ФПБъЭјжЗhttps://www.csflhjw.com/zhenghun/34.html?page=1
вЛЁЂДђПЊНчУц
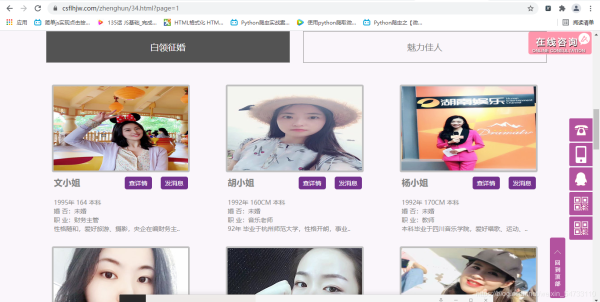
ЪѓБъгвМќДђПЊМьВщЃЌЗНПђРяЮЊФувЛИіЮФаЁНуЕФеїЛщаХЯЂЁЃЁЃгЩДЫХаЖЯГіЮЊЭЌВНМгди
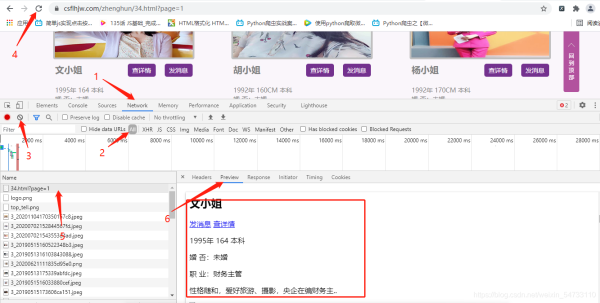
ЕуЛїelementsЃЌЖЈЮЛЭМЦЌЕижЗЃЌЗНПђРяЮЊИУХЎЪПЕФurlЕижЗМАЭМЦЌЕижЗ
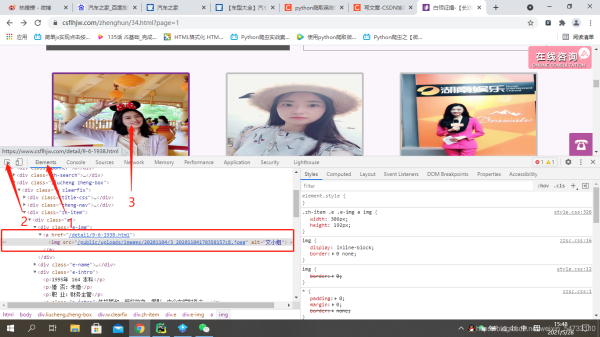
ПЩвдПДГіИУХЎЪПЕФurlЕижЗВЛШЋЃЌжЎКѓдкДњТыжавЊНјааurlЕФЦДНгЃЌПДвЛЯТЗвГЕФurlЕижЗгаЪВУДБфЛЏ
ЕуЛїЕк2вГ
https://www.csflhjw.com/zhenghun/34.html?page=2
ЕуЛїЕк3вГ
https://www.csflhjw.com/zhenghun/34.html?page=3
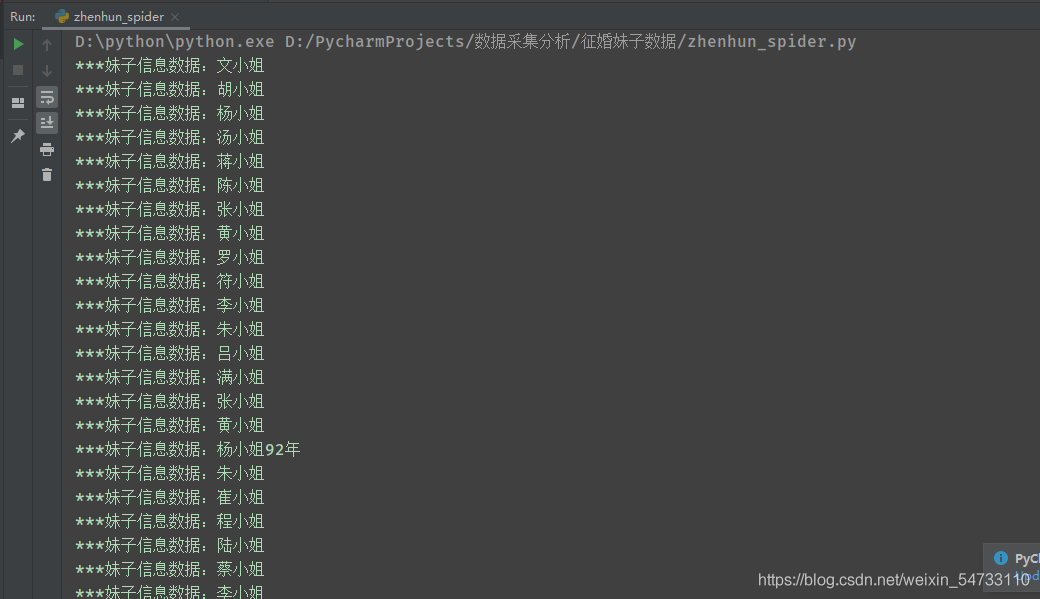
ПЩвдПДГіБфЛЏдкзюКѓ
зівЛЯТfouбЛЗИёЪНЛЏЪфГівЛЯТЁЃЁЃвЛЙВ10вГ
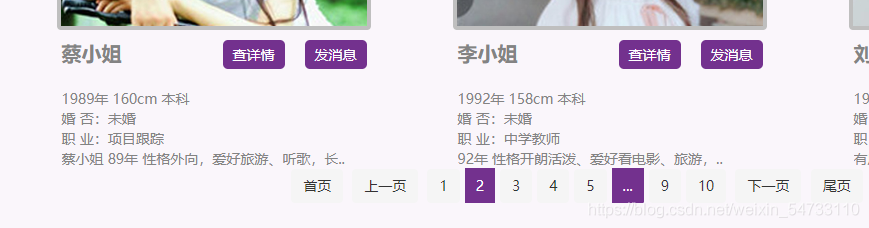
ЖўЁЂДњТыНтЮі
1.ЛёШЁЫљгаЕФХЎЪПЕФurlЃЌxpathЕФТЗОЖОЭВЛЯъЯИЫЕСЫЁЃЁЃ
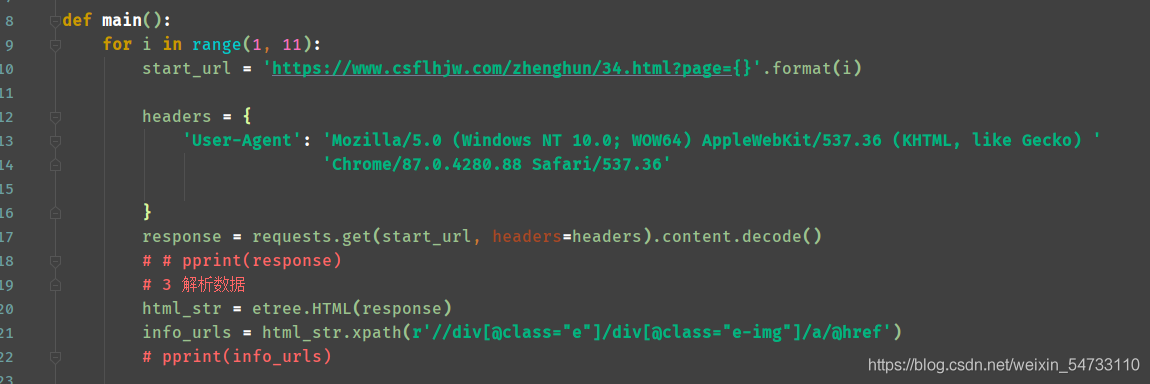
2.ЙЙдьУПвЛЮЛХЎЪПЕФurlЕижЗ

3.ШЛКѓЕуПЊвЛЮЛХЎЪПЕФurlЕижЗЃЌгУЭЌбљЕФЗНЗЈЃЌШЗЖЈвВЮЊЭЌВНМгди
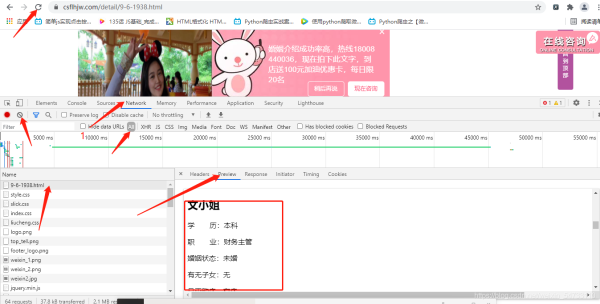
4.жЎКѓОЭЪЧХЎЪПurlЕижЗhtmlЕФxpathЬсШЁЃЌУПИіЖМДђгЁвЛЯТЃЌАбВЛвЊЕФЙ§ТЫвЛЯТ
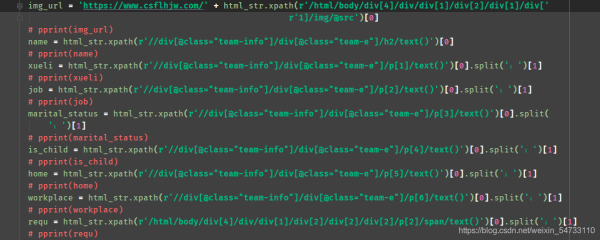
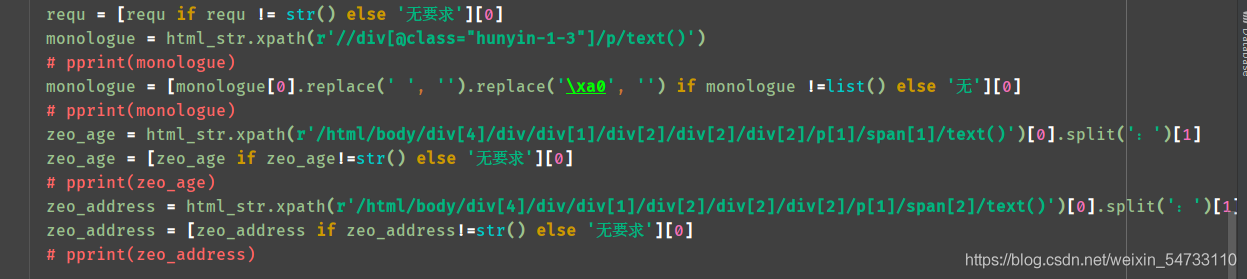
5.зюКѓОЭЪЧЮФМўЕФБЃДц
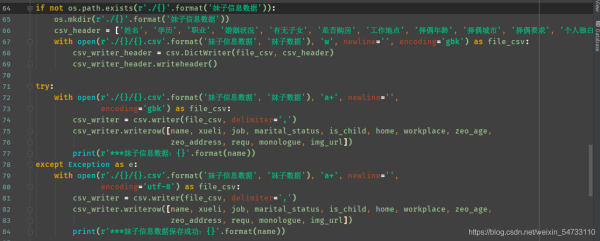
ДђгЁНсЙћЃК
Ш§ЁЂЭъећДњТы
# !/usr/bin/nev python
# -*-coding:utf8-*-
import requests, os, csv
from pprint import pprint
from lxml import etree
def main():
for i in range(1, 11):
start_url = 'https://www.csflhjw.com/zhenghun/34.html?page={}'.format(i)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(start_url, headers=headers).content.decode()
# # pprint(response)
# 3 НтЮіЪ§Он
html_str = etree.HTML(response)
info_urls = html_str.xpath(r'//div[@class="e"]/div[@class="e-img"]/a/@href')
# pprint(info_urls)
# 4ЁЂбЛЗБщРњ ЙЙдьimg_info_url
for info_url in info_urls:
info_url = r'https://www.csflhjw.com' + info_url
# print(info_url)
# 5ЁЂЖдinfo_urlЗЂЧыЧѓЃЌНтЮіЕУЕНimg_urls
response = requests.get(info_url, headers=headers).content.decode()
html_str = etree.HTML(response)
# pprint(html_str)
img_url = 'https://www.csflhjw.com/' + html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[1]/div['
r'1]/img/@src')[0]
# pprint(img_url)
name = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/h2/text()')[0]
# pprint(name)
xueli = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[1]/text()')[0].split('ЃК')[1]
