- Tomcatϵ������ר��:https://blog.csdn.net/hancoder/category_11180472.html
- 0 sevlet��֪ʶ,������Ŀ¼����
- 1 tomcat�İ�װ��Ŀ¼�ṹ:https://blog.csdn.net/hancoder/article/details/106765035
- 2 tomcatԴ�뻷���: https://blog.csdn.net/hancoder/article/details/113064325
- tomcat�ܹ�:https://blog.csdn.net/hancoder/article/details/118466983
- 3 tomcat�ܹ������:https://blog.csdn.net/hancoder/article/details/113065917
- 4 tomcatԴ�����:https://blog.csdn.net/hancoder/article/details/113062146
- 5 tomcat����:https://blog.csdn.net/hancoder/article/details/113065948
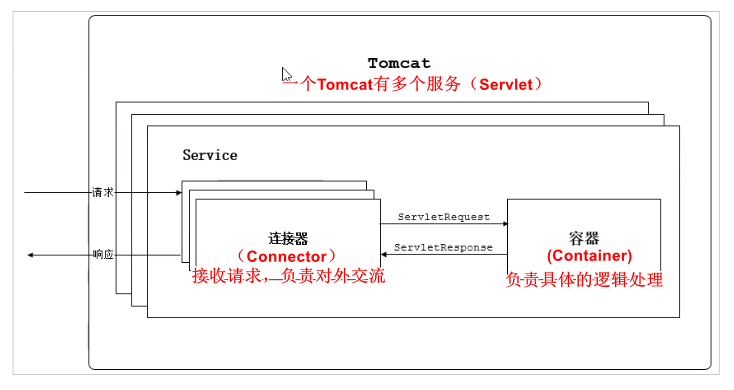
һ��tomcat�ṹ
tomcat���������:
- ������:����Socket����,��������,���������ֽ�����Request��Response�����ת����
- servlet����:���غ���Servlet,�Լ����崦��Request����
��ƪ����https://blog.csdn.net/hancoder/article/details/113065917
���ܹ�,tomcat������ж��service
ÿ��service�����ж��������
ע����������,����������,��������ȡ���Ӻ�����,�������������п϶���
�������������Ĺ�ϵ
���������ڻ�ȡ����,��tcpЭ���װ��http,����request����,Ȼ������������request����ת��servlet request����,��������
catalina����servlet container����coyote�����������ķ�װ
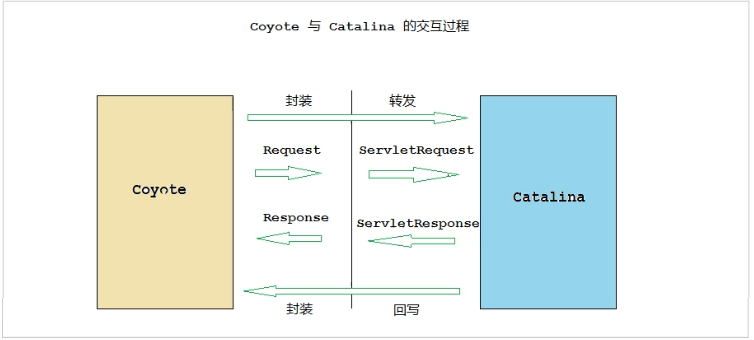
����������:Coyote
Coyote ������,��ԭ��(Ȯ�ƶ���,�ֲ��ڱ���); Ӣ[ka????ti]
�ⲿ�ֻ��ǵý��ǰƪ�����Ķ�:https://blog.csdn.net/hancoder/article/details/118466983
1������
Coyote ��Tomcat�����������ܳ�,����Ҫ����tomcat���뾭����������
ÿ����������Դ����Ҳ����ΪprotocolHandler(Э�鴦����),Դ�����кܶ�Э�鴦����,ProtocolHandlerֻ�ǽӿ�,����ʵ�����Ժ����
����Ļ���㿴��,����ν��
Coyote ��װ�˵ײ������ͨ��(Socket ������Ӧ����),ΪCatalina �����ṩ��ͳһ�Ľӿ�,ʹCatalina ��������������Э�鼰IO������ʽ��ȫ���Coyote ��Socket ����ת����װΪ Request ����,����Catalina �������д���,����������ɺ�, Catalina ͨ��Coyote �ṩ��Response �����д������� ��
Coyote ��Ϊ������ģ��,ֻ�������Э���IO����ز���, ��Servlet �淶ʵ��û��ֱ�ӹ�ϵ,��˼����� Request �� Response ����Ҳ��δʵ��Servlet�淶��Ӧ�Ľӿ�, ������Catalina �н����ǽ�һ����װΪServletRequest�� ServletResponse��
2��IOģ����Э��
��Coyote�� , Tomcat֧�ֵĶ���I/Oģ�ͺ�Ӧ�ò�Э��,���������ЩIOģ�ͺ�Ӧ�ò�Э��,�뿴�±�:
Tomcat ֧�ֵ�IOģ��
| IOģ�� | ���� |
|---|
| BIO | ��8.5/9.0 �汾��,�ѱ��Ƴ� |
