废话不说多,直接切入主题。
能来到这里的应该都已经发现汽车之家论坛以及一些频道的网页源码是这种:
刚看到这里的时候,想到刚学爬虫时所听说的CSS样式反爬,没错,就是这个。破解方法就是破解其字体文件即可,通过Chrome抓包找到一个.ttf的请求,可以得知这是字体文件为一次单独的请求。在源码中搜索ttf,即可找到ttf字体文件的url。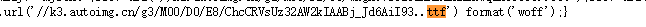
刚开始的想法时构造一个字典,形成映射,后续的爬取工作都使用这个字典,但后来发现这个字体文件并不是一直不变的,用一个页面定期会变,不同的页面也不一致,所以只能取动态的解析字体文件。
要想解析字体文件,首先要能打开,百度了一下,找到一个软件Font-Logic FontCreator,自行下载安装。
打开多个下载的ttf文件发现字体为固定的38个字,如下
每次会变的是字体的标号(字体上的字符串)与位置,且标号可与源码中的css属性形成映射。
现在要想的是,如何让Python识别字体文件----Python三方包 fontTools。该三方包提供了读取与解析字体文件的功能,但是无法直接读取到文字,但我们可以通过其提供的一些方法来解析。
fontTools提供了将ttf文件转成xml文件的方法,用法如下
# -*- coding:utf-8 -*-
from fontTools.ttLib import TTFont
font = TTFont("ChcCRVsUz32AW2kIAABj_Jd6AiI93..ttf")
font.saveXML("a.xml")
查看xml文件,可以看到一些字体的信息,正是勾勒字体的坐标点,一个字体在不同的字体文件中的编码可能不一致,但是勾勒出字体的一些坐标信息肯定会差距很小,所以我们可以获得一个已知的字体坐标集合,以后下载字体后与已有的进行对比就可以很快捷的解析出所有问题,再根据name值替换html源码中的标签。

最终结构化数据抽取结果

代码的实现很简单,有兴趣的可以尝试一下,如果遇到什么问题可以在下方留言。
现已解决所有问题,实现论坛全量爬取。
代码地址:https://gitee.com/wf931202/AutoHomeSpider
需要将overwrite里的连个py文件替换到fonttools包中对应的文件,该版本只能实现单例运行,大规模抓取需要进行一些列优化。
----------------------------------------------------------------------------------------------------------------------------
汽车之家口碑网页版的反爬与上面的不一样,可以采用移动端,字体库也与论坛的有些出入,需要重新生成一个,结果在koubei_font.py内。
?
cs