# pprint(xueli)
job = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[2]/text()')[0].split('ЃК')[1]
# pprint(job)
marital_status = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[3]/text()')[0].split(
'ЃК')[1]
# pprint(marital_status)
is_child = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[4]/text()')[0].split('ЃК')[1]
# pprint(is_child)
home = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[5]/text()')[0].split('ЃК')[1]
# pprint(home)
workplace = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[6]/text()')[0].split('ЃК')[1]
# pprint(workplace)
requ = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[2]/span/text()')[0].split('ЃК')[1]
# pprint(requ)
requ = [requ if requ != str() else 'ЮовЊЧѓ'][0]
monologue = html_str.xpath(r'//div[@class="hunyin-1-3"]/p/text()')
# pprint(monologue)
monologue = [monologue[0].replace(' ', '').replace('\xa0', '') if monologue !=list() else 'Юо'][0]
# pprint(monologue)
zeo_age = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[1]/text()')[0].split('ЃК')[1]
zeo_age = [zeo_age if zeo_age!=str() else 'ЮовЊЧѓ'][0]
# pprint(zeo_age)
zeo_address = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[2]/text()')[0].split('ЃК')[1]
zeo_address = [zeo_address if zeo_address!=str() else 'ЮовЊЧѓ'][0]
# pprint(zeo_address)
if not os.path.exists(r'./{}'.format('УУзгаХЯЂЪ§Он')):
os.mkdir(r'./{}'.format('УУзгаХЯЂЪ§Он'))
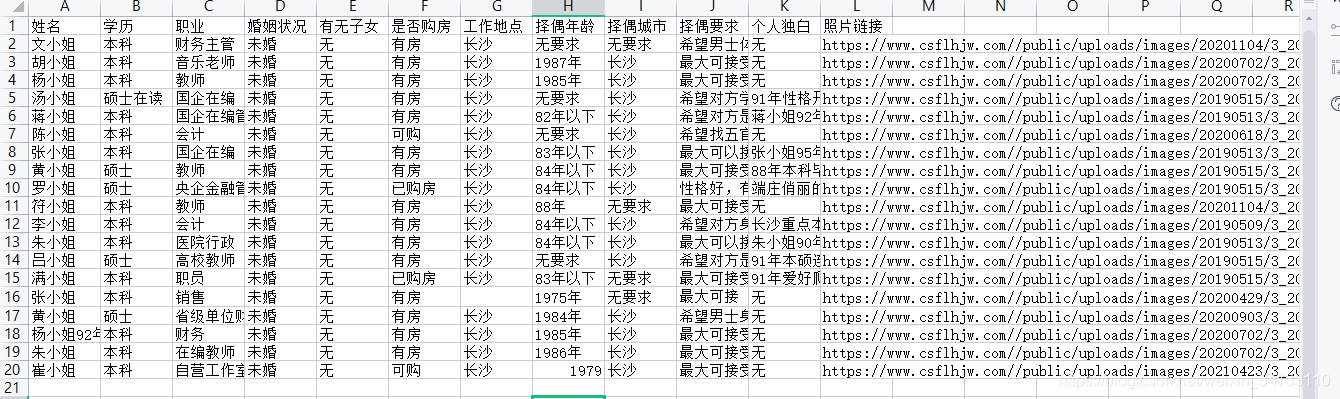
csv_header = ['аеУћ', 'бЇРњ', 'жАвЕ', 'ЛщвізДПі', 'гаЮозгХЎ', 'ЪЧЗёЙКЗП', 'ЙЄзїЕиЕу', 'дёХМФъСф', 'дёХМГЧЪа', 'дёХМвЊЧѓ', 'ИіШЫЖРАз', 'ееЦЌСДНг']
with open(r'./{}/{}.csv'.format('УУзгаХЯЂЪ§Он', 'УУзгЪ§Он'), 'w', newline='', encoding='gbk') as file_csv:
csv_writer_header = csv.DictWriter(file_csv, csv_header)
csv_writer_header.writeheader()
try:
with open(r'./{}/{}.csv'.format('УУзгаХЯЂЪ§Он', 'УУзгЪ§Он'), 'a+', newline='',
encoding='gbk') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***УУзгаХЯЂЪ§ОнЃК{}'.format(name))
except Exception as e:
with open(r'./{}/{}.csv'.format('УУзгаХЯЂЪ§Он', 'УУзгЪ§Он'), 'a+', newline='',
encoding='utf-8') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***УУзгаХЯЂЪ§ОнБЃДцГЩЙІЃК{}'.format(name))
if __name__ == '__main__':
main()
jsjbwy