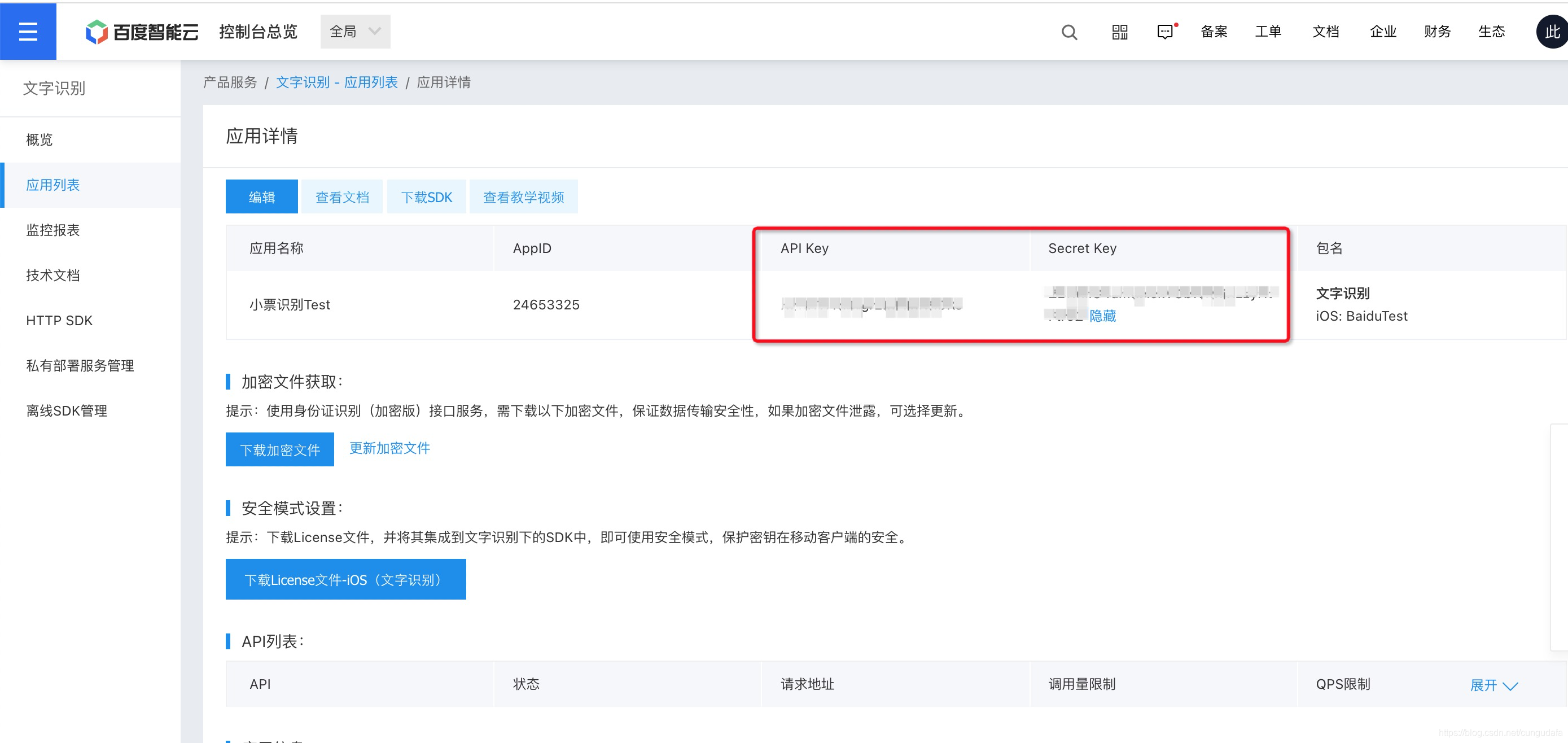


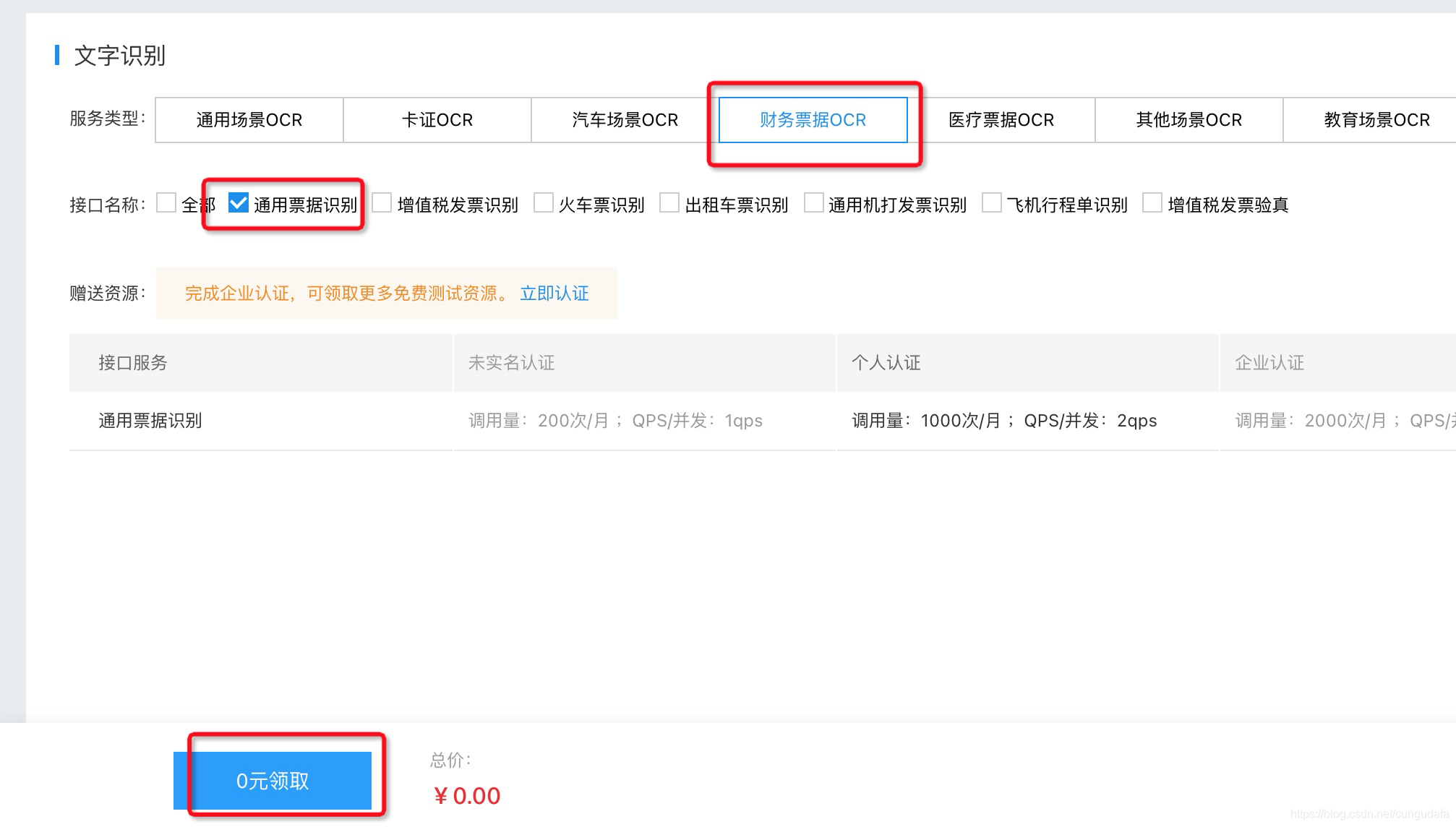
 打印出words可以发现识别内容非常鸡肋:
打印出words可以发现识别内容非常鸡肋: