1、准备工作
首先需要一个相亲网站的账号,我这里选取的是“我主良缘”。注册登陆就可以了:
1 高清壁纸:https://www.36992.com/girls/list-1.html
2 Python环境
Python3.9新特性:
字典“并集”运算符
类型提示的改善
装饰器语法更加灵活
classmethod 支持包装其他描述器
新增模块、函数、方法
Python官网下载:https://www.python.org/
3 PyCharm编译器
优点:
1 )每个文件都有其输出窗口
2 )可以终止进程(只要点下按钮就行)
3 )各种提示超强:
①没用的变量颜色会变灰
②用错了的变量下面会有红色波浪线
③书写提示
4 )索引功能超强,
PyCharm官网下载:https://www.jetbrains.com/pycharm/download/#section=windows
4 requests,lxml库安装
Requests:
打开cmd命令管理器,输入pip install requests,显示如下图则安装成功。
lxml:
打开cmd命令管理器,输入pip install lxml,显示如下图则安装成功。

2 、代码和效果展示
1 >代码
import requests
from lxml import etree
import time
def down_image( page ):
print(f'页面{page},开始')
t1 = time.time()
url = f'https://www.36992.com/girls/list-{page}.html'
resp = requests.get(url)
resp.encoding = 'gbk'
with open('index.html', 'wb') as f:
f.write(resp.content)
tree = etree.HTML(resp.content)
node_list = tree.xpath('//dd')
sub_url_list = []
for node in node_list:
if len(node.xpath('./a/img/@src')) > 0:
img_url =str(node.xpath('./a/img/@src')[0]).replace("pic_360","pic")
if len(node.xpath('./a/img/@title')) > 0:
title = node.xpath('./a/img/@title')[0]
sub_url_list.append((img_url, title))
for sub_url, title in sub_url_list:
suffix = sub_url.split('.')[-1]
img_content = requests.get(sub_url).content
with open(f'D:/123/456/{title}.{suffix}', 'wb') as f:
f.write(img_content)
f.close()
print(f'页面{page},完成')
if __name__ == '__main__':
for page in range(1,60):
down_image(page)
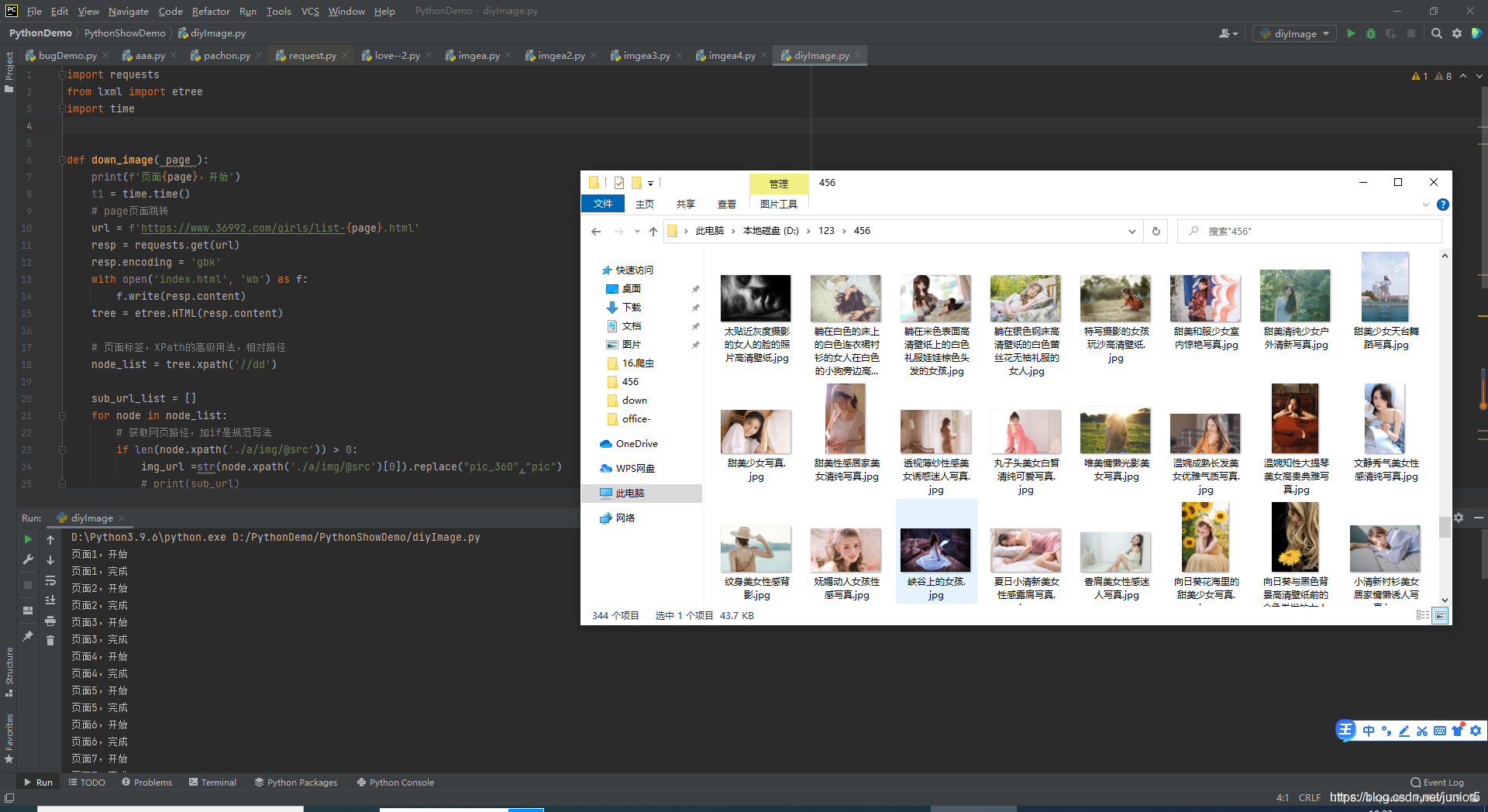
2 >效果
3 、知识点
1 >路径解析
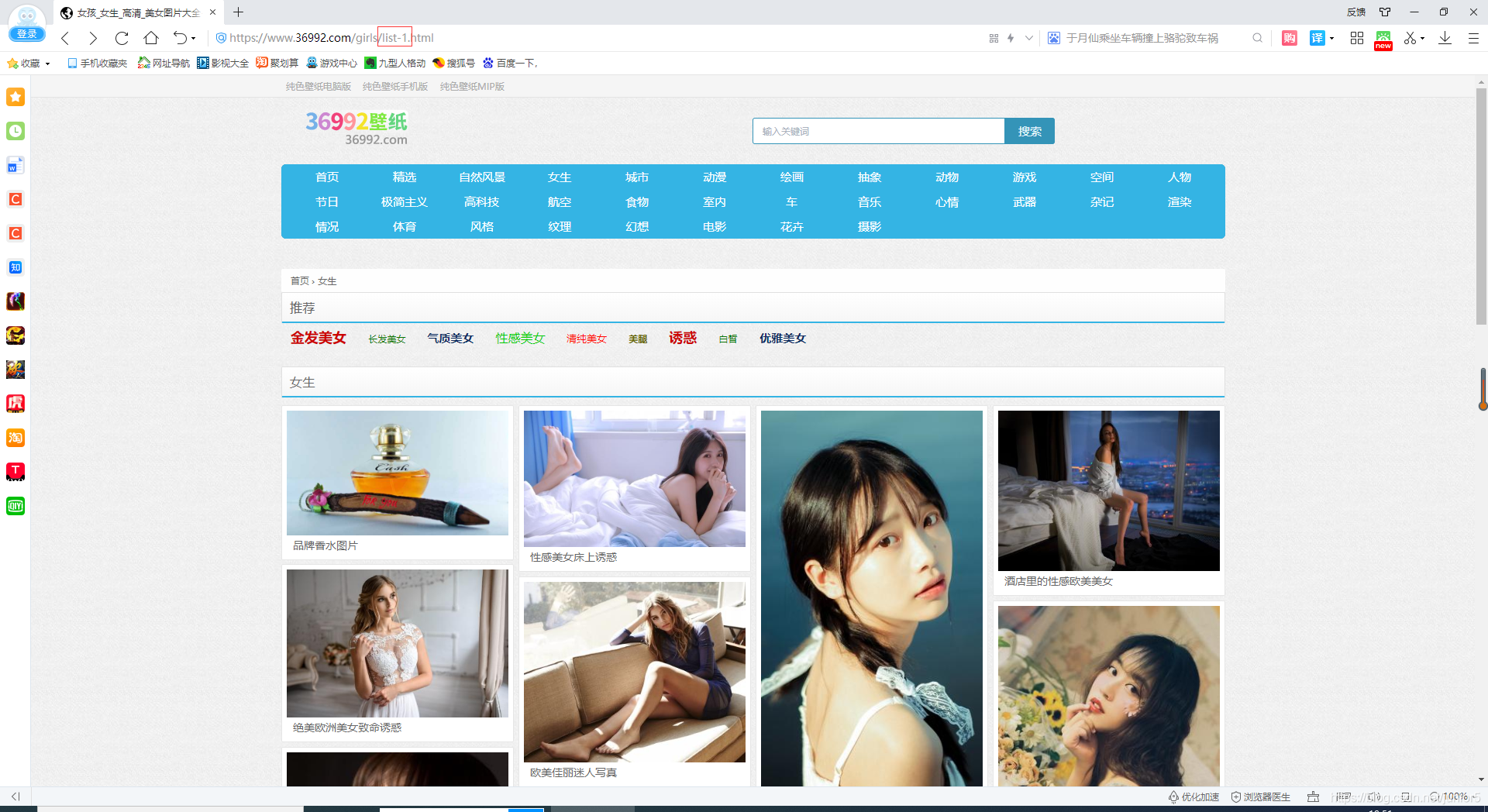
第一页:https://www.36992.com/girls/list-1.html
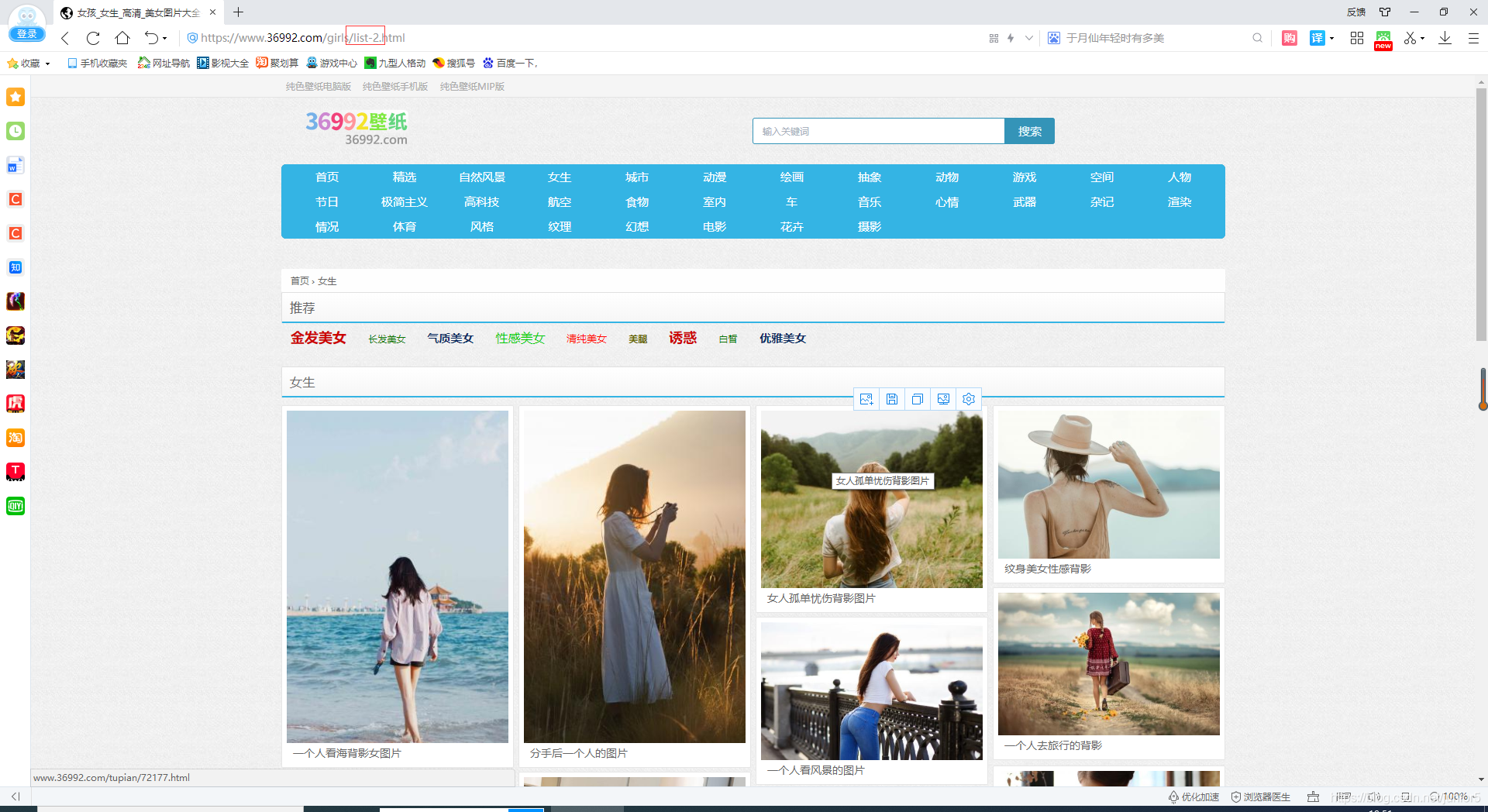
第二页:https://www.36992.com/girls/list-2.html
规律:url = f’https://www.36992.com/girls/list-{page}.html’
扩展知识点:HTTP协议
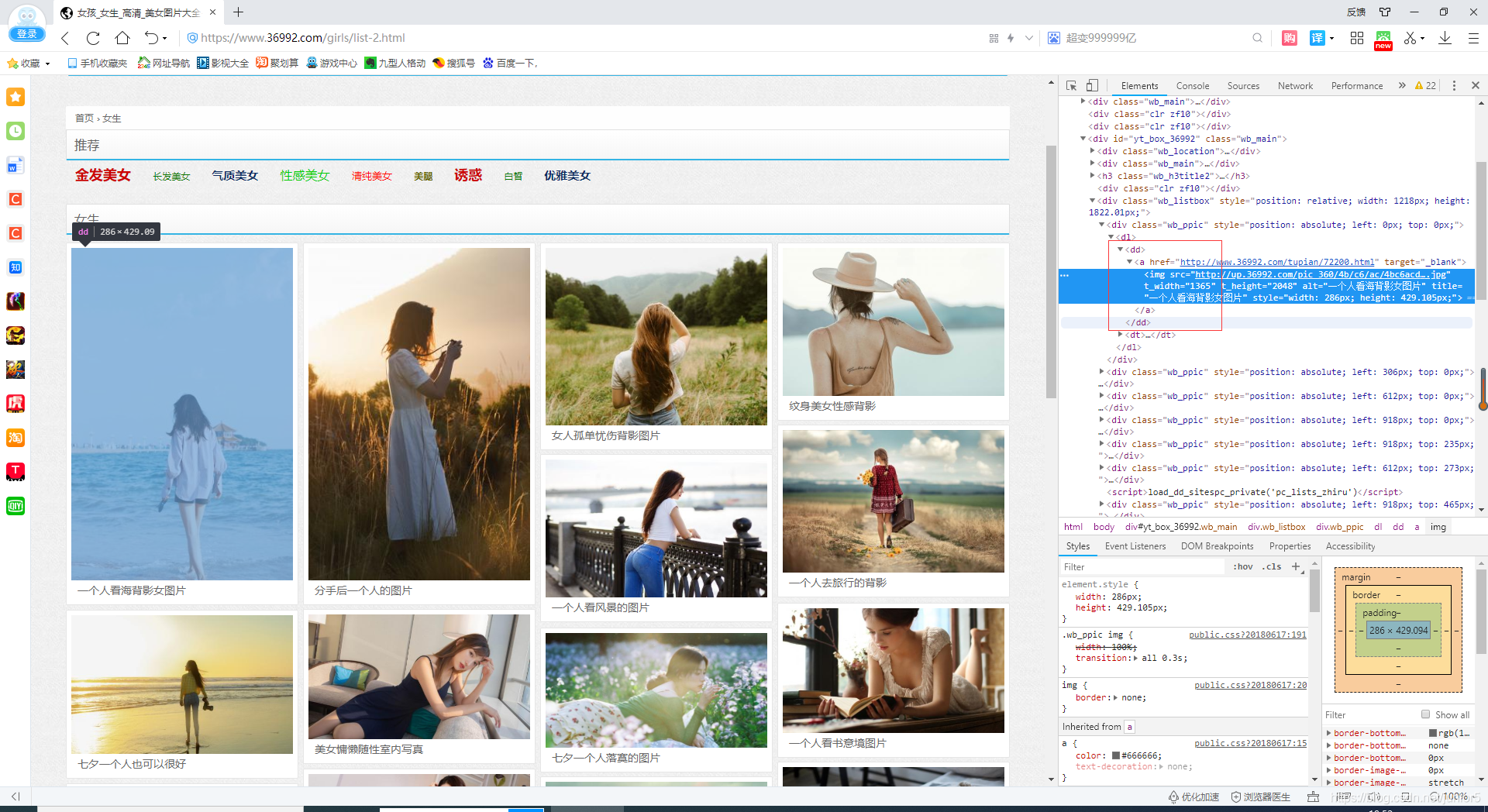
2 >审查元素
img:
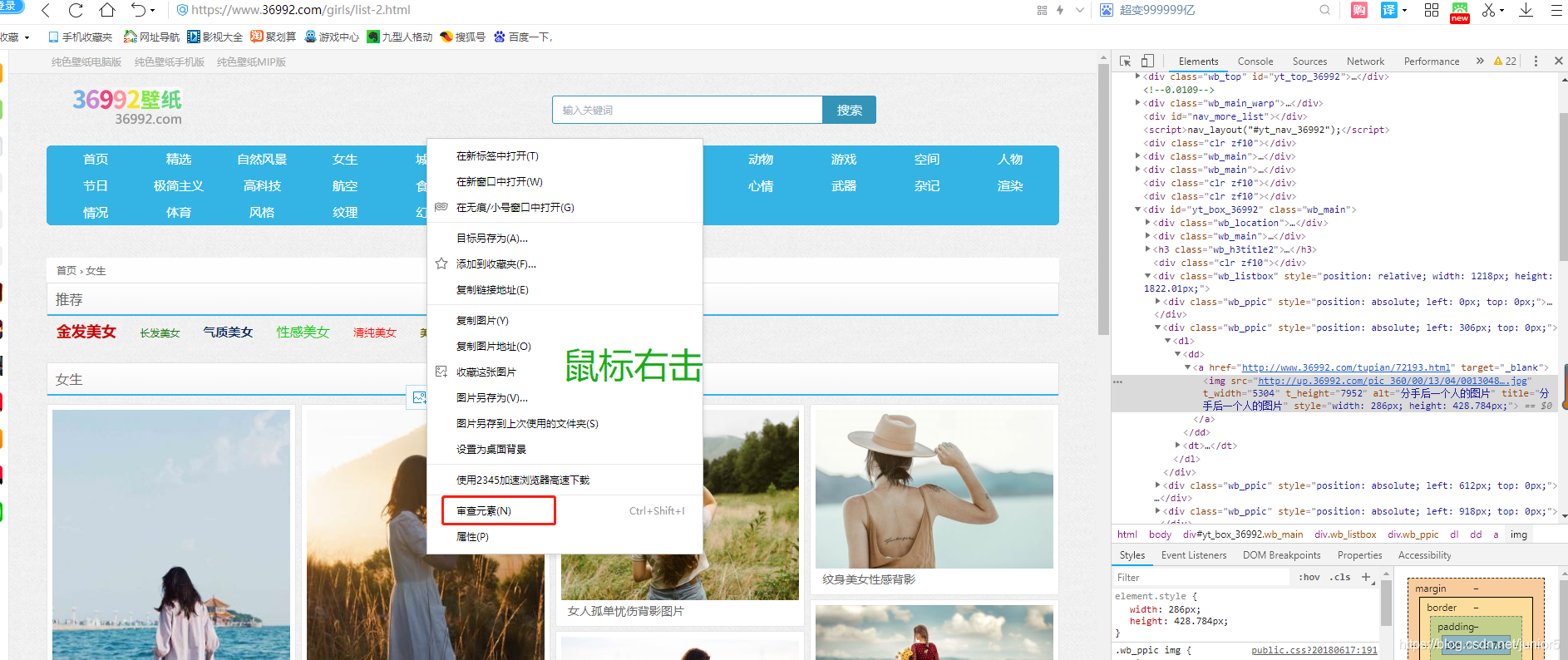
扩展知识点:HTML
3 > XPath定位
基本概念
1 )绝对路径:绝对路径是指目录下的绝对位置,直接到达目标位置,通常是从盘符开始的路径。
node.xpath(’./a/img/@src’)
优点:解析简单;
缺点:呆板,不能阻止页面变化

2 )相对路径:由这个文件所在的路径引起的跟其它文件的路径关系。
node_list = tree.xpath(’//dd’)
优点:灵活,可以根据元素属性绑定(id,class,层级),不担心,页面变化
缺点:执行时,需要解析,消耗时间。
扩展知识点:XPath关系属性
4 > 自定义函数:def down_image( page ):
1 )函数是组织好的。
2 )可重复使用的。
3 )用来实现单一,或相关联功能的代码段。
4 )函数能提高应用的模块性,和代码的重复利用率。
5 )你已经知道Python提供了许多内建函数,比如print()。
6 )你也可以自己创建函数,这被叫做用户自定义函数。
扩展知识点:类的继承
4.总结
用Python实现一个小功能很简单,只要仔细跟着教程一步步操作,依葫芦画瓢,就可以做到。
掌握基础知识,可以更快速的帮助你举一反三。
由于篇幅受限,大量跟爬虫相关的,HTTP、web、HTML、自动化的知识,可以用于反爬,反反爬,这里不一一展开了。点击关注,持续更新。
cs