一直以来,无状态服务(Stateless Service)在架构设计中都被当作铁律,因为无状态的服务很容易横向扩展,只需要在负载均衡之后增加节点就可以处理更多请求。但是,无状态服务也不是完美无缺的,其中一个缺点就是和数据层之间的请求延迟,以及为了解决这种延迟增加缓存所带来的复杂性和一致性问题。
有没有想过引入“有状态服务”(stateful service)来解决问题?在网上查一查,你会发现很少有人提及有状态服务,Wikipedia甚至都没有这个词条。
Caitiff McCaffrey是Twitter的资深工程师,她在StrangeLoop大会上发表了主题为“构建可扩展的有状态服务”的演讲,不但厘清了有状态服务的基本理念,也列举了微软、Facebook以及Uber等公司使用有状态服务的多个案例作为佐证。也许她的演讲可以为我们带来一些启示。
在读下去之前,有一些基本的分布式系统概念是需要理解的,如果你对这些概念还不熟悉,不妨自行Google一下:
- Sticky Session
- Data Locality
- CAP Theorem
- AP/CP System
- Cluster Membership
- Consensus Protocol
- Gossip protocols
- Consistent Hashing
- Back Pressure
- DHT(Distributed Hashtable)
- StopTheWorld(Garbage Collection)
我们先来回顾一下众所周知的无状态服务:把所有数据放在数据库中,就可以在服务层横向扩展;但是当流量不断上升,总有一天会突破数据库处理能力的极限,于是我们对数据库做分片(sharding),或者转向NoSQL数据库,希望通过牺牲强一致性来提高可用性。这时,不可避免地,一些数据库的逻辑就要渗透到应用层中。
另一方面,我们考虑一下无状态服务的过程:用户向服务层发送请求,服务层处理请求的节点A从数据库加载数据,返回给用户,当用户发下一个请求的时候,可能会分配到另一个服务节点B,节点B需要去数据库重新加载数据,此时A节点的数据被抛弃。这个反复加载数据的过程其实很浪费,尤其对于频繁交互的应用(比如游戏,和一些重交互的网络应用)来说尤其如此。