| NIO | ������I/O,����Java NIO���ʵ�֡� |
| NIO2 | �첽I/O,����JDK 7���µ�NIO2���ʵ�֡� |
| APR | ����Apache����ֲ���п�ʵ��,��C/C++��д�ı��ؿ⡣���ѡ��÷���,��Ҫ������װAPR�⡣ |
�� 8.0 ֮ǰ , Tomcat Ĭ�ϲ��õ�I/O��ʽΪ BIO , ֮���Ϊ NIO�� ���� NIO��NIO2���� APR, �����ܷ��������������BIO�� �������APR, �������Դﵽ Apache HTTP Server ��Ӱ�����ܡ�
Tomcat ֧�ֵ�Ӧ�ò�Э�� :
| Ӧ�ò�Э�� | ���� |
|---|
| HTTP/1.1 | ���Ǵ�WebӦ�ò��õķ���Э�顣 |
| AJP | ���ں�Web����������(��Apache),��ʵ�ֶԾ�̬��Դ���Ż��Լ���Ⱥ����,��ǰ֧��AJP/1.3�� |
| HTTP/2 | HTTP 2.0����ȵ�������Web���ܡ���һ��HTTPЭ�� , ��8.5�Լ�9.0�汾֮��֧�֡� |
ʵ����
ͨ��Э���ͨ�ŷ�ʽ�����,���ǿ����ְ��������ֵø�ϸ��,Ҳ����Tomcat����6��ʵ����
Http11Protocol:11������http1.1Http11NioProtocol- Http11Nio2Protocol
- AjpNioProtocol
- AjpAprProtocol
- AjpNio2Protocol
tomcat��Ĭ������ʱ,Ҳ�ǿ�����2��������,ÿ���������������ô�����ͬ��Э�顣��ͼ
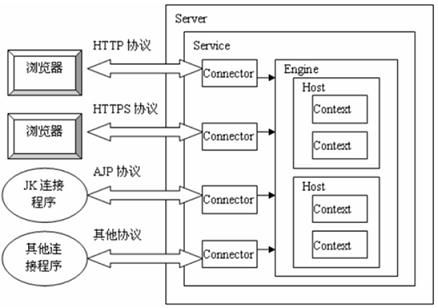
TomcatΪ��ʵ��֧�ֶ���I/Oģ�ͺ�Ӧ�ò�Э��,һ���������ܶԽӶ��������,�ͺñ�һ�������ж���š����ǵ������������������������ܶ����ṩ����,��Ҫ��������װ�������ܹ���,��װ������������Service�������������ע��,Service����û����ʲô��Ҫ������,ֻ������������������������һ��,��������װ��һ��Tomcat�ڿ����ж��Service,���������Ҳ�dz�������ԵĿ��ǡ�ͨ����Tomcat�����ö��Service,����ʵ��ͨ����ͬ�Ķ˿ں�������ͬһ̨�����ϲ���IJ�ͬӦ�á�
3�����������
0) ProtocolHandler
Connector����ʹ��ProtocolHandler�����������,��ͬ��ProtocolHandler������ͬ����������,����:Http11Protocolʹ�õ�����ͨBIO Socket�����ӵ�,Http11NioProtocolʹ�õ���NioSocket�����ӵġ�
����ProtocolHandler�ɰ�������������:Endpoint��Processor��Adapter��
(1)Endpoint���������ײ�Socket����������,Processor���ڽ�Endpoint���յ���Socket��װ��Request,Adapter���ڽ�Request����Container���о���Ĵ�����
(2)Endpoint�����Ǵ����ײ��Socket��������,���Endpoint������ʵ��TCP/IPЭ���,��Processor����ʵ��HTTPЭ���,Adapter���������䵽Servlet�������о���Ĵ�����
(3)Endpoint�ij���ʵ��AbstractEndpoint���涨����Acceptor��AsyncTimeout�����ڲ����һ��Handler�ӿڡ�
- Acceptor���ڼ�������,
- AsyncTimeout���ڼ���첽Request�ij�ʱ,
- Handler���ڴ������յ���Socket,���ڲ�����Processor���д�����
Container����ν��д������Լ�������֮������ν�������Ľ�����ظ�Connector��?
