ШчКЮОіЖЈЮФЕЕБЛДцДЂдкФФИіЗжЦЌ?
shard = hash(routing) % number_of_primary_shards
routing?ЪЧвЛИіПЩБфжЕ,ФЌШЯЪЧЮФЕЕЕФ?_id?,вВПЩвдЩшжУГЩвЛИіздЖЈвхЕФжЕЁЃ?routing?ЭЈЙ§ hash КЏЪ§ЩњГЩвЛИіЪ§зж,ШЛКѓетИіЪ§зждйГ§вд?number_of_primary_shards?(жїЗжЦЌЕФЪ§СП)КѓЕУЕН?грЪ§?ЁЃетИіЗжВМдк?0?ЕН?number_of_primary_shards-1?жЎМфЕФгрЪ§,ОЭЪЧЮвУЧЫљбАЧѓЕФЮФЕЕЫљдкЗжЦЌЕФЮЛжУЁЃPS:жЎЧАПДЦфЫћЕФЮФЕЕ,ЫЕidЪЧЫцЛњзжЗћДЎ,ЕБЪБОЭЛГвЩ~~ здЖЏЩњГЩЕФ ID ЪЧ URL-safeЁЂ Лљгк Base64 БрТыЧвГЄЖШЮЊ20ИізжЗћЕФ GUID зжЗћДЎЁЃ етаЉ GUID зжЗћДЎгЩПЩаоИФЕФ FlakeID ФЃЪНЩњГЩ,етжжФЃЪНдЪаэЖрИіНкЕуВЂааЩњГЩЮЈвЛ ID ,ЧвЛЅЯржЎМфЕФГхЭЛИХТЪМИКѕЮЊСуЁЃ
ЫљгаЕФЮФЕЕ API(?get?ЁЂ?index?ЁЂ?delete?ЁЂ?bulk?ЁЂ?update?вдМА?mget?)ЖМНгЪмвЛИіНазі?routing?ЕФТЗгЩВЮЪ§?,ЭЈЙ§етИіВЮЪ§ЮвУЧПЩвдздЖЈвхЮФЕЕЕНЗжЦЌЕФгГЩфЁЃ
жїЗжЦЌгыИБЗжЦЌШчКЮНЛЛЅ
ЮвУЧПЩвдЗЂЫЭЧыЧѓЕНМЏШКжаЕФШЮвЛНкЕуЁЃ?УПИіНкЕуЖМгаФмСІДІРэШЮвтЧыЧѓЁЃ УПИіНкЕуЖМжЊЕРМЏШКжаШЮвЛЮФЕЕЮЛжУ,ЫљвдПЩвджБНгНЋЧыЧѓзЊЗЂЕНашвЊЕФНкЕуЩЯЁЃ
ЕБЗЂЫЭЧыЧѓЕФЪБКђ, ЮЊСЫРЉеЙИКди,ИќКУЕФзіЗЈЪЧТжбЏМЏШКжаЫљгаЕФНкЕуЁЃ
аТНЈЁЂЫїв§КЭЩОГ§ЮФЕЕ
аТНЈЁЂЫїв§КЭЩОГ§?ЧыЧѓЖМЪЧ?аД?Вйзї,?БиаыдкжїЗжЦЌЩЯУцЭъГЩжЎКѓВХФмБЛИДжЦЕНЯрЙиЕФИББОЗжЦЌ
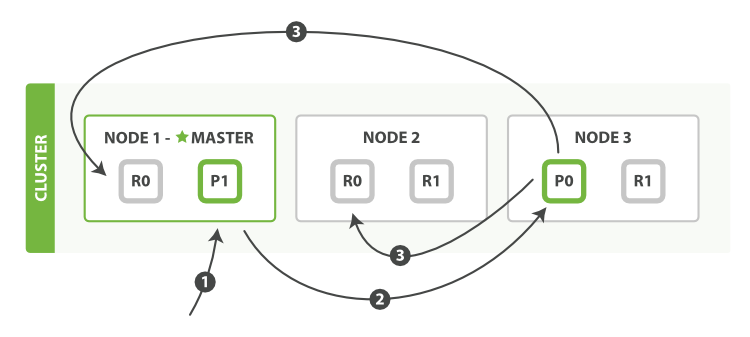
вдЯТЪЧдкжїИБЗжЦЌКЭШЮКЮИББОЗжЦЌЩЯУц?ГЩЙІаТНЈ,Ыїв§КЭЩОГ§ЮФЕЕЫљашвЊЕФВНжшЫГађ:
- ПЭЛЇЖЫЯђ?
Node 1?ЗЂЫЭаТНЈЁЂЫїв§ЛђепЩОГ§ЧыЧѓЁЃ - НкЕуЪЙгУЮФЕЕЕФ?
_id?ШЗЖЈЮФЕЕЪєгкЗжЦЌ 0 ЁЃЧыЧѓЛсБЛзЊЗЂЕН?Node 3`,вђЮЊЗжЦЌ 0 ЕФжїЗжЦЌФПЧАБЛЗжХфдк `Node 3?ЩЯЁЃ Node 3?дкжїЗжЦЌЩЯУцжДааЧыЧѓЁЃШчЙћГЩЙІСЫ,ЫќНЋЧыЧѓВЂаазЊЗЂЕН?Node 1?КЭ?Node 2?ЕФИББОЗжЦЌЩЯЁЃвЛЕЉЫљгаЕФИББОЗжЦЌЖМБЈИцГЩЙІ,?Node 3?НЋЯђаЕїНкЕуБЈИцГЩЙІ,аЕїНкЕуЯђПЭЛЇЖЫБЈИцГЩЙІЁЃ
дкПЭЛЇЖЫЪеЕНГЩЙІЯьгІЪБ,ЮФЕЕБфИќвбОдкжїЗжЦЌКЭЫљгаИББОЗжЦЌжДааЭъГЩ,БфИќЪЧАВШЋЕФЁЃ
ШЁЛивЛИіЮФЕЕ
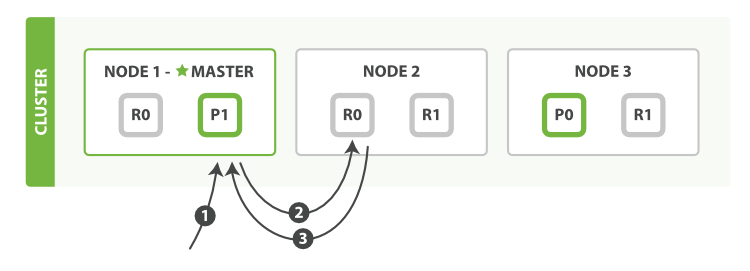
вдЯТЪЧДгжїЗжЦЌЛђепИББОЗжЦЌМьЫїЮФЕЕЕФВНжшЫГађ:
1ЁЂПЭЛЇЖЫЯђ?Node 1?ЗЂЫЭЛёШЁЧыЧѓЁЃ
2ЁЂНкЕуЪЙгУЮФЕЕЕФ?_id?РДШЗЖЈЮФЕЕЪєгкЗжЦЌ?0?ЁЃЗжЦЌ?0?ЕФИББОЗжЦЌДцдкгкЫљгаЕФШ§ИіНкЕуЩЯЁЃ дкетжжЧщПіЯТ,ЫќНЋЧыЧѓзЊЗЂЕН?Node 2?ЁЃ
3ЁЂNode 2?НЋЮФЕЕЗЕЛиИј?Node 1?,ШЛКѓНЋЮФЕЕЗЕЛиИјПЭЛЇЖЫЁЃ
дкДІРэЖСШЁЧыЧѓЪБ,аЕїНсЕудкУПДЮЧыЧѓЕФЪБКђЖМЛсЭЈЙ§ТжбЏЫљгаЕФИББОЗжЦЌРДДяЕНИКдиОљКтЁЃ
дкЮФЕЕБЛМьЫїЪБ,вбОБЛЫїв§ЕФЮФЕЕПЩФмвбОДцдкгкжїЗжЦЌЩЯЕЋЪЧЛЙУЛгаИДжЦЕНИББОЗжЦЌЁЃ дкетжжЧщПіЯТ,ИББОЗжЦЌПЩФмЛсБЈИцЮФЕЕВЛДцдк,ЕЋЪЧжїЗжЦЌПЩФмГЩЙІЗЕЛиЮФЕЕЁЃ вЛЕЉЫїв§ЧыЧѓГЩЙІЗЕЛиИјгУЛЇ,ЮФЕЕдкжїЗжЦЌКЭИББОЗжЦЌЖМЪЧПЩгУЕФЁЃ
ОжВПИќаТЮФЕЕ
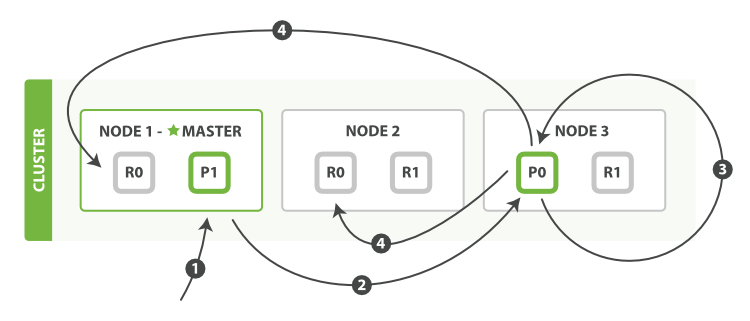
- ПЭЛЇЖЫЯђ?
Node 1?ЗЂЫЭИќаТЧыЧѓЁЃ - ЫќНЋЧыЧѓзЊЗЂЕНжїЗжЦЌЫљдкЕФ?
Node 3?ЁЃ Node 3?ДгжїЗжЦЌМьЫїЮФЕЕ,аоИФ?_source?зжЖЮжаЕФ JSON ,ВЂЧвГЂЪджиаТЫїв§жїЗжЦЌЕФЮФЕЕЁЃ ШчЙћЮФЕЕвбОБЛСэвЛИіНјГЬаоИФ,ЫќЛсжиЪдВНжш 3 ,ГЌЙ§?retry_on_conflict?ДЮКѓЗХЦњЁЃ- ШчЙћ?
Node 3?ГЩЙІЕиИќаТЮФЕЕ,ЫќНЋаТАцБОЕФЮФЕЕВЂаазЊЗЂЕН?Node 1?КЭ?Node 2?ЩЯЕФИББОЗжЦЌ,жиаТНЈСЂЫїв§ЁЃ вЛЕЉЫљгаИББОЗжЦЌЖМЗЕЛиГЩЙІ,?Node 3?ЯђаЕїНкЕувВЗЕЛиГЩЙІ,аЕїНкЕуЯђПЭЛЇЖЫЗЕЛиГЩЙІЁЃ
ЖрЮФЕЕФЃЪН
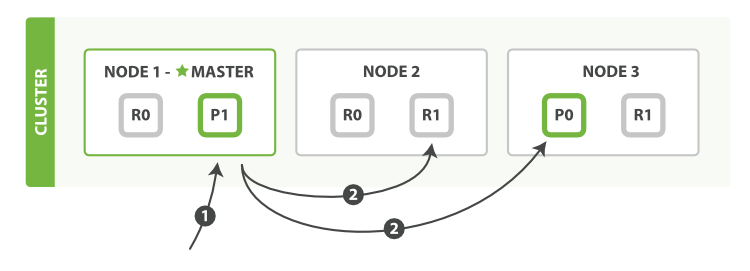
- ПЭЛЇЖЫЯђ?
Node 1?ЗЂЫЭ?mget?ЧыЧѓЁЃ Node 1?ЮЊУПИіЗжЦЌЙЙНЈЖрЮФЕЕЛёШЁЧыЧѓ,ШЛКѓВЂаазЊЗЂетаЉЧыЧѓЕНЭаЙмдкУПИіЫљашЕФжїЗжЦЌЛђепИББОЗжЦЌЕФНкЕуЩЯЁЃвЛЕЉЪеЕНЫљгаД№ИД,?Node 1?ЙЙНЈЯьгІВЂНЋЦфЗЕЛиИјПЭЛЇЖЫЁЃ
?ЪЙгУ?bulk?аоИФЖрИіЮФЕЕ
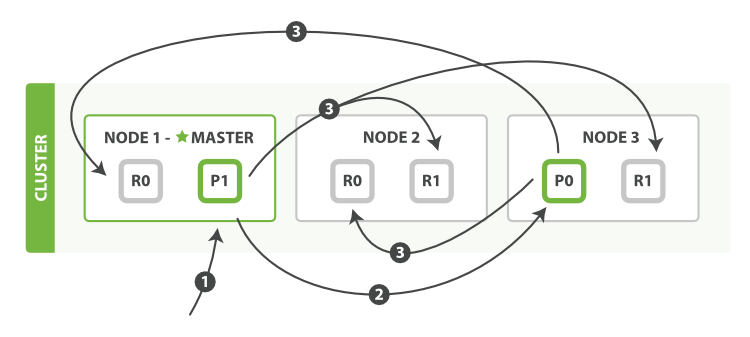
?
bulk?API?АДШчЯТВНжшЫГађжДаа:
- ПЭЛЇЖЫЯђ?
Node 1?ЗЂЫЭ?bulk?ЧыЧѓЁЃ Node 1?ЮЊУПИіНкЕуДДНЈвЛИіХњСПЧыЧѓ,ВЂНЋетаЉЧыЧѓВЂаазЊЗЂЕНУПИіАќКЌжїЗжЦЌЕФНкЕужїЛњЁЃ- жїЗжЦЌвЛИіНгвЛИіАДЫГађжДааУПИіВйзїЁЃЕБУПИіВйзїГЩЙІЪБ,жїЗжЦЌВЂаазЊЗЂаТЮФЕЕ(ЛђЩОГ§)ЕНИББОЗжЦЌ,ШЛКѓжДааЯТвЛИіВйзїЁЃ вЛЕЉЫљгаЕФИББОЗжЦЌБЈИцЫљгаВйзїГЩЙІ,ИУНкЕуНЋЯђаЕїНкЕуБЈИцГЩЙІ,аЕїНкЕуНЋетаЉЯьгІЪеМЏећРэВЂЗЕЛиИјПЭЛЇЖЫЁЃ
bulk?API ЛЙПЩвддкећИіХњСПЧыЧѓЕФзюЖЅВуЪЙгУ?consistency?ВЮЪ§,вдМАдкУПИіЧыЧѓжаЕФдЊЪ§ОнжаЪЙгУ?routing?ВЮЪ§ЁЃ
cs