Stateful的好处
首先要强调的是,Stateful并不是灵丹妙药,大多数场景下,我们仍然需要无状态的服务以及横向扩展能力。但有状态服务的确有两个明显的优点:
- Data Locality(数据本地化)。在有状态服务中,当客户端第一次发出请求时,服务仍然需要到数据库加载数据,但是自此以后,数据将会保存在节点本地,这个客户端下一个请求必须由同一个节点处理,这种模式就节省了很多数据网络传输。即使数据库服务已经停止,服务节点仍然能够独立处理请求。
图 - 有状态服务有更高的可用性(A)和更强的一致性(C)。在CAP三个属性中,我们只能选择CP系统或者AP系统,如果我们选择AP,就要在一致性上作出让步。但是这个让步本身也有程度上的差别,对于有状态的服务来说,由于采用了Sticky Session(即一个用户的数据都在一个固定节点上),一致性会更强。见下图(对于其中一致性的各种级别请自行查阅):
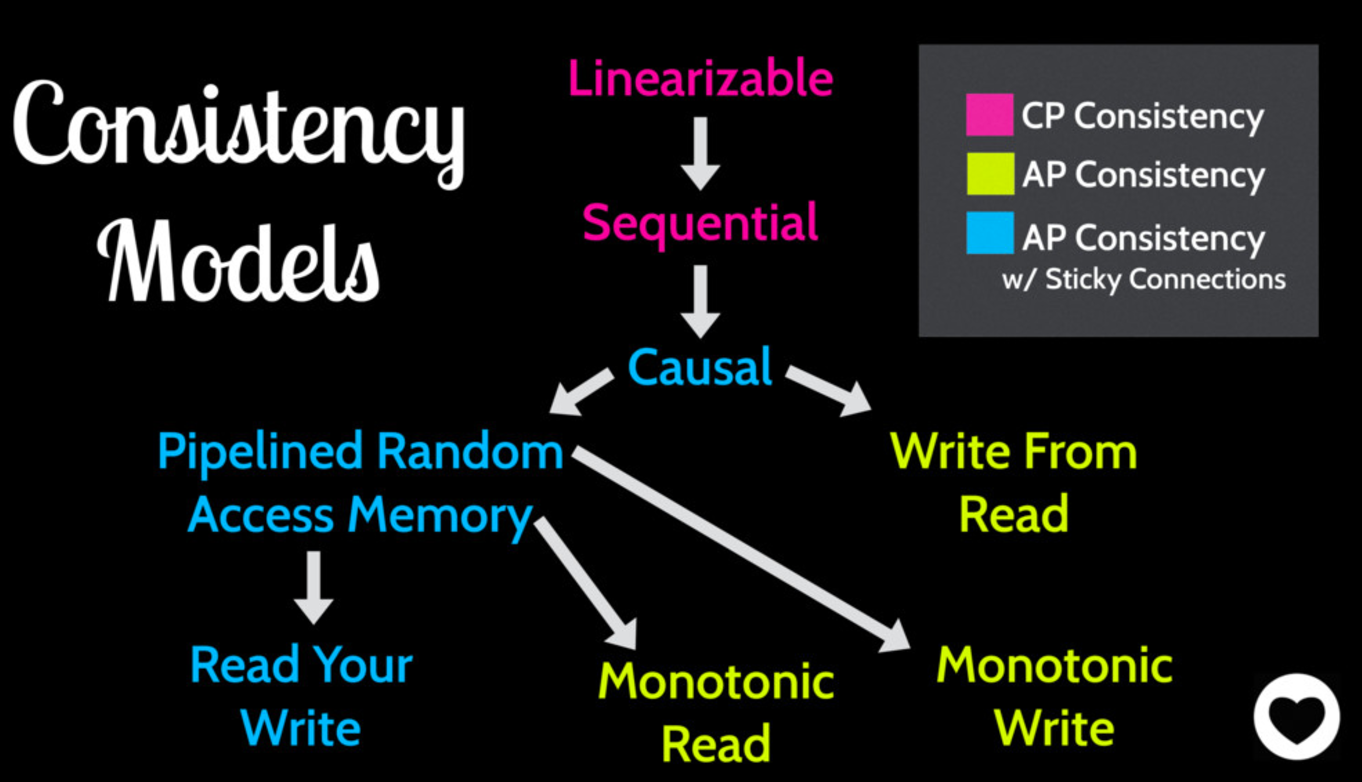
除此以外,Sticky Session还有一个工程上的好处,对于开发分布式系统的工程师来说,因为不需要担心数据加载到不同节点、缓存层次带来的一致性问题,一个用户只和一台服务器交互,这个模型更加容易理解,更容易编程实现。
怎样实现?
如何实现Sticky Session?
第一种显而易见的方法就是长连接(HTTP或者TCP),这个方式简单易行,但是缺点在于不稳定,一旦连接断开,Sticky Session也就结束了。另外,由于各个用户产生的负载并不相同,有一些节点会承受过高负载(热节点),因此,必须实现反向压力(Back Pressure),当一个节点无法承受负载时,可以有选择性地断开一些连接,让一些用户连接到其他轻负载节点上。
另一种更好的办法就是实现集群内部路由。客户端仍然可以连接任何一个节点,由这个节点负责把请求路由到含有用户数据的节点上。为了实现这种方案,需要集群具有两种能力:
- 集群归属(Cluster Membership) - 集群中有哪些节点?生存状态如何?