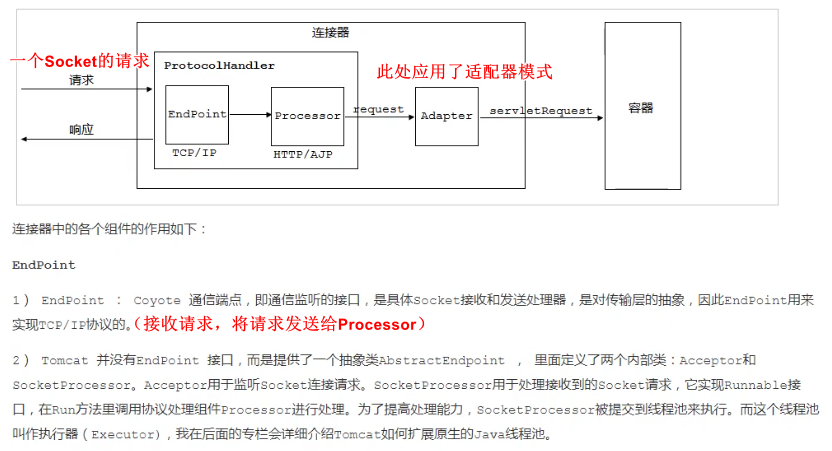
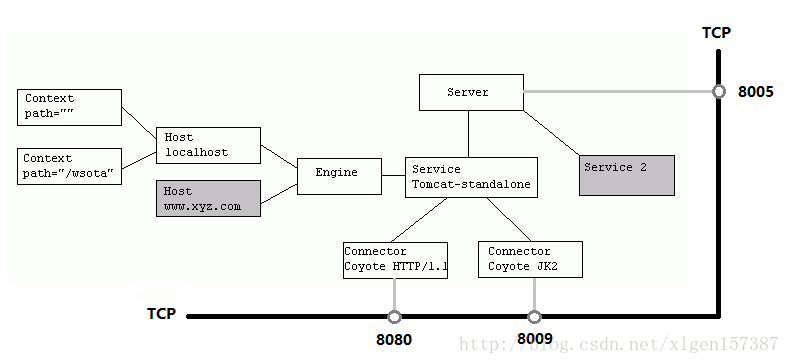
�������еĸ����������������:
1) EndPoint��TCP
- EndPoint : Coyote ͨ�Ŷ˵�,��ͨ�ż����Ľӿ�,�Ǿ���Socket���պͷ��ʹ�����,�ǶԴ����ij���,���EndPoint����ʵ��TCP/IPЭ��ġ�
- Tomcat ��û��EndPoint �ӿ�,�����ṩ��һ��������AbstractEndpoint , ���涨���������ڲ���:
Acceptor��SocketProcessor��
- Acceptor���ڼ���Socket��������
- SocketProcessor���ڴ������յ���Socket����,��ʵ��Runnable�ӿ�,��Run���������Э�鴦�����Processor���д�����Ϊ����ߴ�������,SocketProcessor���ύ���̳߳���ִ�С�������̳߳ؽ���ִ����(
Executor),�������ϸ����
EndPoint��ʵ������
- NioEndpoint
- Nio2Endpoint
- APrEndpoint
Tomcat�����չԭ����Java�̳߳ء�
2) Processor��HTTP
EndPoint������socket������������processor��Processor����HTTP��AJP��
Processor : Coyote Э�鴦���ӿ� ,���˵EndPoint������ʵ��TCP/IPЭ���,��ôProcessor����ʵ��HTTPЭ��,Processor��������EndPoint��Socket,��ȡ�ֽ���������Tomcat Request��Response����,��ͨ��Adapter�����ύ����������,
Processor�Ƕ�Ӧ�ò�Э��ij���
3) Adapter
����Э�鲻ͬ,�ͻ��˷�������������ϢҲ������ͬ,Tomcat�������Լ���ServletRequest��������š���Щ������Ϣ��ProtocolHandler�ӿڸ��������������Request�ࡣ�������Request�����DZ���ServletRequest,Ҳ����ζ��,������Request��Ϊ����������������Tomcat����ߵĽ������������CoyoteAdapter,����������ģʽ�ľ�������,����������CoyoteAdapter��Sevice����,�������Request����,CoyoteAdapter����Requestת��ServletRequest,�ٵ���������Service������
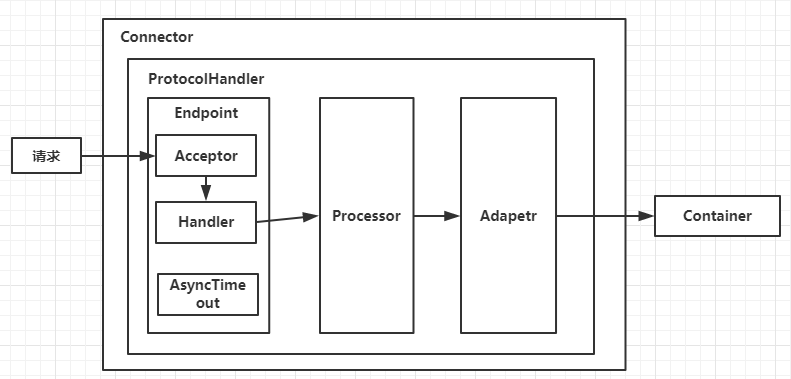
4��EndPoint���
����ProtocolHandler(������)�ֺ�����������:Endpoint��Processor��Adapter��
Endpoint:���������ײ�Socket���������ӡ�
- Endpoint�ij�����AbstractEndpoint���涨���
Acceptor��AsyncTimeout�����ڲ����һ��Handler�ӿڡ� - Acceptor���ڼ�������,
- AsyncTimeout���ڼ���첽Request�ij�ʱ,
- Handler(ij�̶ֳ�����poller)���ڴ������յ���Socket,���ڲ�����Processor���д�����
Processor:���ڽ�Endpoint���յ���Socket��װ��Request������һ���̳߳�,����ÿ���������¼������ӡ�ȥ�̳߳���ȥִ��Adapter:�̳߳��������Ϊ��ȥ��container,���õ���request,�����������յ���http request,����������תһ��
- ��Request����Container���о���Ĵ�����
5 NIO����������
BIO��������
��BIOʵ�ֵ�Connector��,�����������Ҫʵ����JIoEndpoint����JIoEndpointά����Acceptor��Worker:
- Acceptor����socket,Ȼ���Worker�̳߳����ҳ����е��̴߳���socket,���worker�̳߳�û�п����߳�,��Acceptor��������
- Worker��Tomcat�Դ����̳߳�,���ͨ��
<Executor>�����������̳߳�,ԭ����Worker���ơ�
NIO��������
��NIOʵ�ֵ�Connector��,�����������Ҫʵ����NIoEndpoint����NIoEndpoint�г��˰���Acceptor��Worker��,��ʹ����Poller,������������ͼ��ʾ
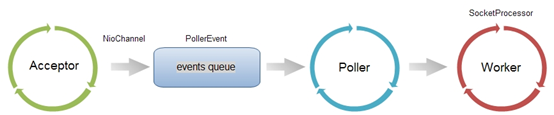
Acceptor����socket��,����ֱ��ʹ��Worker�е��̴߳�������,�����Ƚ���������Poller,��Poller��ʵ��NIO�Ĺؼ���Acceptor��Poller��������ͨ������ʵ��,ʹ���˵��͵�������-������ģʽ����Poller��,ά����һ��Selector����;��Poller�Ӷ�����ȡ��socket��,ע�ᵽ��Selector��;Ȼ��ͨ������Selector,�ҳ����пɶ���socket,��ʹ��Worker�е��̴߳�����Ӧ��������BIO����,WorkerҲ���Ա��Զ�����̳߳ش�����
BIO��NIO�Ա�
ͨ���������̿��Կ���,��NIoEndpoint��������Ĺ�����,������Acceptor����socket,�����̴߳�������,ʹ�õ���Ȼ��������ʽ;���ڡ���ȡsocket������Worker�е��̡߳������������,ʹ�÷�������NIOʵ��,����NIOģʽ��BIOģʽ������Ҫ����(�������������Ӱ���С,��ʱ��ȥ����)�����������,�ڲ������ϴ�������¿��Դ���TomcatЧ�ʵ���������:
����BIO�̳߳ص�˼�������̻߳�ȡ��һ�����Ӻ�,�����̳߳�ȥ����,Ҳ�������̲߳���accept()����,��ÿ���̶߳�Ӧһ������,accept()��ȡ��һ�����Ӻ�,ȥ�̳߳���ȥ����read����,������,������read�Ȳ������ͷ�����,����̸߳���������á�����̳߳�����,��ô�����Ŷӡ��ܾ����ԵȲ���,��ô���������ǵ����߳���
������NIO,accept()��Ȼ��������,���ǽ��յ����Ӻ�ע�ᵽ��selector,selector�����¼�����,���ӿ��Զ�ע�ᵽ����,�����¼���ȥ�̳߳��ﴦ������Ϊ����ע��ܶ��¼�,�������������Դ����߳���
Ŀǰ�����HTTP����ʹ�õ��dz�����(HTTP/1.1Ĭ��keep-aliveΪtrue),����������ζ��,һ��TCP��socket�ڵ�ǰ���������,���û���µ�������,socket���������ͷ�,���ǵ�timeout�����ͷš����ʹ��BIO,����ȡsocket������Worker�е��̡߳����������������,Ҳ����ζ����socket�ȴ���һ�������ȴ��ͷŵĹ�����,�������socket�Ĺ����̻߳�һֱ��ռ��,���ͷ�;���Tomcat����ͬʱ������socket��Ŀ���ܳ�������߳���,�����ܵ��˼������ơ���ʹ��NIO,����ȡsocket������Worker�е��̡߳���������Ƿ�������,��socket�ڵȴ���һ�������ȴ��ͷ�ʱ,������ռ�ù����߳�,���Tomcat����ͬʱ������socket��ĿԶ��������߳���,�������ܴ����ߡ�
��������Ҫ��NIO��֪ʶ��Ӧ��������Դ����
������ƪ����˵��bind(addr,backlog)������,backlog�������ĸ���,��Դ���н�Accept[backlog]
Acceptor����socket
