更多文章欢迎订阅上方《从实战学python》专栏
哈喽,大家好,我是一条。
今日逛B站时发现“法外狂徒张三”在B站的热度相当之高,随随便便一个几分钟的视频就有100w+的播放量。
所以一条就来了兴趣,B站人是如何看待“法外狂徒张三”的?
我们爬取弹幕并制作词云分析一下。
获取弹幕
分析url
首先要拿到url,B站搜索张三,我们就用第一个视频:【张三的社会语录】
https://www.bilibili.com/video/av588303995
F12分析一下
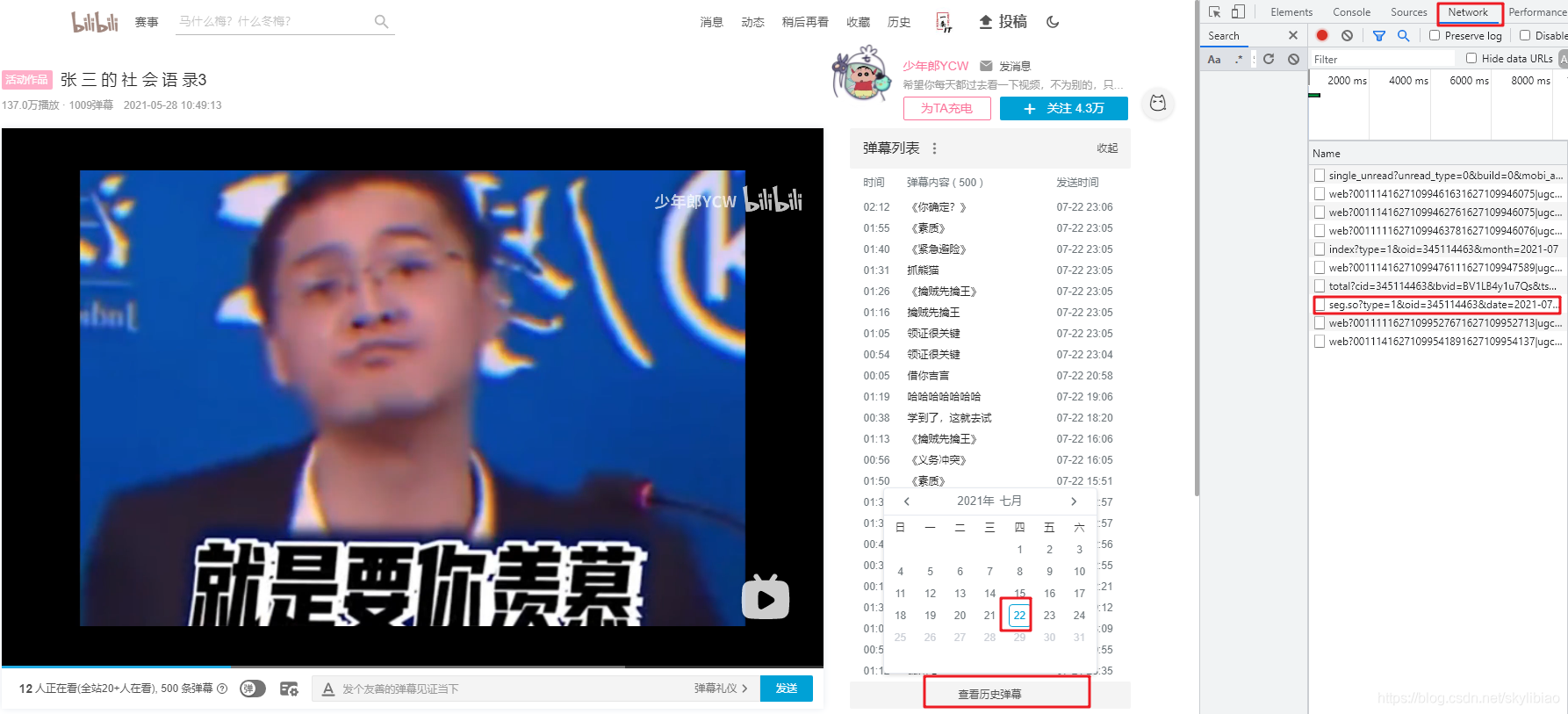
点击查看历史弹幕――选择一个日期
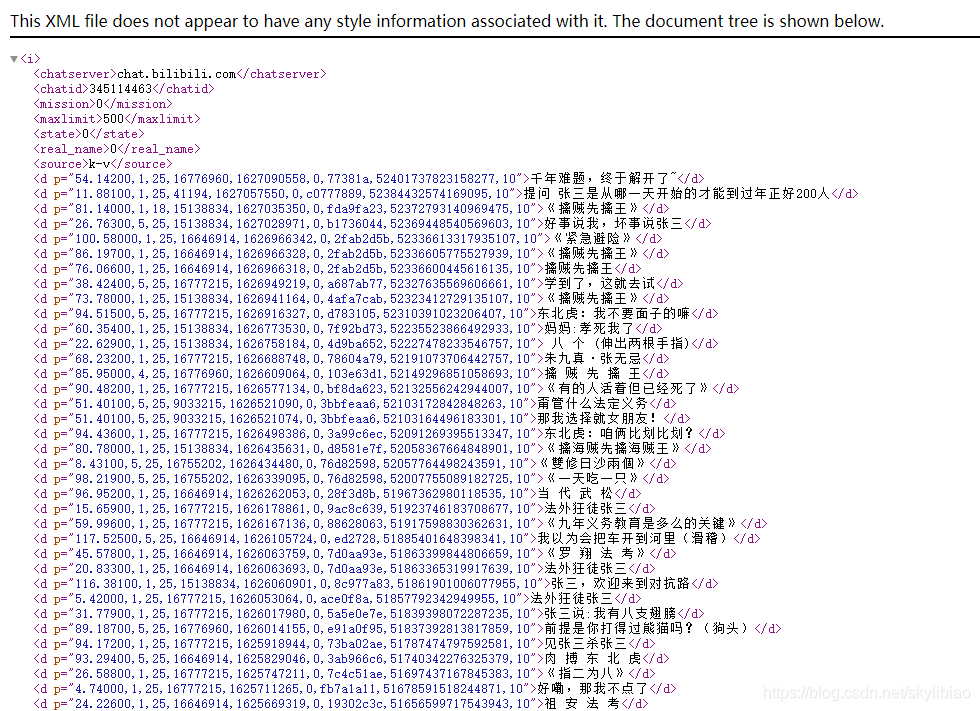
可以看到一个seg.so的链接,后面是oid=,如此我们就拿到了该视频弹幕的oid
拼接到弹幕API,得到弹幕的xml地址
https://api.bilibili.com/x/v1/dm/list.so?oid=345114463
发送请求
由于没有登录验证,我们就简单的发送一条get请求,并用xpath解析
import requests
from lxml import etree
def get_text():
url='https://api.bilibili.com/x/v1/dm/list.so?oid=345114463'
res=requests.get(url)
res.encoding='utf-8'
with open("bilibili.xml", 'wb') as f:
f.write(res.content)
html = etree.parse('bilibili.xml',etree.HTMLParser())
b_list=html.xpath('//d//text()')
with open("bilibili.txt",'a+',encoding='utf-8') as f:
for i in b_list:
f.write(i+'\n')
print("弹幕获取完成")
文本处理
安装分词库
pip install jieba
jieba分词
jieba分词的作用是将弹幕的长句分成单个的词语,以便进行词云的绘制
在分词前还要去除无效数据,比如标点符号,语气助词……