- 负载分配(Workload Distribution)
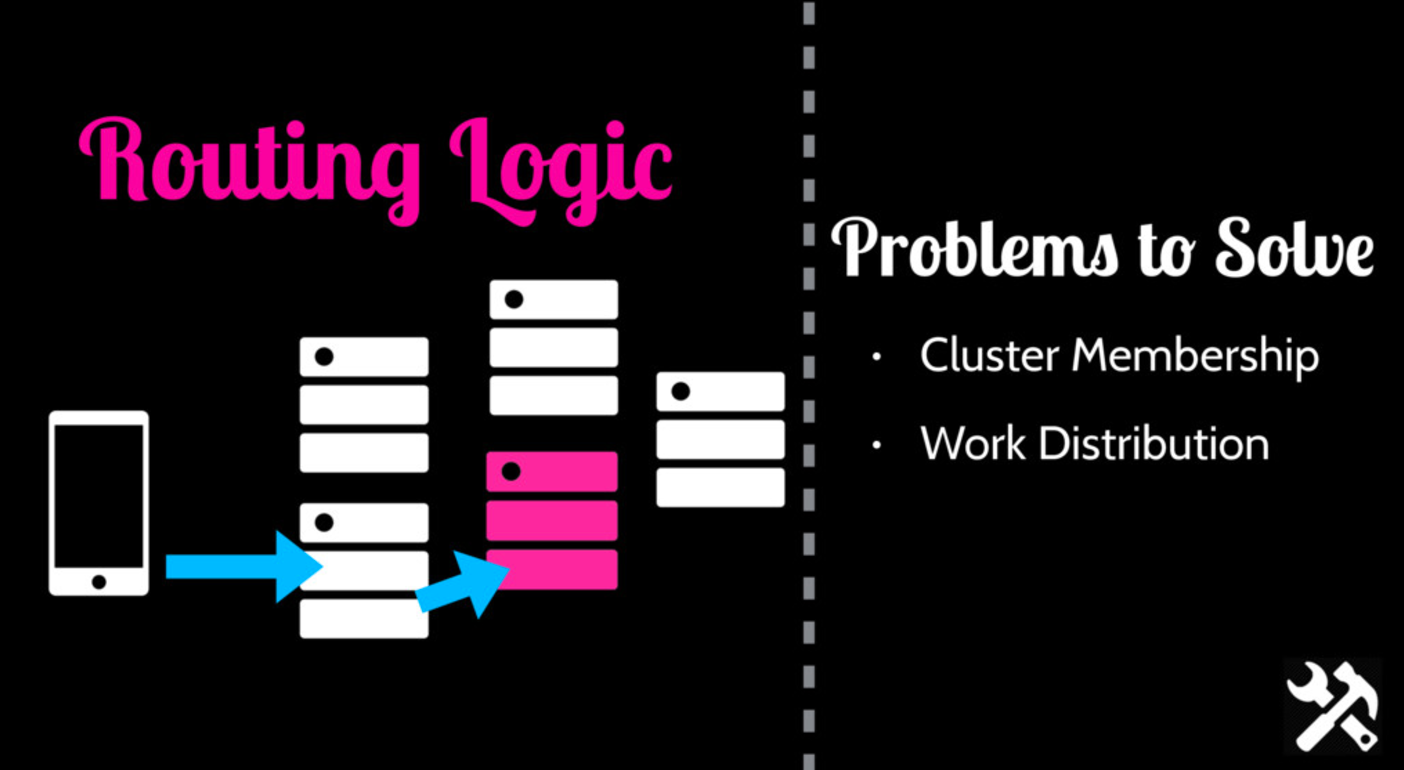
集群归属
Membership可以有几种类型:静态、Gossip以及一致性(Consensus)系统。
- 静态系统最为简单,可以用一个配置文件来维护各个节点的地址,然后把这个文件部署在集群中每个节点上。缺点也显而易见:运维困难,难于扩展。当节点宕机或者增加节点的时候,都要更新配置,重启整个集群。对于需要保证高可用的服务来说,这是不可接受的。动态的集群归属能增加运维的灵活性。
- Gossip协议就是让各个节点之间互相散播消息来维护集群状态,每个节点都有自己独立的World State,并根据接受的消息更新。在达到稳定状态以后,所有的节点会拥有一致的World State。但是当出现网络中断、增加、减少节点的时候,节点本地的World State就会出错。这涉及一个设计上的取舍:因为不需要一致性协议的协调过程,这个方法的可用性更高,但是代价就是代码需要处理路由到错误节点带来的不确定性。
- 一致性协议。当前有很多开源的一致性协议实现,比如ZooKeeper/Etcd等。一致性系统能保证集群归属信息的准确和及时更新,但是问题在于协调的效率较低。所以除非绝对必要,不建议采用这种方案。
负载分配
把工作分配给集群中的节点大概有三种方式:
1. 随机分配给任意节点。用这种方式,写请求可以由任意节点处理,但是读请求需要向每一个节点发出查询。严格来说,这不是Sticky Session,但是实际中往往很有效。