Acceptor������AbstractEndpoint����,��ʵ����Runnable,�Ǹ��߳�
Դ����Accept[backlog]ʲô��˼:����˵���������߳�ִ��accept(),serverSock.accept();�����������NioEndpoint������Acceptor.run()�п��������̳���AbstractEndpoint�е�Acceptor,ʵ����run()��
ѧ��NIO�Ķ�֪��������˼��,���ǽ��տͻ��˵�socket,Ȼ��ȥ�����ݡ�
��֮ǰNIO�е㲻ͬ����,����֮ǰ��serversocketע�ᵽ��selector,accept()����Ҳ��selectorͨ���¼�֪��,��tomcat���ҿ������߳�accept(),���յ����ע�ᵽselector,selectorֻ���Ͷ�д�¼���
����������֮ǰ������,�ﵽ�����������,��ȥ�ȴ�����(����ȴ������е��̳߳صȴ����е���˼,����Ϊ��selector�Ĺ�ϵ,�ָо���ȫ��)���ȴ���������֮����accept()�����Ӻ�,��ûע�ᵽselector����,��������,����ע����,ֱ���ȴ����пճ���������˵tomcat�������������maxConnections+maxAcceptors
Poller����socket
poller��Ӧ��NIO�е�selector,��Ϊ��Poller�Ĺ���������һ��this.selector = Selector.open()
����poller����һ���߳�,ʵ����Runnable�ӿ�,Ҳ����˵��ÿ���߳�ȥִ��select()����,��������д�¼�
��acceptor��ȡ����socket��ע�ᵽselector��,����ע�ᵽ��poller��,poller����select()�õ������¼���key
����,Դ����pollerҲ���������,Դ����Ĭ����new Poller[2],��Ӧ��ǰ���������IJ�ͬЭ��,��HTTP��AJP
processor�����¼�
processor���ǵ�select()�õ������¼���key��,�����ж��socket��read�¼�,���Dz�����������һ���߳���һ��ִ�а�?���ǰ�ÿ��socket.read()�ŵ��̳߳���ִ�С�
��ʱ����Ҫ��װsocket.read()�������,��ÿ�������װΪ��processor�̡߳�
processor�̰߳�װ��ʱ��,�ǿ��Դӻ������ñ����ù���processor����ġ�
��processorȥ�̳߳���ִ��processor.doRun(),�����ִ��processor.process()
�̳߳�Executor
��service��ǩ��,������һ���̳߳ز���,���Ƕ��Poller������,Ҳ���Ƕ��������������,Ȼ�����ǿ����Լ�дexecutor��ǩ��,��connector��ǩ������,����ÿ���������������Լ����̳߳ء�
��������Catalina
Tomcat��һ����һϵ�п����õ�������ɵ�Web����,��Catalina��Tomcat��servlet������
Catalina ��Servlet ����ʵ��,������֮ǰ���������е��������,�Լ������½��漰���İ�ȫ���Ự����Ⱥ��������Servlet �����ܹ��ĸ������档��ͨ������ϵķ�ʽ����Coyote,����ɰ�������Э��������ݶ�д��ͬʱ,�����������ǵ�������ڡ�Shell����ȡ�
Tomcat ��ģ��ֲ�ṹͼ, ����:����Դ���еİ�һһ��Ӧ
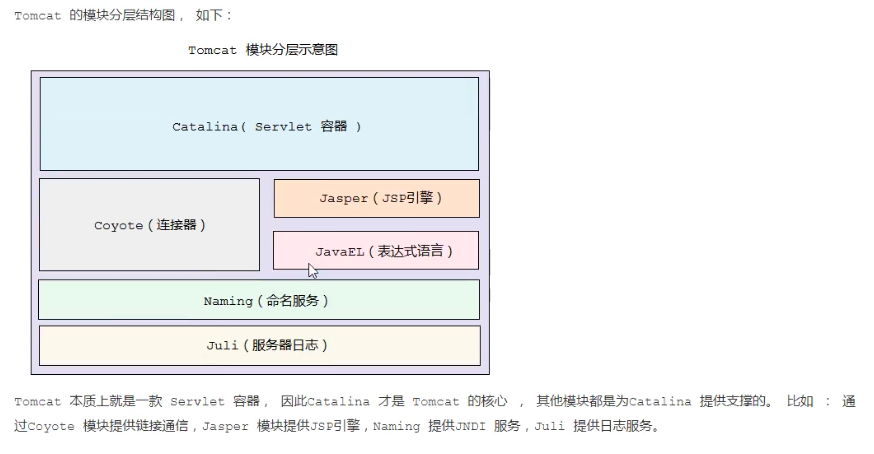
Tomcat �����Ͼ���һ�� Servlet ����, ���Catalina ���� Tomcat �ĺ��� , ����ģ�鶼��ΪCatalina �ṩ֧�ŵġ� ���� : ͨ��Coyote ģ���ṩ����ͨ��,Jasper ģ���ṩJSP����,Naming �ṩJNDI ����,Juli �ṩ��־����
Catalina �ṹ
Catalina ����Ҫ����ṹ����:
- Server:Catalina�������Server,��Server��ʾ��������������
- Service:Server�����ж������Service,ÿ���������Ŷ�����������Connector(Coyote ʵ��)��һ���������Container����Tomcat ������ʱ��, ���ʼ��һ��Catalina��ʵ����
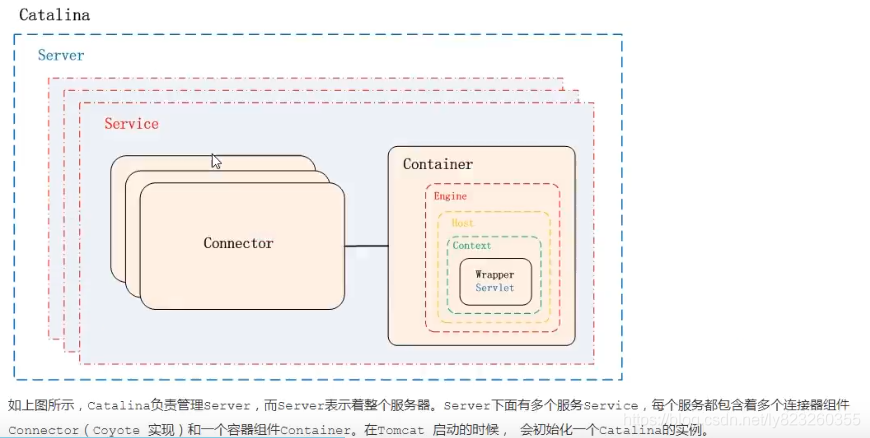
Catalina ���������ְ��:
| ��� | ְ�� |
|---|
| Catalina | �������Tomcat�������ļ� , �Դ�������������Server���,������������������й��� |
| Server | ��������ʾ����Catalina Servlet�����Լ��������,������װ������ Servlet����,Tomcat��������Serverͨ��ʵ��Lifecycle�ӿ�,�ṩ��һ�����ŵ������ر�����ϵͳ�ķ�ʽ |
| Service | ������Server�ڲ������,һ��Server�������Service���������ɸ� Connector�����һ��Container(Engine)�� |
| Connector | ������,������ͻ��˵�ͨ��,��������տͻ�����,Ȼ��ת����ص���������,�����ͻ�������Ӧ��� |
| Container | ����,�������û���servlet����,�����ض����web�û���ģ�� |
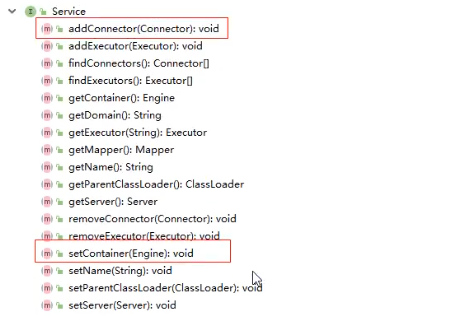
����Service��Դ��,���Ի�ȡ���е�����
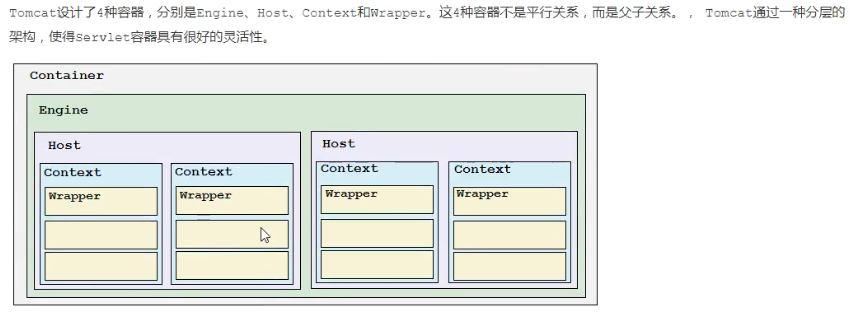
Container �ṹ
Tomcat�����4������,�ֱ���Engine��Host��Context��Wrapper����4����������ƽ�й�ϵ,���Ǹ��ӹ�ϵ��, Tomcatͨ��һ�ֲַ�ļܹ�,ʹ��Servlet�������кܺõ�����ԡ�
| ���� | ���� |
|---|
| Engine | ��ʾ����Catalina��Servlet����,���������������վ��,һ��Service���ֻ����һ��Engine,����һ������ɰ������Host |
| Host | ����һ����������,����˵һ��վ��,���Ը�Tomcat���ö������������ַ,��һ�����������¿ɰ������Context |
| Context | ��ʾһ��WebӦ�ó���, һ��WebӦ�ÿɰ������Wrapper |
| Wrapper | ��ʾһ��Servlet,Wrapper ��Ϊ�����е���ײ�,���ܰ��������� |
���Կ���Tomcat��server.xml��Tomcat����������������,���Ĺ���������ǿ����õ�,������������Server,�����������һ���ĸ�ʽҪ��������������������С�
<Server>
<Service>
<Connector/>
<Connector/>
<Engine>
<Host>
<Context></Context>
</Host>
</Engine>
</Service>
</Server>
��Щ�������и��ӹ�ϵ,�γ�һ�����νṹ(���ģʽ�е����ģʽ)��û��,Tomcat���������ģʽ��������Щ�����ġ�����ʵ�ַ�����,�������������ʵ����Container�ӿ�,������ģʽ����ʹ���û����������������������������ʹ�þ���һ���ԡ����ﵥ��������ָ������ײ��Wrapper,�����������ָ���������Context��Host����Engine��(������ʱʹ�õ���������ģʽ)
Container �ӿ����ṩ�����·���(��ͼ��֪ʶһ���ַ���) :
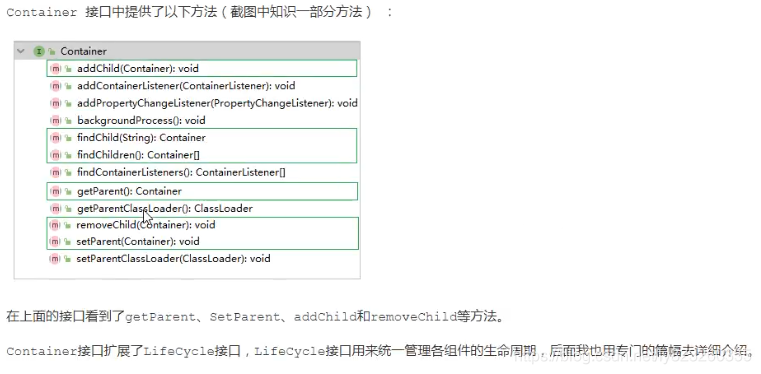
������Ľӿڿ�����getParent��SetParent��addChild��removeChild�ȷ�����
Container�ӿ���չ��LifeCycle�ӿ�,LifeCycle�ӿ�����ͳһ�������������������
�����̳߳�Executor
ExecutorԪ�ش���Tomcat�е��̳߳�,�����������������ʹ��;Ҫʹ�ø��̳߳�,�����Ҫͨ��executor����ָ�����̳߳ء�
Executor��ServiceԪ�ص���ǶԪ�ء�һ����˵,ʹ���̳߳ص���Connector���;Ϊ��ʹConnector��ʹ���̳߳�,ExecutorԪ��Ӧ�÷���Connectorǰ�档Executor��Connector�����þ�������:
<Executor name="tomcatThreadPool" namePrefix ="catalina-exec-" maxThreads="150" minSpareThreads="4" />
<Connector executor="tomcatThreadPool" port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" acceptCount="1000" />
Executor����Ҫ������:
- name:���̳߳صı��
- maxThreads:�̳߳�������Ծ�߳���,Ĭ��ֵ200(Tomcat7��8����)
- minSpareThreads:�̳߳��б��ֵ���С�߳���,��Сֵ��25
- maxIdleTime:�߳̿��е����ʱ��,�����г�����ֵʱ�ر��߳�(�����߳���С��minSpareThreads),��λ��ms,Ĭ��ֵ60000(1����)
- daemon:�Ƿ��̨�߳�,Ĭ��ֵtrue
- threadPriority:�߳����ȼ�,Ĭ��ֵ5
- namePrefix:�߳����ֵ�ǰ,�̳߳����߳�����Ϊ:namePrefix+�̱߳��
�ġ��鿴��ǰ״̬
���������Tomcat���������߳����ĸ����Լ��������,����˵����β鿴�������е����������߳�����
�鿴��������״̬,���·�Ϊ���ַ���:(1)ʹ���ֳɵĹ���,(2)ֱ��ʹ��Linux������鿴��
�ֳɵĹ���,��JDK�Դ���jconsole���߿��Է���IJ鿴�߳���Ϣ(������Բ鿴CPU���ڴ桢�ࡢJVM������Ϣ��),Tomcat�Դ���manager,�շѹ���New Relic�ȡ���ͼ��jconsole�鿴�߳���Ϣ�Ľ���:
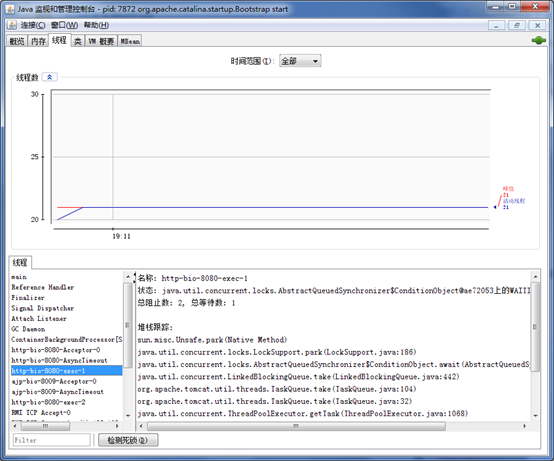
����˵һ�����ͨ��Linux������,�鿴�������е����������߳�����
�ġ�TomcatԴ��
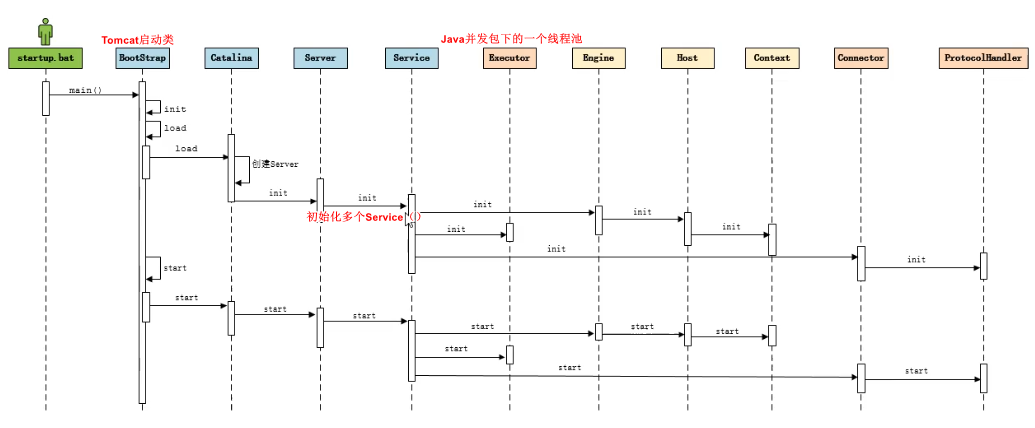
���� :
����tomcat , ��Ҫ���� bin/startup.bat (��linux Ŀ¼�� , ��Ҫ���� bin/startup.sh), ��startup.bat �ű���, ������catalina.bat��
��catalina.bat �ű��ļ���,������BootStrap�е�main()������
3)��BootStrap ��main �����е����� init���� , ������Catalina �� ��ʼ�����������
4)��BootStrap ��main �����е����� load���� , �������ֵ�����Catalina��load������
5)��Catalina ��load ������ , ��Ҫ����һЩ��ʼ���Ĺ���, ����Ҫ����Digester ����, ���ڽ��� XML��
6) Ȼ���ڵ��ú�������ij�ʼ������ ������
����Tomcat�������ļ�,��ʼ��������� ,������Ӧ�Ķ˿ں�, �����ܿͻ�������
Lifecycle�ӿ�
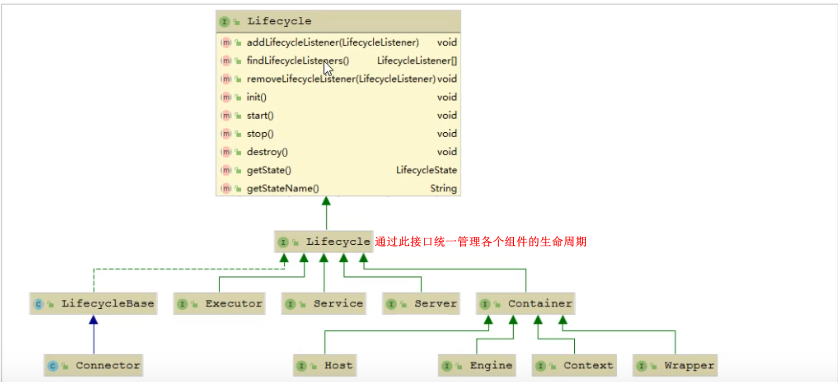