def get_wc():
with open("bilibili.txt", "r",encoding='utf-8') as f:
txt = f.read()
re_move = [",", "。",'\n','\xa0',' ','的','了','吗','我','你']
for i in re_move:
txt = txt.replace(i, " ")
word = jieba.lcut(txt)
with open("bilibili_wc.txt", 'w',encoding='utf-8') as f:
for i in word:
f.write(str(i) + ' ')
print("文本处理完成")
生成词云
安装wordcloud
pip install wordcloud
wordcloud
当我们手中有一篇文档,比如书籍、小说、电影剧本,若想快速了解其主要内容是什么,则可以采用绘制 WordCloud 词云图,显示主要的高频词这种方式,非常方便。
使用wordcloud可以指定使用的字体, 在windows中, 字体在以下的文件夹中: C:\Windows\Fonts, 可以将其中的字体文件拷贝到当前的文件夹内。
本文基于bilibili的logo进行词云绘制

def get_img():
bg = numpy.array(image.open('b.png'))
with open("bilibili_wc.txt", "r",encoding='utf-8') as f:
txt = f.read()
word = WordCloud(background_color="white", \
width=500, \
height=500,
font_path='simhei.ttf',
mask=bg,
).generate(txt)
word.to_file('test.png')
print("词云图片已保存")
plt.imshow(word)
plt.axis("off")
plt.show()
成果展示
if __name__ == '__main__':
get_text()
get_wc()
get_img()

需要弹幕数据和源码的同学
评论区评论【张三】获取
我是一条,一个在互联网摸爬滚打的程序员。
道阻且长,行则将至。
大家的 【点赞,收藏,关注】 就是一条创作的最大动力,我们下期见!
注:关于本篇博客有任何问题和建议,欢迎大家留言!
cs