2. 一致性Hash。可以通过SessionID或者UserID的Hash值来决定处理节点。一致性Hash会把请求ID映射到一个圆上,在圆上顺时针移动,遇到第一个节点就是处理请求的节点(具体实现请查阅Wikipedia)。这种分配方式是确定性的,带来的问题就是热节点:很多请求可能被分配到一个节点上,导致节点过载,由于确定性的分配方式,不能把负载转移到其他节点。所以,每台节点的计算资源都要留足余量(headroom),以降低过载的可能性。

3. 分布式Hashtable。用一个分布式的Hashtable来维护、查询请求分配的节点,用这种方式,当一个节点宕机或者过载的时候,可以更改Hashtable把负载重新分配到其他节点。
真实案例
Facebook Scuba

Scuba是Facebook实现的一个分布式内存数据库。它使用了静态的集群归属,负载分配使用了随机的分配策略,读请求需要查询集群中的每个节点。因为在真实环境中,不可能保证所有节点都同时在线,所以用户的读请求不一定能返回所有数据,他们的做法是返回查询到的数据,以及数据的完整程度(百分比),由客户端决定这些数据是否足够。
Uber Ringpop

Ringpop是一个基于node的应用层分片协议。仔细考虑一下Uber的服务,你发现它很适合根据地理位置分片处理,把一个位置用户的请求发送到一个固定的节点上,并在这个节点上维护行程信息。Ringpop使用Gossip协议维护集群归属,并使用一致性Hash来分配负载。为了避免热节点问题,必须保证每个节点有足够处理能力。
Microsoft Orleans
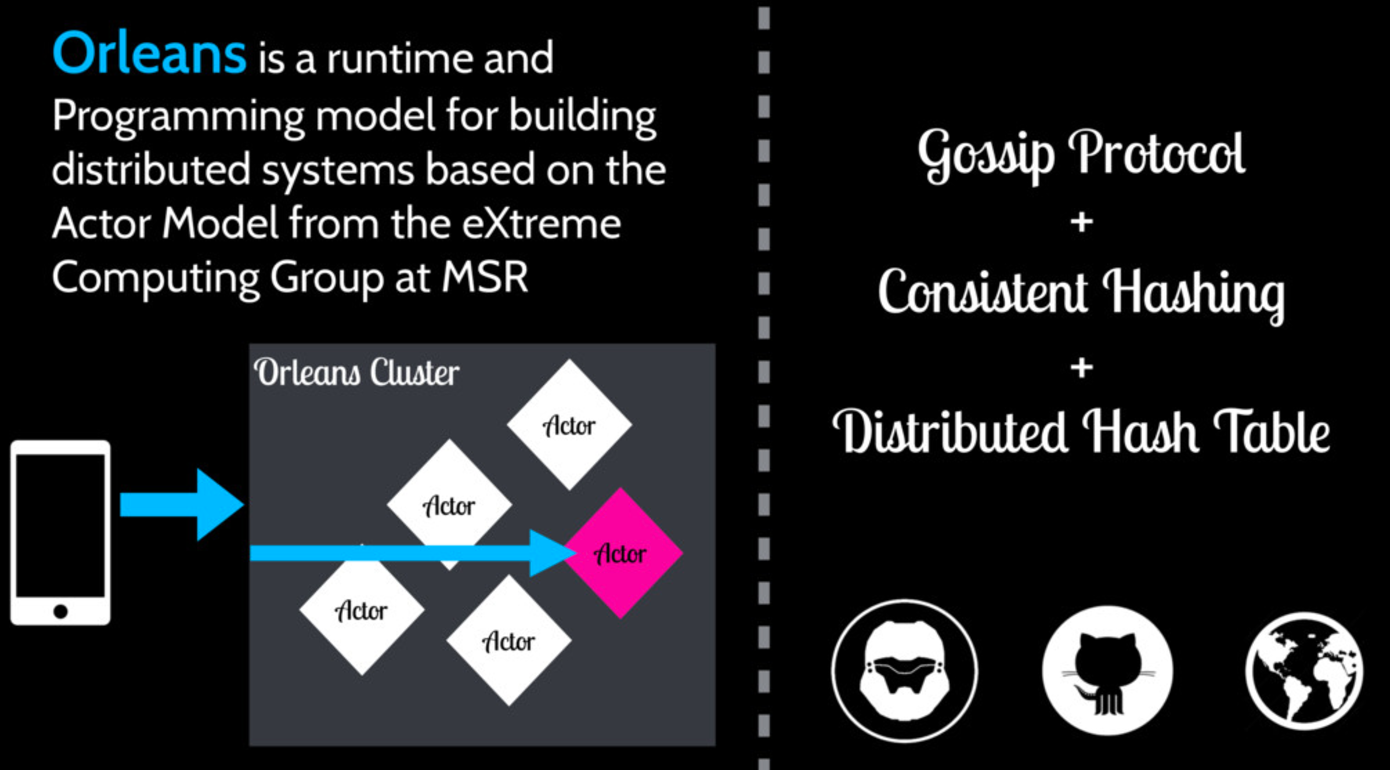
?