�������е���������ڳ�ʼ����������ֹͣ���������ڷ���,ӵ���������ڹ���������, ����Tomcat����Ƶ�ʱ��, �����������ڹ����������һ���ӿ� Lifecycle ,����� Server��Service��Container��Executor��Connector ��� , ��ʵ����һ���������ڵĽӿ�,�Ӷ��������������������еĺ��ķ���:
-
- init():��ʼ�����
- 2) start():�������
- 3) stop():ֹͣ���
- 4) destroy():�������
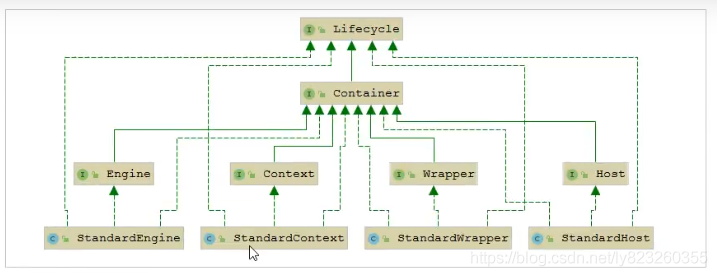
�������Ĭ��ʵ��
���������ᵽ��Server��Service��Engine��Host��Context���ǽӿ�, ��ͼ����������Щ�ӿڵ�Ĭ��ʵ���ࡣ
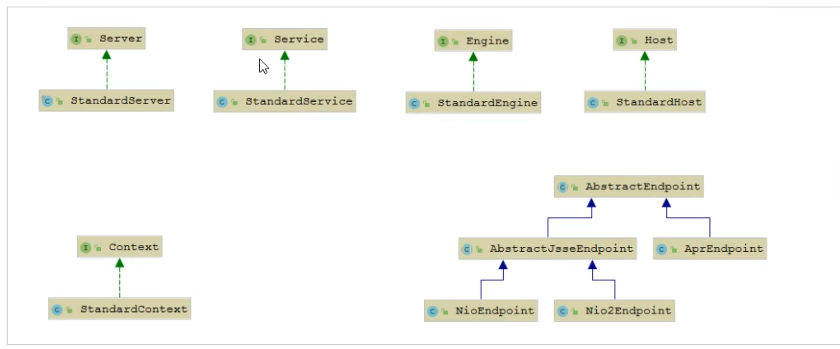
��ǰ���� Endpoint�����˵,��Tomcat��û�ж�Ӧ��Endpoint�ӿ�, ������һ�������� AbstractEndpoint,����������ʵ����:
NioEndpoint:��������NIOģ��(Tomcat8.5Ĭ��)Nio2Endpoint:��������NIO2ģ��AprEndpoint:��������APRģ��
ProtocolHandler : CoyoteЭ��ӿ�,ͨ����װEndpoint��Processor ,ʵ����Ծ���Э��Ĵ������ܡ�
Tomcat����Э���IO�ṩ��6��ʵ���ࡣ
AJP��:
- AjpNioProtocol:����NIO��IOģ�͡�
- AjpNio2Protocol:����NIO2��IOģ�͡�
- AjpAprProtocol:����APR��IOģ��,��Ҫ������APR�⡣
HTTP��:
- Http11NioProtocol:����NIO��IOģ��,(Ĭ��)(���������û�а�װAPR)��
- Http11Nio2Protocol:����NIO2��IOģ�͡�
- Http11AprProtocol :����APR��IOģ��,��Ҫ������APR�⡣
��init�Ĺ�����,init��LigecycleBaseʵ�ֵ�,��initInternal�Ǿ�������ʵ�ֵġ�ģ�巽�����ģʽ
Դ������
���Ŀ���:org.apache.catalina.startup.BootStrap.java �\�\�\�\>main()
����������ͼ���Լ�Դ����,���ǿ��Կ���Tomcat���������̷dz�����, ͳһ�����������ڹ����ӿ�Lifecycle�Ķ���������������ȵ���init() ���������������ʼ������,Ȼ���ٵ���start()��������������
ÿһ�������������������Ĵ�����,��Ҫ��������������Ӧ���������ڹ�������,��������֮��������ϵ�,��Ϊ���ǿ��Ժ�����ͨ�������ļ������ĺ��滻��
1 Bootstrap���������
- ����catalina����
- ����xml
- ��ʼ��server
- �ڳ�ʼ��server�����ʼ�����service
- �������ơ�����
- ��service���ʼ��engine��host��context��
- ��ȥ��ʼ��executor
- ��ȥ��ʼ��connector��protocolhandler��endpoint
- endpoint����
serverSocket.socket().bind()��
- ����start
2 init
connector.init
- new CoyotaAdapter������,�����õ�protocolhandler
- protocolhandler.init
- endpoint.init
- endpoint.bind�������ܿ���NIO����
3 start
��endpoint������startAcceptorThread()�����ӿ��߳�;
protected final void startAcceptorThreads() {
int