CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
2、mysql索引知识
2.1 B+Tree索引
在InnoDB中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表(IOT),InnoDB使用B+树索引模型,数据都是存储在B+树中的。
假设,有一个表的主键列为ID,字段为k,并且在k上有索引。表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)、(600,6),每一个索引在InnoDB里面对应一棵B+树,两棵树的简意示意图如下:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?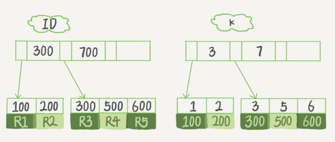 ?
?
2.2 主键索引和普通索引的区别
如果语句是select * from T where ID=500,即主键查询方式,则只需要搜索ID这棵B+树;
如果语句是select * from T where k=5,即普通索引查询方式,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次,这个过程称为回表!
也就是说,基于非主键索引的查询需要多扫描一棵索引树,因此,我们在应用中应该尽量使用主键查询。
2.3 唯一索引vs普通索引
从查询上来说
从更新上来说
A??如果目标页在内存中:
B??如果目标页在不在内存中:
从这里可以看到,查询上普通索引只是比唯一索引多了一个一次指针寻找和一次计算,由于数据是按页读取的,数据几乎都在内存中,所以性能相差不大。
? 但从更新上来看,如果数据不在内存中,唯 一索引需要将数据从磁盘上读取到内存中,这样会引发随机读,导致IO消耗增多,而普通索引可以利用change buffer,IO上边要节省很多。性能相差会很多,所以如果可以在业务端保证数据的唯一性,那就可以使用普通索引。
3、mysql索引优化
3.1 查看索引使用情况
使用方法:在select语句前加上explain
示例:EXPLAIN SELECT surname,first_name form a,b WHERE a.id=b.id
EXPLAIN列的解释:
- table:显示这一行的数据是关于哪张表的。
- type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。
- possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句。
- key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MySQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MySQL忽略索引。
- key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好。
- ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。
- rows:MySQL认为必须检查的用来返回请求数据的行数。
- Extra:关于MySQL如何解析查询的额外信息。
Extra列返回的描述的意义:
Distinct: 一旦MySQL找到了与行相联合匹配的行,就不再搜索了。
Not exists: MySQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了。
Range checked for each Record(index map:#): 没有找到理想的索引,因此对于从前面表中来的每一个行组合,MySQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一。
Using filesort: 看到这个的时候,查询就需要优化了。MySQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行。
Using index: 列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候。
Using temporary: 看到这个的时候,查询需要优化了。这里,MySQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上。
Where used: 使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index,这就会发生,或者是查询有问题不同连接类型的解释(按照效率高低的顺序排序)。
system: 表只有一行:system表。这是const连接类型的特殊情况。
const: 表中的一个记录的最大值能够匹配这个查询(索引可以是主键或惟一索引)。因为只有一行,这个值实际就是常数,因为MySQL先读这个值然后把它当做常数来对待。
eq_ref: 在连接中,MySQL在查询时,从前面的表中,对每一个记录的联合都从表中读取一个记录,它在查询使用了索引为主键或惟一键的全部时使用。
ref: 这个连接类型只有在查询使用了不是惟一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少―越少越好。
range: 这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西时发生的情况。
index: 这个连接类型对前面的表中的每一个记录联合进行完全扫描(比ALL更好,因为索引一般小于表数据)。
ALL: 这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,应该尽量避免。
3.2 mysql索引使用策略
- 最好全值匹配--索引怎么建我怎么用。
- 最佳左前缀法则--如果是多列复合索引,要遵守最左前缀法则。指的是查询要从索引的最左前列开始并且不跳过索引中的列。
- 不在索引列上做任何操作(计算,函数,(自动或者手动)类型装换),会导致索引失效而导致全表扫描。
- 存储引擎不能使用索引中范围条件右边的列。--范围之后索引失效(< ,>,between and)。
- 尽量使用覆盖索引--索引和查询列一致,减少select *。--按需取数据用多少取多少。
- 在MYSQL使用不等于(<,>,!=)的时候无法使用索引,会导致索引失效。
- is null或者is not null 也会导致无法使用索引。
- like以通配符开头('%abc...')MYSQL索引失效会变成全表扫描的操作。--覆盖索引。
- 隐式转换索引失效:字符串不加单引号。
- where条件少用or,用它来连接时索引会失效。
3.3 mysql索引使用原则
(1)复合索引:选择索引列的顺序
????? 1)尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO性能也就越好)???
????? 2)区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数)
????? 3)使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)
(2)表关联查询
????? 1)类型和大小要相同,可以使用索引。
????????? VARCHAR(10)和?CHAR(10)大小相同,但?VARCHAR(10)与?CHAR(15)不相同。
????? 2)字符串列之间比较,两列应使用相同的字符集。例如,将utf8列与?latin1列进行比较会不使用索引。
????? 3)将字符串列与时间或数字列进行比较时,在没有转换情况下,不使用索引。
(3)常见的索引列建议
????? 1)? ?WHERE 字段
????? 2)? ?ORDER BY、GROUP BY、DISTINCT 中的字段不要将符合1和2中字段的列都建立一个索引,通常将1、2中的字段建立联合索引效果更好
????? 3)? 多表join的关联列
????? 4)通过索引扫描的行记录数超过全表的10%~30%左右,优化器不会走索引,而变成全表扫描
????? 5)避免使用双%号的查询条件。
(如果无前置%,只有后置%,是可以用到列上的索引的)
? 覆盖索引、前缀索引、索引下推,在满足语句需求的情况下,尽量少地访问资源是数据库设计的重要原则之一。我们在使用数据库的时候,尤其是在设计表结构时,也要以减少资源消耗为目标。
4、索引选择异常处理办法
- 采用force index 强行选择一个索引。
- 修改sql语句、引导MySQL使用我们期望的索引。
- 在有些场景下,我们可以新建一个更适合的索引,来提供给优化器做选择,或删除掉误用的索引。
由于索引统计信息的不准确,可以用analyze table来解决。
而对于其它优化器误判断的情况,你可以在应用端用force index 来强行指定索引,也可以通过修改语句来引导优化器,还可以通过增加或者删除索引来绕过这个问题。
知识集锦专栏:https://blog.csdn.net/weixin_39032019/category_11163855.html
求点赞、求收藏、关注专栏
cs