Orleans是一个基于Actor的分布式系统运行时,Halo 4这个游戏就是基于Orleans开发的。Orleans采用Gossip协议维护归属信息,负载分配采用了一致性Hash和DHT相结合的方式。用户的ID经过一致性Hash映射到一个节点,这个节点保存了这个用户对应的DHT,再查询DHT定位到处理用户请求的Actor位置。对这个项目感兴趣的,尤其是做游戏开发的同学可以关注一下这个开源项目,可以参见文末参考链接。
需要注意的问题
不受限的数据结构
注意不要使用不受限的队列和内存数据结构,有状态的服务更容易出现OutOfMemory的问题,或者垃圾回收器会StopTheWorld。在无状态的服务中,很多数据结构都是伴随请求的生命周期产生和消失的,内存在请求结束以后就会被垃圾回收,所以即使段时间内存不足,也不会有很大影响。但是在有状态服务中,很多session的时间很长,会累积大量数据,代码必须对这种可能性加以防范。
内存管理
同上一条,因为很多数据会长时间驻留内存,会给垃圾回收机制带来很多影响:对于垃圾回收器来说,回收很老的一代(Generation)内存代价是比较大的。你需要对垃圾回收器做性能的调优,或者干脆使用不需要GC的技术(比如C++)。
重新载入数据
大部分时候,有状态服务是不需要重载数据的。有三个例外:
- 第一次连接。这时候往往加载数据很耗时,所有数据要从数据库读出,所以为了用户体验,第一个请求不要加载太多数据;另外,即使第一个请求加载数据超时,也不要停止加载,因为客户端总会再次连接,而第二次连接的响应速度会很快,因为数据已经读入本地内存。
- 崩溃恢复,这时候可能需要预加载一些数据。
- 部署新代码,每次部署新代码需要重启服务并加载所有数据。对于使用确定性负载分配的方案,这会是一个问题。 这里值得一提的是Facebook部署新代码时采取的一个聪明的技巧。Facebook的服务重启以后加载数据,由于数据量巨大,可能需要几个小时的时间,这对于快速上线新代码非常不利。他们采用了一个方法,分离了内存和进程的生命周期:在部署新代码的时候,原进程停止服务,开始把数据转移到共享内存中,然后退出,在启动新进程以后,可以直接拷贝共享内存到程序中,在几分钟内快速开始提供服务。
总结
- 关于集群归属和负载分配的策略,并没有一个“最好”的方案,需要根据需求做出权衡。
- 尽管Stateful是一个比较新的概念,没有必要害怕尝试,很多知名企业都有成功经验。
- 多读论文。其实关于Stateful的很多理念并不是最近发明的,这个演讲中很多方案都来自于60/70年代的论文,都是已经解决的问题,不要重复发明轮子。
参考
https://www.youtube.com/watch?v=H0i_bXKwujQ
CaitieM20/Talks
Making the Case for Building Scalable Stateful Services in the Modern Era - High Scalability -
The Case for Building Scalable Stateful Services
https://research.facebook.com/publications/456106467831449/scuba-diving-into-data-at-facebook/
uber/ringpop-node
Orleans - Virtual Actors - Microsoft Research
dotnet/orleans
Creating scalable backends for games using open source Orleans framework
cs