PRML 1.5 ОіВпТл
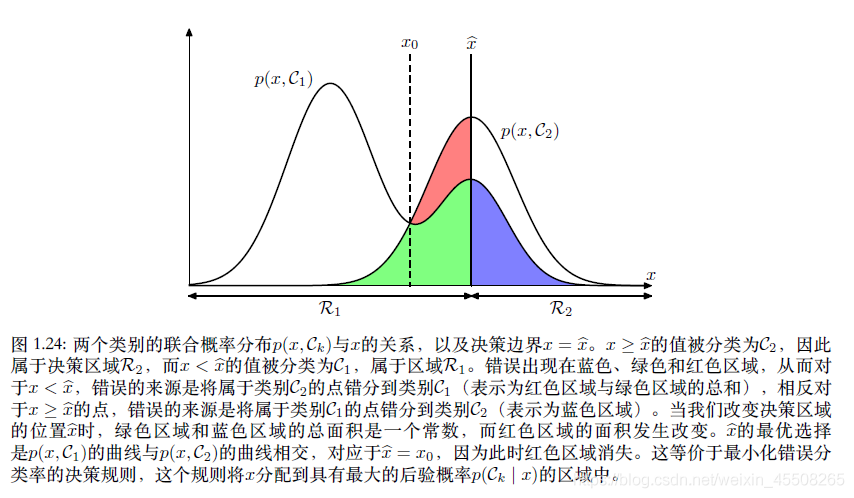
1.5.1 зюаЁЛЏДэЮѓЗжРрТЪ(Minimizing the misclassification rate)
ЖдМрЖНбЇЯАжаЕФЗжРрЮЪЬтРДНВ,ЮвУЧашвЊвЛИіЁАЙцдђЁБ,АбУПвЛИі
x
x
xЗжЕНКЯЪЪЕФРрБ№жаШЅЁЃетИіЁАЙцдђЁБЛсАбЪфШыПеМфЗжГЩВЛЭЌЕФЧјгђ,етжжЧјгђНазіОіВпЧјгђ(decision region),ЖјОіВпЧјгђЕФБпНчНазіОіВпБпНчЛђепНаОіВпУцЁЃШчЩЯЭМЫљЪО,ШчЙћЮвУЧНЋЪєгк
C
1
C_1
C1?РрЕФжЕЗжЕНСЫ
C
2
C_2
C2?Рржа,ФЧУДЮвУЧОЭЗИСЫвЛИіДэЮѓЁЃетжжЗЂЩњЕФИХТЪШчЯТ:
p
(
m
i
s
t
a
k
e
)
=
p
(
x
ЁЪ
R
1
,
C
2
)
+
p
(
x
ЁЪ
R
2
,
C
1
)
=
Ёв
R
1
p
(
x
,
C
2
)
d
x
+
Ёв
R
2
p
(
x
,
C
1
)
d
x
p(mistake) = p(x\in R_1, C_2)+p(x\in R_2, C_1)=\int_{R_1}p(x,C_2)\mathrm{d} x+\int_{R_2}p(x,C_1)\mathrm{d} x
p(mistake)=p(xЁЪR1?,C2?)+p(xЁЪR2?,C1?)=ЁвR1??p(x,C2?)dx+ЁвR2??p(x,C1?)dx
ЮвУЧЕБШЛЯЃЭћНЋДэЮѓНЕЕНзюаЁ,МДзюаЁЛЏ
p
(
m
i
s
t
a
k
e
)
p(mistake)
p(mistake)ЁЃИљОнГЫЛ§Йцдђ,
p
(
x
,
C
k
)
=
p
(
C
k
ЈO
x
)
p
(
x
)
p(x, C_k)=p(C_k|x)p(x)
p(x,Ck?)=p(Ck?ЈOx)p(x)
ЖдзюаЁЛЏ
p
(
x
,
C
k
)
p(x, C_k)
p(x,Ck?),ФЧУДашвЊзюаЁЛЏ
p
(
C
k
ЈO
x
)
p(C_k|x)
p(Ck?ЈOx)ЁЃ
ЖдгкИќ?АуЕФKРрЕФЧщаЮ,зюДѓЛЏе§ШЗТЪЛсЩдЮЂМђЕЅ?аЉ,МДзюДѓЛЏЯТЪН
p
(
correct
)
=
ЁЦ
k
=
1
K
p
(
x
ЁЪ
R
k
,
C
k
)
=
ЁЦ
k
=
1
K
Ёв
R
k
p
(
x
,
C
k
)
dx
p ( \text{correct} ) =\sum_{k=1}^Kp ( \text{x}\in\mathcal{R}_k,\mathcal{C}_k ) =\sum_{k=1}^K\int_{\mathcal{R}_k} p ( \text{x},\mathcal{C}_k ) \text{dx}
p(correct)=k=1ЁЦK?p(xЁЪRk?,Ck?)=k=1ЁЦK?ЁвRk??p(x,Ck?)dx
1.5.2 зюаЁЛЏЦкЭћЫ№ЪЇ(Minimizing the expected loss)
ЪщжаОйСЫвЛИіЖдАЉжЂВЁШЫЗжРрЕФР§зг,ЮветРяМђЕЅВћЪівЛЯТЁЃЗжРрЮЪЬтЮвУЧЖМЛсГіЯжСНжжДэЮѓЁЃвЛ,ИјУЛгаЛМАЉжЂЕФВЁШЫДэЮѓЕиеяЖЯЮЊАЉжЂ,ЖўЁЂИјЛМСЫАЉжЂЕФВЁШЫеяЖЯЮЊНЁПЕЁЃЮвУЧИјГіШчЯТЛьЯ§Оиеѓ:
